Way back in June, in Replacing Python: second round, I wrote:
The big surprise for me in these tests was how little you lose going from Python to OCaml.
Of course, I was mainly focused on making sure the things I needed were still available. With the port now complete (0install 2.6 has been released, and contains no Python code), here's a summary of the main things you gain.
Table of Contents
- Functional programming
- Type-checking
- Data type definitions
- Polymorphic variants
- Immutability
- Abstraction
- Speed
- No dependency cycles
- GUI code
- API stability
- Summary
This post also appeared on Hacker News and Reddit, where there are more comments.
( This post is part of a series in which I converted 0install from Python to OCaml, learning OCaml in the process. The full code is at GitHub/0install. )
A note on bias
I started these blog posts unemployed (taking a career break), with no particular connection to any of the languages, and motivated to make a good choice since I'd be using it a lot. I wasn't biased towards OCaml; it wasn't even on my list of candidates until a complete stranger suggested it on the mailing list. But I must now disclose that, since my last blog post, I'm now getting paid for writing OCaml.
Functional programming
Some people commented it was good to see more projects moving to functional programming. So, what's it like doing functional programming after Python? To be honest, not much has changed. According to OCaml's What is functional programming?, "In a functional language, functions are first-class citizens" and "The fact is that Perl is actually quite a good functional language".
So, if you've ever used Python's (built-in) map, reduce, filter or apply functions, ever written or used a decorator or ever passed a function as an argument to another function, you're already doing functional programming as far as OCaml is concerned. By contrast, "pure functional programming" (as in Haskell) would be a major change.
OCaml does make partially applying functions easier, which is sometimes convenient, and it supports tail recursion. Tail recursion allows you to write loops in a functional style (without needing break, continue or mutable state). That can make it easier to reason about loops, but I couldn't find any examples in 0install where this style was clearly better than a plain Python loop.
Type-checking
I've used statically-typed languages before (I used to program in Java for my day job). That can catch many errors that Python would miss, but OCaml's type system is far more useful than Java's. Here's an example, where we want to display an icon for some program in the GUI:
1 2 | |
Error: This expression has type Icon.t -> unit
but an expression was expected of type Icon.t option -> 'a
Oops. The program might not have an icon (icons are optional). We'll need to use a default one in that case:
1 2 3 | |
Downloading some data:
1 2 3 4 | |
Warning 8: this pattern-matching is not exhaustive.
Here is an example of a value that is not matched:
`aborted_by_user
Oops. The user might click the "Cancel" button - we need to handle that too:
1 2 3 4 | |
When registering an extra feed to an interface we want to download it first to check it exists:
1 2 3 | |
Error: This expression has type feed_url
but an expression was expected of type [< `remote_feed of url ]
The second variant type does not allow tag(s) `local_feed
Oops. The user might specify a local file too:
1 2 3 4 5 | |
Java makes you do all the work for static type checking, but manages to miss many of the benefits.
No matter how much care you take with your Java types, there's always a good chance you're going to crash with a NullPointerException.
By requiring correct handling of None (null) and ensuring pattern matching is exhaustive, OCaml's type checking is far more useful. As with Haskell, when a piece of OCaml code compiles successfully, there's a very good chance it will work first time.
And, of course, static checking makes refactoring much easier than in Python. For example, if you remove or rename something, the compiler will always find every place you need to update.
Data type definitions
OCaml makes it really easy to define new data types as you need them. The types are always easy to see, and you know that OCaml will enforce them (unlike comments in Python, which may be incorrect). Here's a record type for the configuration settings for an interface (an optional stability level and a list of extra feeds):
1 2 3 4 | |
And here's a variant (enum / tagged union / sum) type for the result of a download:
1 2 3 4 | |
Polymorphic variants
The OCaml labels tutorial describes polymorphic variants as a way to use the same name (e.g. Open) for different things (e.g. opening a door vs opening a lock) and says:
"Because of the reduction in type safety, it is recommended that you don't use these in your code".
This is quite misleading (and I was quickly corrected when I repeated it). Their real purpose is to support subsets and supersets, which are useful all over the place. Some examples:
-
The "0install" command-line parser accepts a large number of options. The "0install run" subcommand accepts a subset of these. That subset can be further subdivided into common options (present in all commands, such as
--verbose), options common to selection commands (e.g.--before=VERSION) and those specific to "0install run" (e.g.--wrapper=COMMAND). -
The GUI code that handles dialog responses (
OK,Cancel, etc) must handle the union of all the action button responses it added and the always-present window close icon. -
The download code only handles the subset of feed URLs that represent remote resources.
-
Users can only register local and remote feeds to an interface, not distribution-provided virtual feeds.
-
Cached feeds contain only remote implementations, local feeds contain local and remote implementations, and distribution feeds contain only distribution implementations. All three types get combined together and passed to the solver.
Here's an example, showing the run command dividing its options into sub-groups, with the compiler checking that every option will be handled in all cases:
1 2 3 4 5 6 7 | |
Without polymorphic variants, OCaml's exhaustive matching requirements mean you'd have to provide code to handle cases that (you think) can't happen. That's tedious and your program will crash if you get it wrong. Polymorphic variants mean you can prove to the compiler that only the correct subset needs to be handled at each point in the code. This is fantastic, and I can't think of any other major language that does this (though I'm sure people will suggest some in the comments).
Immutability
In OCaml, all variables and record fields are immutable by default. This is far saner than Java (where the default is mutable and you must use final everywhere to override it). Immutable is a better default because:
- Typically, you want most things to be immutable (in any language).
- If you forget to mark something as mutable, the compiler will quickly let you know, whereas forgetting to mark something as immutable would be missed.
With mutable structures, you are always worrying about whether one piece of code will mutate a structure that another is relying on. For example, I originally made the XML element type mutable, but I found I was writing comments like this:
1 2 | |
After removing the mutable annotations from the element declaration, the compiler showed me each piece of code I needed to modify to make it work again. Then, I was able to remove those notes.
[ The main difficulty in this conversion was handling XML namespace prefixes. Previously, each element had a reference to its owning document, which held a shared (mutable) pool of prefix bindings. Now, each namespaced item holds its preferred prefix, and the output code builds up a set of bindings before writing out the tree. ]
There is one case where Python and Java do better than OCaml: OCaml strings are mutable! The convention is to treat them as immutable, though.
Update: OCaml 4.02 has an option for immutable strings, with a separate Bytes.t for mutable byte arrays.
Abstraction
OCaml makes it very easy to hide a module's implementation details from its users using abstract types.
I gave one example in the bugs post, where hiding the fact that a sorted tree is really the same type as an unsorted one prevents bugs due to mixing them up.
Here's another example. In the Python code, we would parse a selections XML document into a Selections object, like this:
1 2 3 | |
I found all this parsing and serialising complicated things and so in the OCaml rewrite I decided to use the plain XML element type everywhere.
That did simplify things, but it also removed some safety and clarity from the APIs.
Consider the Selections.create function (which now does nothing unless the document is in an old format and needs to be upgraded):
1 2 3 4 | |
It's nice and simple, but it just returns an element. It would be easy to pass some other XML element to a function that only works on selection documents (or to pass a document that's still in the old format).
We can solve this simply by declaring an abstract type for selection documents in the interface file (selections.mli):
1 2 | |
(note: it's an OCaml convention for a module's main type to be called t; other modules will refer to this type as Selections.t)
I think this gets the best of both worlds. Internally, a selections object is just the XML root element, which is simple and efficient, but code using it can't mix up the types. And, of course, we can change the internal type later if needed without breaking anything.
This isn't a particularly novel idea (you can do something similar in C). However, Python and Java would require you to write a wrapper object around the object you want to hide, and Python makes it easy for users of the API to access the internal representation even then. If you're writing a library, OCaml (like C) makes it clear when you're changing the module's interface vs merely changing its implementation.
( There is another interesting feature, which I haven't used yet: you can use the "private" modifier to say that users of the module can see the structure of the type but can't create their own instances of it. For example, saying type t = private element would allow users to cast a selections value to an XML element, but not to treat any old XML as a selections value. )
I did experience one case where abstraction didn't work as intended. In the SAT solver, I declared the type of a literal abstractly as type lit and, internally, I used type lit = int (an array index). That worked fine. Later, I changed the internal representation from an int to a record. Ideally, that would have no effect on users of the module, but OCaml allows testing abstract types for equality, which resulted in each comparison recursively exploring the whole SAT problem. It can also cause runtime crashes if it encounters a function in this traversal. Haskell's type classes avoid this problem by letting you control which types can be compared and how the comparison should be done.
Speed
Python is well known for being slow, but much of what real programs do is simply calling C libraries. For example, when calculating a SHA256 digest, C does all the heavy lifting.
Despite this, I've found OCaml to be fairly consistently 10 times faster in macro benchmarks (measuring a complete run of 0install from start to finish). Also, although I've added a lot of code and dependencies since the initial benchmarks, it still runs almost as quickly. The 0release benchmark took 8ms with June's minimal version, compared to 10ms with the final version.
When doing pure calculations (e.g. a tight loop adding integers), OCaml is typically more than 100x faster than Python.
Even so, OCaml is probably not a great choice for CPU-intensive programs. Like Python, it has a global lock, so you can't have multiple threads all using the CPU at once. But if you're writing small utilities that need to run quickly, it's perfect.
Update: There is a multicore OCaml branch under development which removes the global lock.
No dependency cycles
Perhaps I'm making a virtue of a flaw here, but I like the fact that OCaml doesn't allow cyclic dependencies between source files. I think this leads to cleaner code (back when I was writing Java, I wrote a script to extract all module dependencies and graph them so I could find and eliminate cycles).
What this means is that in any OCaml code-base, no matter how complex, there's always at least one module that doesn't depend on any of the others and which you can therefore read first. Then there's a second module that only depends on the first one, etc. For example, here are the modules that make up 0install's GTK plugin (note the lack of cycles):
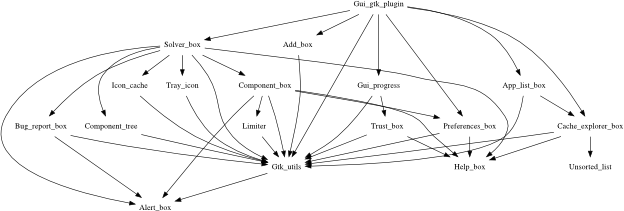
Cycles can be a problem when converting existing code to OCaml, though. For example, the Python had a helpers.py module containing various high-level helper functions (e.g. get_selections_gui to run the GUI and return the user's selections, and ensure_cached to make sure some selections are cached and download them if not). That doesn't work in OCaml, because the helpers module depends on the GUI, but the GUI also depends on the helpers (the GUI sometimes needs to ensure things are cached). The result is that I had to move each helper function to the module it uses, but I don't mind because the result is a clearer API.
Another example is the Config object. When I started the Python code back in 2005, I was very excited about using the idea of dependency injection for connecting together software modules (this is the basis of how 0install runs programs). Yet, for some reason I can't explain, it didn't occur to me to use a dependency injection style within the code. Instead, I made a load of singleton objects. Later, in an attempt to make things more testable, I moved all the singletons to a Config object and passed that around everywhere. I wasn't proud of this design even at the time, but it was the simplest way forward. It looked like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
OCaml really didn't like this design! config.py depends on all the other modules because it calls their constructors, while they all depend on it to get their dependencies.
Note that this design isn't very safe: Fetcher's constructor could ask for config.trust_mgr, and TrustMgr's constructor could ask for config.fetcher. In Python, we have to remember not to do that, but in OCaml we'd like the type checker to prove it can't happen.
In most places, I fixed this by passing to each constructor just the objects it actually needs, which is cleaner.
Another approach, which I used when lots of objects were needed, is that instead of requiring a config object, a class can take simply "an object with at least fetcher and trust_mgr methods".
Then we know statically that it will only call those methods, even though we actually give it the full config object.
The result of all this is that you can look at e.g. the fetch.mli interface file and see exactly which other modules it depends on, none of which will depend on it.
GUI code
Converting the GTK GUI to OCaml (using the LablGtk bindings), I replaced 5166 lines of Python (plus 1736 lines of GtkBuilder XML) with 4017 lines of OCaml (and no XML). I'm not sure why, but writing GTK code in OCaml just seems to be much easier than with Python.
I used GtkBuilder in the Python code in the hope that it would make it easier to modify the layouts, and to improve reliability (since the XML should always be valid, whereas Python code might not be). However, it actually made things harder because Glade (the editor) is constantly trying to force you to upgrade to the latest (incompatible) XML syntax, and I ended up having to run an old OS in a VM any time I wanted to edit things.
In the OCaml, the static type checking gives us similar confidence that the layout code won't crash. Also, with GtkBuilder you name each widget in the XML and then search for these names in the code. If they don't match, it will fail at runtime. Having everything in OCaml meant that couldn't happen. [ Note: I later discovered that LablGtk doesn't support GtkBuilder anyway. ]
Here's an example of some OCaml GTK code and the corresponding Python code. This shows how to build and display a menu (simplified to have just one item):
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 | |
Some points to note:
- LablGtk allows you to specify many properties at once in the constructor call, whereas in PyGTK we need separate calls for each.
- The Python API broke between Python 2 and Python 3, so we have to make sure to use the right one. It's not sufficient to test the Python code using only one version of Python!
- The Python bindings have always suffered from garbage collection bugs. If we don't store
menuin a global variable, it may garbage collect the menu while the user is still choosing - this makes the menu disappear suddenly from the screen! - Actually, I see that Python's
MenuItemtakes alabelargument, so maybe I could save a line. Or maybe that doesn't work on some older version. It's not worth the risk of changing it.
Update: I used the original layout for the OCaml above as I was comparing line counts, but it's a bit wide for this narrow blog and some people are finding it hard to read. Here's an expanded version which uses less special syntax:
1 2 3 4 5 6 7 8 | |
Here, ~ indicates a named argument and # is a method call. So menu_item ~packing:menu#add ... is like menu_item(packing = menu.add, ...) in Python.
However, I did still have a few problems with the OCaml GTK bindings:
- There's no support for custom cell renderers. I used three of these in the Python version and had to find alternative UIs for each.
- Various minor functions aren't included for some reason. The ones I wanted but couldn't find were
Dialog.add_action_widget,Style.paint_arrow,MessageDialog.BUTTONS_NONE,Dialog.set_keep_above,icon_size_lookupandSelection_data.get_uris. - I had to work around a bug in the IconView support (reported
but with no responseand fixed immediately, although the bug report wasn't updated). - You usually don't need the result of creating a label or attaching a signal so you need to use
ignore, which can cause silent failures if you forgot an argument (it will ignore the partial function rather than the widget or signal result). Probably I should makeignore_signalandignore_widgetutility functions.
Update: I did add ignore_widget, but for signals I found a better solution: I created a new ==> operator to connect a signal and ignore the resulting signal ID. It's used like this:
1
| |
API stability
This is a community thing rather than a language issue, but OCaml and OCaml libraries seem to be very good at maintaining backwards compatibility at the source level. 0install supports the old OCaml 3.12 and libraries in Ubuntu 12.04 up to the latest OCaml 4.01 release without any problems. The only use of conditional compilation for compatibility is that we don't define the |> operator on 4.01 because it's already a built-in (this avoids a warning).
On the other hand, binary compatibility is very poor. You can replace the implementation of a module with a newer version as long as the public interface doesn't change (good), but any change at all to the interface requires everything that depends on it to be recompiled, and then everything that depends on them, and so on.
For example, if the List module adds a new function then the signature of the List module changes. Now any program using the new version of the List module is incompatible with every library binary compiled against the old version. Even if nothing is even using the new function! This means that distributing OCaml libraries in binary form is effectively impossible.
Summary
OCaml's main strengths are correctness and speed. Its type checking is very good at catching errors, and its "polymorphic variants" are a particularly useful feature, which I haven't seen in other languages. Separate module interface files, abstract types, cycle-free dependencies, and data structures that are immutable by default help to make clean APIs.
Surprisingly, writing GTK GUI code in OCaml was easier than in Python. The resulting code was significantly shorter and, I suspect, will prove far more reliable. OCaml's type checking is particularly welcome here, as GUI code is often difficult to unit-test.
The OCaml community is very good at maintaining API stability, allowing the same code to compile on old and new systems and (hopefully) minimising time spent updating it later.