Thomas Leonard's blog2023-04-26T10:00:00+00:00https://roscidus.com/blog/Thomas LeonardLambda Capabilities2023-04-26T10:00:00+00:00https://roscidus.com/blog/blog/2023/04/26/lambda-capabilities"Is this software safe?" is a question software engineers should be able to answer,
but doing so can be difficult.
Capabilities offer an elegant solution, but seem to be little known among functional programmers.
This post is an introduction to capabilities in the context of ordinary programming
(using plain functions, in the style of the lambda calculus).
Even if you're not interested in security,
capabilities provide a useful way to understand programs;
when trying to track down buggy behaviour,
it's very useful to know that some component couldn't have been the problem.
We have some application (for example, a web-server) that we want to run.
The application is many thousands of lines long and depends on dozens of third-party libraries,
which get updated on a regular basis.
I would like to be able to check, quickly and easily, that the application cannot do any of these things:
Delete my files.
Append a line to my ~/.ssh/authorized_keys file.
Act as a relay, allowing remote machines to attack other computers on my local network.
Send telemetry to a third-party.
Anything else bad that I forget to think about.
For example, here are some of the OCaml packages I use just to generate this blog:
Having to read every line of every version of each of these packages in order to decide whether it's safe
to generate the blog clearly isn't practical.
I'll start by looking at traditional solutions to this problem, using e.g. containers or VMs,
and then show how to do better using capabilities.
Option 1: Security as a separate concern
A common approach to access control treats securing software as a separate activity to writing it.
Programmers write (insecure) software, and a security team writes a policy saying what it can do.
Examples include firewalls, containers, virtual machines, seccomp policies, SELinux and AppArmor.
The great advantage of these schemes is that security can be applied after the software is written, treating it as a black box.
However, it comes with many problems:
Confused deputy problem
Some actions are OK for one use but not for another.
For example, if the client of a web-server requests https://example.com/../../etc/httpd/server-key.pem
then we don't want the server to read this file and send it to them.
But the server does need to read this file for other reasons, so the policy must allow it.
Coarse-grained controls
All the modules making up the program are treated the same way,
even though you probably trust some more than others.
For example, we might trust the TLS implementation with the server's private key, but not the templating engine,
and I know the modules I wrote myself are not malicious.
Even well-typed programs go wrong
Programming in a language with static types is supposed to ensure that if the program compiles then it won't crash.
But the security policy can cause the program to fail even though it passed the compiler's checks.
For example, the server might sometimes need to send an email notification.
If it didn't do that while the security policy was being written, then that will be blocked.
Or perhaps the web-server didn't even have a notification system when the policy was written,
but has since been updated.
Policy language limitations
The security configuration is written in a new language, which must be learned.
It's usually not worth learning this just for one program,
so the people who write the program struggle to write the policy.
Also, the policy language often cannot express the desired policy,
since it may depend on concepts unique to the program
(e.g. controlling access based on a web-app user's ID, rather than local Unix user ID).
All of the above problems stem from trying to separate security from the code.
If the code were fully correct, we wouldn't need the security layer.
Checking that code is fully correct is hard,
but maybe there are easy ways to check automatically that it does at least satisfy our security requirements...
Option 2: Purity
One way to prevent programs from performing unwanted actions is to prevent all actions.
In pure functional languages, such as Haskell, the only way to interact with the outside world is to return the action you want to perform from main. For example:
12345
f::Int->Stringfx=...main::IO()main=putStr(f42)
Even if we don't look at the code of f, we can be sure it only returns a String and performs no other actions
(assuming Safe Haskell is being used).
Assuming we trust putStr, we can be sure this program will only output a string to stdout and not perform any other actions.
However, writing only pure code is quite limiting. Also, we still need to audit all IO code.
Option 3: Capabilities
Consider this code (written in a small OCaml-like functional language, where ref n allocates a new memory location
initially containing n, and !x reads the current value of x):
Can we be sure that the assert won't fail, without knowing the definition of f?
Assuming the language doesn't provide unsafe backdoors (such as OCaml's Obj.magic), we can.
f x cannot change y, because f x does not have access to y.
So here is an access control system, built in to the lambda calculus itself!
At first glance this might not look very promising.
For example, while f doesn't have access to y, it does have access to any global variables defined before f.
It also, typically, has access to the file-system and network,
which are effectively globals too.
To make this useful, we ban global variables.
Then any top-level function like f can only access things passed to it explicitly as arguments.
Avoiding global variables is usually considered good practise, and some systems ban them for other reasons anyway
(for example, Rust doesn't allow global mutable state as it wouldn't be able to prevent races accessing it from multiple threads).
Returning to the Haskell example above (but now in OCaml syntax),
it looks like this in our capability system:
123
letfx=...letmainch=output_stringch(f42)
Since f is a top-level function, we know it does not close over any mutable state, and our 42 argument is pure data.
Therefore, the call f 42 does not have access to, and therefore cannot affect,
any pre-existing state (including the filesystem).
Internally, it can use mutation (creating arrays, etc),
but it has nowhere to store any mutable values and so they will get GC'd after it returns.
f therefore appears as a pure function, and calling it multiple times will always give the same result,
just as in the Haskell version.
output_string is also a top-level function, closing over no mutable state.
However, the function resulting from evaluating output_string ch is not top-level,
and without knowing anything more about it we should assume it has full access to the output channel ch.
If main is invoked with standard output as its argument, it may output a message to it,
but cannot affect other pre-existing state.
In this way, we can reason about the pure parts of our code as easily as with Haskell,
but we can also reason about the parts with side-effects.
Haskell's purity is just a special case of a more general rule:
the effects of a (top-level) function are bounded by its arguments.
Attenuation
So far, we've been thinking about what values are reachable through other values.
For example, the set of ref-cells that can be modified by f x is bounded by
the union of the set of ref cells reachable from the closure f
with the set of ref cells reachable from x.
One powerful aspect of capabilities is that we can use functions to implement whatever access controls we want.
For example, let's say we only want f to be able to set the ref-cell, but not read it.
We can just pass it a suitable function:
12345
letx=ref0inletsetv=x:=vinfset
Or perhaps we only want to allow inserting positive integers:
Or log each time it is used, tagged with a label that's meaningful to us
(e.g. the function to which we granted access):
12345678
letlog=ref[]inletsetnamev=letmsg=sprintf"%S set it to %d"namevinlog:=msg::!log;setvinf(set"f");g(set"g")
Or all of the above.
In these examples, our function f never got direct access (permission) to x, yet was still able to affect it.
Therefore, in capability systems people often talk about "authority" rather than permission.
Roughly speaking, the authority of a subject is the set of actions that the subject could cause to happen,
now or in the future, on currently-existing resources.
Since it's only things that might happen, and we don't want to read all the code to find out exactly what
it might do, we're usually only interested in getting an upper-bound on a subject's authority,
to show that it can't do something.
The examples here all used a single function.
We may want to allow multiple operations on a single value (e.g. getting and setting a ref-cell),
and the usual techniques are available for doing that (e.g. having the function take the operation as its first argument,
or collecting separate functions together in a record, module or object).
Web-server example
Let's look at a more realistic example.
Here's a simple web-server (we are defining the main function, which takes two arguments):
12
letmainnethtdocs=...
To use it, we pass it access to some network (net) and a directory tree with the content (htdocs).
Immediately we can see that this server does not access any part of the file-system outside of htdocs,
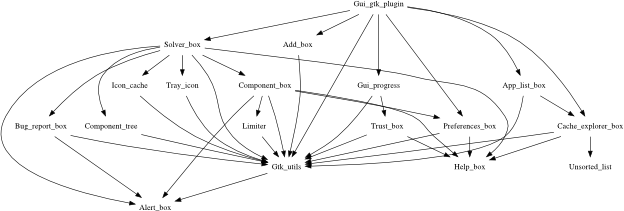
but that it may use the network. Here's a picture of the situation:
Initial reference graph
Notes on reading the diagram:
The diagram shows a model of the reference graph, where each node represents some value (function, record, tuple, etc)
or aggregated group of values.
An arrow from A to B indicates the possibility that some value in the group A holds a reference to
some value in the group B.
The model is typically an over-approximation, so the lack of an arrow from A to B means that no such reference
exists, while the presence of an arrow just means we haven't ruled it out.
Orange nodes here represent OCaml values.
White boxes are directories.
They include all contained files and subdirectories, except those shown separately.
I've pulled out htdocs so we can see that app doesn't have access to the rest of home.
Just for emphasis, I also show .ssh separately.
I'm assuming here that a directory doesn't give access to its parent,
so htdocs can only be used to read files within that sub-tree.
net represents the network and everything else connected to it.
In most operating systems, directories exist in the kernel's address space,
and so you cannot have a direct reference to them.
That's not a problem, but for now you may find it easier to imagine a system where the kernel and applications
are all a single program, in a single programming language.
This diagram represents the state at a particular moment in time (when starting the application).
We could also calculate and show all the references that might ever come to exist,
given what we know about the behaviour of app and net.
Since we don't yet know anything about either,
we would have to assume that app might give net access to htdocs and to itself.
So, the diagram above shows the application app has been given references to net and to htdocs as arguments.
Looking at our checklist from the start:
It can't delete all my files, but it might delete the ones in htdocs.
It can't edit ~/.ssh/authorized_keys.
It might act as a relay, allowing remote machines to attack other computers on my local network.
It might send telemetry to a third-party.
We can read the body of the function to learn more:
Note: Net.listen net is typical OCaml style for performing the listen operation on net.
We could also have used a record and written net.listen instead, which may look more familiar to some readers.
Here's an updated diagram, showing the moment when Http.serve is called.
The app group has been opened to show socket and handler separately:
After reading the code of main
We can see that the code in the HTTP library can only access the network via socket,
and can only access htdocs by using handler.
Assuming Net.listen is trust-worthy (we'll normally trust the platform's networking layer),
it's clear that the application doesn't make out-bound connections,
since net is used only to create a listening socket.
To know what the application might do to htdocs, we only have to read the definition of static_files:
We see that handle_connection has no way to share telemetry information between connections,
given that handle_request never stores anything.
We can tell these things after only looking at the code for a few seconds, even though dozens of libraries are being used.
In particular, we didn't have to read handle_connection or any of the HTTP parsing logic.
Now let's enable TLS. For this, we will require a configuration directory containing the server's key:
OCaml syntax note: I used ~ to make tls_config a named argument; we wouldn't want to get this directory confused with htdocs!
We can see that only the TLS library gets access to the key.
The HTTP library interacts only with the TLS socket, which presumably does not reveal it.
Updated graph showing TLS
Notice too how this fixes the problem we had with our original policy enforcement system.
There, an attacker could request https://example.com/../tls_config/server.key and the HTTP server might send the key.
But here, the handler cannot do that even if it wants to.
When handler loads a file, it does so via htdocs, which does not have access to tls_config.
The above server has pretty good security properties,
even though we didn't make any special effort to write secure code.
Security-conscious programmers will try to wrap powerful capabilities (like net)
with less powerful ones (like socket) as early as possible, making the code easier to understand.
A programmer uninterested in readability is likely to mix in more irrelevant code you have to skip through,
but even so it shouldn't take too long to track down where things like net and htdocs end up.
And even if they spread them throughout their entire application,
at least you avoid having to read all the libraries too!
By contrast, consider a more traditional (non-capability) style.
We start with:
1
letmainhtdocs=...
Here, htdocs would be a plain string rather than a reference to a directory,
and the network would be reached through a global.
We can't tell anything about what this server could do from looking at this one line,
and even if we expand it, we won't be able to tell what all the functions it calls do, either.
We will end up having to follow every function call recursively through all of the server's
dependencies, and our analysis will be out of date as soon as any of them changes.
Use at different scales
We've seen that we can create an over-approximation of the reference graph by looking at just a small part of the code,
and then get a closer bound on the possible effects as needed
by expanding groups of values until we can prove the desired property.
For example, to prove that the application didn't modify htdocs, we followed htdocs by expanding main and then static_files.
Within a single process, a capability is a reference (pointer) to another value in the process's memory.
However, the diagrams also included arrows (capabilities) to things outside of the process, such as directories.
We can regard these as references to privileged proxy functions in the process that make calls to the OS kernel,
or (at a higher level of abstraction) we can consider them to be capabilities to the external resources themselves.
It is possible to build capability operating systems (in fact, this was the first use of capabilities).
Just as we needed to ban global variables to make a safe programming language,
we need to ban global namespaces to make a capability operating system.
For example, on FreeBSD this is done (on a per-process basis) by invoking the cap_enter system call.
We can zoom out even further, and consider a network of computers.
Here, an arrow between machines represents some kind of (unforgeable) network address or connection.
At the IP level, any process can connect to any address, but a capability system can be implemented on top.
CapTP (the Capability Transport Protocol) was an early system for this, but
Cap'n Proto (Capabilities and Protocols) is the modern way to do it.
So, thinking in terms of capabilities, we can zoom out to look at the security properties of the whole network,
yet still be able to expand groups as needed right down to the level of individual closures in a process.
Key points
Library code can be imported and called without it getting access to any pre-existing state,
except that given to it explicitly. There is no "ambient authority" available to the library.
A function's side-effects are bounded by its arguments.
We can understand (get a bound on) the behaviour of a function call just by looking at it.
If a has access to b and to c, then a can introduce them (e.g. by performing the function call b c).
Note that there is no capability equivalent to making something "world readable";
to perform an introduction,
you need access to both the resource being granted and to the recipient ("only connectivity begets connectivity").
Instead of passing the name of a resource, we pass a capability reference (pointer) to it,
thereby proving that we have access to it and sharing that access ("no designation without authority").
The caller of a function decides what it should access, and can provide restricted access by wrapping
another capability, or substituting something else entirely.
I am sometimes unable to install a messaging app on my phone because it requires me to grant it
access to my address book.
A capability system should never say "This application requires access to the address book. Continue?";
it should say "This application requires access to an address book; which would you like to use?".
A capability must behave the same way regardless of who uses it.
When we do f x, f can perform exactly the same operations on x that we can.
It is tempting to add a traditional policy language alongside capabilities for "extra security",
saying e.g. "f cannot write to x, even if it has a reference to it".
However, apart from being complicated and annoying,
this creates an incentive for f to smuggle x to another context with more powers.
This is the root cause of many real-world attacks, such as click-jacking or cross-site request forgery,
where a URL permits an attack if a victim visits it, but not if the attacker does.
One of the great benefits of capability systems is that you don't need to worry that someone is trying to trick you
into doing something that you can do but they can't,
because your ability to access the resource they give you comes entirely from them in the first place.
All of the above follow naturally from using functions in the usual way, while avoiding global variables.
Practical considerations
The above discussion argues that capabilities would have been a good way to build systems in an ideal world.
But given that most current operating systems and programming languages have not been designed this way,
how useful is this approach?
I'm currently working on Eio, an IO library for OCaml, and using these principles to guide the design.
Here are a few thoughts about applying capabilities to a real system.
Plumbing capabilities everywhere
A lot of people worry about cluttering up their code by having to pass things explicitly everywhere.
This is actually not much of a problem, for a couple of reasons:
We already do this with most things anyway.
If your program uses a database, you probably establish a connection to it at the start and pass the connection around as needed.
You probably also pass around open file handles, configuration settings, HTTP connection pools, arrays, queues, ref-cells, etc.
Handling "the file-system" and "the network" the same way as everything else isn't a big deal.
You can often bundle up a capability with something else.
For example, a web-server will likely let the user decide which directory to serve,
so you're already passing around a pathname argument.
Passing a path capability instead is no extra work.
Consider a request handler that takes the address of a Redis server:
1
Http.servesocket(handle_requestredis_url)
It might seem that by using capabilities we'd need to pass the network in here too:
1
Http.servesocket(handle_requestnetredis_url)
This is both messy and unnecessary.
Instead, handle_request can take a function for connecting to Redis:
1
Http.servesocket(handle_requestredis)
Then there is only one argument to pass around again.
Instead of writing the connection logic in handle_request, we write the same logic outside and just pass in the function.
And now someone looking at the code can see "the handler can connect to Redis",
rather than the less precise "the handler accesses the network".
Of course, if Redis required more than one configuration setting then you'd probably already be doing it this way.
The main problematic case is providing defaults.
For example, a TLS library might allow us to specify the location of the system's certificate store,
but it would like to provide a default (e.g. /etc/ssl/certs/).
This is particularly important if the default location varies by platform.
If the TLS library decides the location, then we must give it (read-only at least) access to the whole system!
We may just decide to trust the library, or we might separate out the default paths into a trusted package.
Levels of support
Ideally, our programming language would provide a secure implementation of capabilities that we could depend on.
That would allow running untrusted code safely and protect us from compromised packages.
However, converting a non-capability language to a capability-secure one isn't easy,
and isn't likely to happen any time soon for OCaml
(but see Emily for an old proof-of-concept).
Even without that, though, capabilities help to protect non-malicious code from malicious inputs.
For example, the request handler above forgot to sanitise the URL path from the remote client,
but it still can't access anything outside of htdocs.
And even if we don't care about security at all, capabilities make it easy to see what a program does;
they make it easy to test programs by replacing OS resources with mocks;
and preventing access to globals helps to avoid race conditions,
since two functions that access the same resource must be explicitly introduced.
Running on a traditional OS
A capability OS would let us run a program's main function and provide the capabilities it wanted directly,
but most systems don't work like that.
Instead, each program requires a small trusted entrypoint that has the full privileges of the process.
In Eio, an application will typically start something like this:
Eio_main.run starts the Eio event loop and then runs the callback.
The env argument gives full access to the process's environment.
Here, the callback extracts network and filesystem access from this,
gets access to just "/srv/www" from fs,
and then calls the main function as before.
Note that Eio_main.run itself is not a capability-safe function (it magics up env from nothing).
A capability-enforcing compiler would flag this bit up as needing to be audited manually.
Use with existing security mechanisms
Maybe you're not convinced by all this capability stuff.
Traditional security systems are more widely available, better tested, and approved by your employer,
and you want to use that instead.
Still, to write the policy, you're going to need a list of resources the program might access.
Looking at the above code, we can immediately see that the policy need allow access only to the "/srv/www" directory,
and so we could call e.g. unveil here.
And if main later changes to use TLS,
the type-checker will let us know to update this code to provide the TLS configuration
and we'll know to update the policy at the same time.
If you want to drop privileges, such a program also makes it easy to see when it's safe to do that.
For example, looking at main we can see that net is never used after creating the socket,
so we don't need the bind system call after that,
and we never need connect.
We know, for instance, that this program isn't hiding an XML parser that needs to download schema files to validate documents.
Thread-local storage
In addition to global and local variables, systems often allow us to attach data to threads as a sort of middle ground.
This could allow unexpected interactions. For example:
123
letx=ref0infx;g()
Here, we'd expect that g doesn't have access to x, but f could pass it using thread-local storage.
To prevent that, Eio instead provides Fiber.with_binding,
which runs a function with a binding but then puts things back how they were before returning,
so f can't make changes that are still active when g runs.
This also allows people who don't want capabilities to disable the whole system easily:
It looks like f () doesn't have access to anything, but in fact it can recover env and get access to everything!
However, anyone trying to understand the code will start following env from the main entrypoint
and will then see that it got put in fiber-local storage.
They then at least know that they must read all the code to understand anything about what it can do.
More usefully, this mechanism allows us to make just a few things ambiently available.
For example, we don't want to have to plumb stderr through to a function every time we want to do some printf debugging,
so it makes sense to provide a tracing function this way (and Eio does this by default).
Tracing allows all components to write debug messages, but it doesn't let them read them.
Therefore, it doesn't provide a way for components to communicate with each other.
It might be tempting to use Fiber.with_binding to restrict access to part of a program
(e.g. giving an HTTP server network access this way),
but note that this is a non-capability way to do things,
and suffers the same problems as traditional security systems,
separating designation from authority.
In particular, supposedly sandboxed code in other parts of the application
can try to escape by tricking the HTTP server part into running a callback function for them.
But fiber local storage is fine for things to which you don't care to restrict access.
Symlinks
Symlinks are a bit of a pain! If I have a capability reference to a directory, it's useful to know that I can only access things beneath that directory. But the directory may contain a symlink that points elsewhere.
One option would be to say that a symlink is a capability itself, but this means that you could only create symlinks to things you can access yourself, and this is quite a restriction. For example, you might be forbidden from extracting a tarball because tar didn't have permission to the target of a symlink it wanted to create.
The other option is to say that symlinks are just strings, and it's up to the user to interpret them.
This is the approach FreeBSD uses. When you use a system call like openat,
you pass a capability to a base directory and a string path relative to that.
In the case of our web-server, we'd use a capability for htdocs, but use strings to reference things inside it, allowing the server to follow symlinks within that sub-tree, but not outside.
The main problem is that it makes the API a bit confusing. Consider:
1
save_to(htdocs/"uploads")
It might look like save_to is only getting access to the "uploads" directory,
but in Eio it actually gets access to the whole of htdocs.
If you want to restrict access, you have to do that explicitly
(as we did when creating htdocs from fs).
The advantage, however, is that we don't break software that relies on symlinks.
Also, restricting access is quite expensive on some systems (FreeBSD has the handy O_BENEATH open flag,
and Linux has RESOLVE_BENEATH, but not all systems provide this), so might not be a good default.
I'm not completely satisfied with the current API, though.
Time and randomness
It is also possible to use capabilities to restrict access to time and randomness.
The security benefits here are less clear.
Tracking access to time can be useful in preventing side-channel attacks that depend on measuring time accurately,
but controlling access to randomness makes it difficult to e.g. randomise hash functions to
help prevent denial-of-service-attacks.
However, controlling access to these does have the advantage of making code deterministic by default,
which is a great benefit, especially for expect-style testing.
Your top level test function is called with no arguments, and therefore has no access to non-determinism,
instead creating deterministic mocks to use with the code under test.
You can then just record a good trace of a test's operations and check that it doesn't change.
Power boxes
Interactive applications that load and save files present a small problem:
since the user might load or save anywhere, it seems they need access to the whole file-system.
The solution is a "powerbox".
The powerbox has access to the file-system and the rest of the application only has access to the powerbox.
When the application wants to save a file, it asks the powerbox, which pops up a GUI asking the user to choose the location.
Then it opens the file and passes that back to the application.
Conclusions
Currently-popular security mechanisms are complex and have many shortcomings.
Yet, the lambda calculus already contains an excellent security mechanism,
and making use of it requires little more than avoiding global variables.
This is known as "capability-based security".
The word "capabilities" has also been used for several unrelated concepts (such as "POSIX capabilities"),
and for clarity much of the community rebranded a while back as "Object Capabilities",
but this can make it seem irrelevant to functional programmers.
In fact, I wrote this blog post because several OCaml programmers have asked me what the point of capabilities is.
I was expecting it to be quite short (basically: applying functions to arguments good, global variables bad),
but it's got quite long; it seems there is a fair bit that follows from this simple idea!
Instead of seeing security as an extra layer that runs separately from the code and tries to guess what it meant to do,
capabilities fit naturally into the language.
The key difference with traditional security is that
the ability to do something depends on the reference used to do it, not on the identity of the caller.
This way of thinking about security works not only for controlling access to resources within a single program,
but also for controlling interactions between processes running on a machine, and between machines on a network.
We can group together resources and zoom out to see the overall picture, or expand groups to zoom in and get a closer
bound on the behaviour.
Even ignoring security, a key question is: what can a function do?
Should a function call be able to do anything at all that the process can do,
or should its behaviour be bounded in some way that is obvious just by looking at it?
If we say that you must read the source code of a function to see what it does, then this applies recursively:
we must also read all the functions that it calls, and so on.
To understand the main function, we end up having to read the code of every library it uses!
]]>Isolating Xwayland in a VM2021-10-30T10:00:00+00:00https://roscidus.com/blog/blog/2021/10/30/xwaylandIn my last post, Qubes-lite with KVM and Wayland, I described setting up a Qubes-inspired Linux system that runs applications in virtual machines. A Wayland proxy running in each VM connects its applications to the host Wayland compositor over virtwl, allowing them to appear on the desktop alongside normal host applications. In this post, I extend this to support X11 applications using Xwayland.
A graphical desktop typically allows running multiple applications on a single display
(e.g. by showing each application in a separate window).
Client applications connect to a server process (usually on the same machine) and ask it to display their windows.
Until recently, this service was an X server, and applications would communicate with it using the X11 protocol.
However, on newer systems the display is managed by a Wayland compositor, using the Wayland protocol.
Many older applications haven't been updated yet.
Xwayland can be used to allow unmodified X11 applications to run in a Wayland desktop environment.
However, setting this up wasn't as easy as I'd hoped.
Ideally, Xwayland would completely isolate the Wayland compositor from needing to know anything about X11:
Fantasy Xwayland architecture
However, it doesn't work like this.
Xwayland handles X11 drawing operations, but it doesn't handle lots of other details, including window management (e.g. telling the Wayland compositor what the window title should be), copy-and-paste, and selections.
Instead, the Wayland compositor is supposed to connect back to Xwayland over the X11 protocol and act as an X11 window manager to provide the missing features:
Actual Xwayland architecture
This is a problem for several reasons:
It means that every Wayland compositor has to implement not only the new Wayland protocol, but also the old X11 protocol.
The compositor is part of the trusted computing base (it sees all your keystrokes and window contents)
and this adds a whole load of legacy code that you'd need to audit to have confidence in it.
It doesn't work when running applications in VMs,
because each VM needs its own Xwayland service and existing compositors can only manage one.
Because Wayland (unlike X11) doesn't allow applications to mess with other applications' windows,
we can't have a third-party application act as the X11 window manager.
It wouldn't have any way to ask the compositor to put Xwayland's surfaces into a window frame, because Xwayland is a separate application.
There is another way to do it, however.
As I mentioned in the last post,
I already had to write a Wayland proxy (wayland-proxy-virtwl) to run in each VM
and relay Wayland messages over virtwl, so I decided to extend it to handle Xwayland too.
As a bonus, the proxy can also be used even without VMs, avoiding the need for any X11 support in Wayland compositors at all.
In fact, I found that doing this avoided several bugs in Sway's built-in Xwayland support.
Sommelier already has support for this, but it doesn't work for the applications I want to use.
For example, popup menus appear in the center of the screen, text selections don't work, and it generally crashes after a few seconds (often with the error xdg_surface has never been configured).
So instead I'd been using ssh -Y vm from the host to forward X11 connections to the host's Xwayland,
managed by Sway.
That works, but it's not at all secure.
Introduction to X11
Unlike Wayland, where applications are mostly unaware of each other, X is much more collaborative.
The X server maintains a tree of windows (rectangles) and the applications manipulate it.
The root of the tree is called the root window and fills the screen.
You can see the tree using the xwininfo command, like this:
This tree shows the windows of two X11 applications, ROX-Filer and GVim,
as well as various invisible utility windows (mostly 1x1 or 10x10 pixels in size).
Applications can create, move, resize and destroy windows, draw into them, and request events from them.
The X server also allows arbitrary data to be attached to windows in properties.
You can see a window's properties with xprop. Here are some of the properties on the GVim window:
$ xprop -id 0x600002
WM_HINTS(WM_HINTS):
Client accepts input or input focus: True
Initial state is Normal State.
window id # of group leader: 0x600001
_NET_WM_WINDOW_TYPE(ATOM) = _NET_WM_WINDOW_TYPE_NORMAL
WM_NORMAL_HINTS(WM_SIZE_HINTS):
program specified minimum size: 188 by 59
program specified base size: 188 by 59
window gravity: NorthWest
WM_CLASS(STRING) = "gvim", "Gvim"
WM_NAME(STRING) = "main.ml (~/Projects/wayland/wayland-proxy-virtwl) - GVIM1"
...
The X server itself doesn't know anything about e.g. window title bars.
Instead, a window manager process connects and handles that.
A window manager is just another X11 application.
It asks to be notified when an application tries to show ("map") a window inside the root,
and when that happens it typically creates a slightly larger window (with room for the title bar, etc)
and moves the other application's window inside that.
This design gives X a lot of flexibility.
All kinds of window managers have been implemented, without needing to change the X server itself.
However, it is very bad for security. For example:
Open an xterm.
Use xwininfo to find its window ID (you need the nested child window, not the top-level one).
Run xev -id 0x80001b -event keyboard in another window (using the ID you got above).
Use sudo or similar inside xterm and enter a password.
As you type the password into xterm, you should see the characters being captured by xev.
An X application can easily spy on another application, send it synthetic events, etc.
Running Xwayland
Xwayland is a version of the xorg X server that treats Wayland as its display hardware.
If you run it as e.g. Xwayland :1 then it opens a single Wayland window corresponding to the X root window,
and you can use it as a nested desktop.
This isn't very useful, because these windows don't fit in with the rest of your desktop.
Instead, it is normally used in rootless mode, where each child of the X root window may have its own Wayland window.
$ WAYLAND_DEBUG=1 Xwayland :1 -rootless
[3991465.523] -> wl_display@1.get_registry(new id wl_registry@2)
[3991465.531] -> wl_display@1.sync(new id wl_callback@3)
...
When run this way, however, no windows actually appear.
If we run DISPLAY=:1 xterm then we see Xwayland creating some buffers, but no surfaces:
We need to run Xwayland as Xwayland :1 -rootless -wm FD, where FD is a socket we will use to speak the X11 protocol and act as a window manager.
It's a little hard to find information about Xwayland's rootless mode, because "rootless" has two separate common meanings in xorg:
Running xorg without root privileges.
Using xorg's miext/rootless extension to display application windows on some other desktop.
After a while, it became clear that Xwayland's rootless mode isn't either of these, but a third xorg feature also called "rootless".
The X11 protocol
libxcb provides C bindings to the X11 protocol, but I wanted to program in OCaml.
Luckily, the X11 protocol is well documented, and generating the messages directly didn't look any harder than binding libxcb,
so I wrote a little OCaml library to do this (ocaml-x11).
At first, I hard-coded the messages. For example, here's the code to delete a property on a window:
I'm using the cstruct syntax extension to let me define the exact layout of the message body.
Here, it generates sizeof_req, set_req_window and set_req_property automatically.
After a bit, I discovered that there are XML files in xcbproto describing the X11 protocol.
This provides a Python library for parsing the XML,
which you can use by writing a Python script for your language of choice.
For example, this glorious 3394 line Python script
generates the C bindings.
After studying this script carefully, I decided that hard-coding everything wasn't so bad after all.
I ended up having to implement more messages than I expected,
including some surprising ones like OpenFont (see x11.mli for the final list).
My implementation came to 1754 lines of OCaml,
which is quite a bit shorter than the Python generator script,
so I guess I still came out ahead!
In the X11 protocol, client applications send requests and the server sends replies, errors and events.
Most requests don't produce replies, but can produce errors.
Replies and errors are returned immediately, so if you see a response to a later request, you know all previous ones succeeded.
If you care about whether a request succeeded, you may need to send a dummy message that generates a reply after it.
Since message sequence numbers are 16-bit, after sending 0xffff consecutive requests without replies,
you should send a dummy one with a reply to resynchronise
(but window management involves lots of round-trips, so this isn't likely to be a problem for us).
Events can be sent by the server at any time.
Unlike Wayland, which is very regular, X11 has various quirks.
For example, every event has a sequence number at offset 2, except for KeymapNotify.
Initialising the window manager
Using Xwayland -wm FD actually prevents any client applications from connecting at all at first,
because Xwayland then waits for the window manager to be ready before accepting any client connections.
To fix that, we need to claim ownership of the WM_S0selection.
A "selection" is something that can be owned by only one application at a time.
Selections were originally used to track ownership of the currently-selected text, and later also used for the clipboard.
WM_S0 means "Window Manager for Screen 0" (Xwayland only has one screen).
123
(* Become the window manager. This allows other clients to connect. *)let*wm_sn=internt~only_if_exists:false("WM_S"^string_of_inti)inX11.Selection.set_ownerx11~owner:(Someroot)~timestamp:`CurrentTimewm_sn
Instead of passing things like WM_S0 as strings in each request, X11 requires us to first intern the string.
This returns a unique 32-bit ID for it, which we use in future messages.
Because intern may require a round-trip to the server, it returns a promise,
and so we use let* instead of let to wait for that to resolve before continuing.
let* is defined in the Lwt.Syntax module, as an alternative to the more traditional >>= notation.
This lets our clients connect. However, Xwayland still isn't creating any Wayland surfaces.
By reading the Sommelier code and stepping through Xwayland with a debugger, I found that I needed to enable the Composite extension.
Composite was originally intended to speed up redraw operations, by having the server keep a copy of every top-level window's pixels
(even when obscured), so that when you move a window it can draw it right away without asking the application for help.
The application's drawing operations go to the window's buffer, and then the buffer is copied to the screen, either automatically by the X server
or manually by the window manager.
Xwayland reuses this mechanism, by turning each window buffer into a Wayland surface.
We just need to turn that on:
This says that every child of the root window should use this system.
Finally, we see Xwayland creating Wayland surfaces:
-> wl_compositor@5.create_surface id:+28
Now we just need to make them appear on the screen!
Windows
As usual for Wayland, we need to create a role object and attach it to the surface.
This tells Wayland whether the surface is a window or a dialog, for example, and lets us set the title, etc.
But first we have a problem: we need to know which X11 window corresponds to each Wayland surface.
For example, we need the title, which is stored in a property on the X11 window.
Xwayland does this by sending the new window a ClientMessage event of type WL_SURFACE_ID containing the Wayland ID.
We don't get this message by default, but it seems that selecting SubstructureRedirect on the root does the trick.
SubstructureRedirect is used by window managers to intercept attempts by other applications to change the children of the root window.
When an application asks the server to e.g. map a window, the server just forwards the request to the window manager.
Operations performed by the window manager itself do not get redirected, so it can just perform the same request the client wanted, or
make any changes it requires.
In our case, we don't actually need to modify the request, so we just re-perform the original map operation:
123456789
letevent_handler=object(_:X11.Event.handler)methodmap_request~window=X11.Window.mapx11windowmethodclient_message~window~tybody=ifty=wl_surface_idthen(letwayland_id=Cstruct.LE.get_uint32body0inLog.info(funf->f"X window %a corresponds to Wayland surface %ld"X11.Window.ppwindowwayland_id);pair_when_ready~x11twindowwayland_id)
Having two separate connections to Xwayland is quite annoying, because messages can arrive in any order.
We might get the X11 ClientMessage first and need to wait for the Wayland create_surface, or we might get the create_surface first
and need to wait for the ClientMessage.
An added complication is that not all Wayland surfaces correspond to X11 windows.
For example, Xwayland also creates surfaces representing cursor shapes, and these don't have X11 windows.
However, when we get the ClientMessage we can be sure that a Wayland message is on the way,
so I just pause the X11 event handling until that has arrived:
1234567891011121314
(* We got an X11 message saying X11 [window] corresponds to Wayland surface [wayland_id]. Turn [wayland_id] into an xdg_surface. If we haven't seen that surface yet, wait until it appears on the Wayland socket. *)letrecpair_when_ready~x11twindowwayland_id=matchHashtbl.find_optt.unpairedwayland_idwith|None->Log.info(funf->f"Unknown Wayland object %ld; waiting for surface to be created..."wayland_id);let*()=Lwt_condition.waitt.unpaired_addedinpair_when_ready~x11twindowwayland_id|Some{client_surface=_;host_surface;set_configured}->Log.info(funf->f"Setting up Wayland surface %ld using X11 window %a"wayland_idX11.Xid.ppwindow);Hashtbl.removet.unpairedwayland_id;Lwt.async(fun()->pairt~set_configured~host_surfacewindow);Lwt.return_unit
Another complication is that Wayland doesn't allow you to attach a buffer to a surface until the window has been "configured".
Doing so is a protocol error, and Sway will disconnect us if we try!
But Xwayland likes to attach the buffer immediately after creating the surface.
To avoid this, I use a queue:
Xwayland asks to create a surface.
We forward this to Sway, add its ID to the unpaired map, and create a queue for further events.
Xwayland asks us to attach a buffer, etc. We just queue these up.
We get the ClientMessage over the X11 connection and create a role for the new surface.
Sway sends us a configure event, confirming it's ready for the buffer.
We forward the queued events.
However, this creates a new problem: if the surface isn't a window then the events will be queued forever.
To fix that, when we get a create_surface we also do a round-trip on the X11 connection.
If the window is still unpaired when that returns then we know that no ClientMessage is coming, and we flush the queue.
X applications like to create dummy windows for various purposes (e.g. receiving clipboard data),
and we need to avoid showing those.
They're normally set as override_redirect so the window manager doesn't handle them,
but Xwayland redirects them anyway (it needs to because otherwise e.g. tooltips wouldn't appear at all).
I'm trying various heuristics to detect this, e.g. that override redirect windows with a size of 1x1 shouldn't be shown.
If Sway asks us to close a window, we need to relay that to the X application using the WM_DELETE_WINDOW protocol,
if it supports that:
Wayland defaults to using client-side decorations (where the application draws its own window decorations).
X doesn't do that, so we need to turn it off (if the Wayland compositor supports the decoration manager extension):
Dialog boxes are more of a problem.
Wayland requires every dialog box to have a parent window, but X11 doesn't.
To handle that, the proxy tracks the last window the user interacted with and uses that as a fallback parent
if an X11 window with type _NET_WM_WINDOW_TYPE_DIALOG is created without setting WM_TRANSIENT_FOR.
That could be a problem if the application closes that window, but it seems to work.
Performance
I noticed a strange problem: scrolling around in GVim had long pauses once a second or so,
corresponding to OCaml GC runs.
This was surprising, as OCaml has a fast incremental garbage collector, and is normally not a problem for interactive programs.
Besides, I'd been using the proxy with the (Wayland) Firefox and xfce4-terminal applications for 6 months without any similar problem.
Using perf showed that Linux was spending a huge amount of time in release_pages.
The problem is that Xwayland was sharing lots of short-lived memory pools with the proxy.
Each time it shares a pool, we have to ask the VM host for a chunk of memory of the same size.
We map both pools into our address space and then copy each frame across
(this is needed because we can't export guest memory to the host).
Normally, an application shares a single pool and just refers to regions within it, so we just map once at startup and unmap at exit.
But Xwayland was creating, sharing and discarding around 100 pools per second while scrolling in GVim!
Because these pools take up a lot of RAM, OCaml was (correctly) running the GC very fast, freeing them in batches of 100 or so each second.
First, I tried adding a cache of host memory, but that only solved half the problem: freeing the client pool was still slow.
Another option is to unmap the pools as soon as we get the destroy message, to spread the work out.
Annoyingly, OCaml's standard library doesn't let you free memory-mapped memory explicitly
(see the Add BigArray.Genarray.free PR for the current status),
but adding this myself with a bit of C code would have been easy enough.
We only touch the memory in one place (for the copy), so manually checking it hadn't been freed would have been pretty safe.
Then I noticed something interesting about the repeated log entries, which mostly looked like this:
Xwayland creates a pool, allocates a buffer within it, destroys the pool (so it can't create more buffers), and then deletes the buffer.
But it never uses the buffer for anything!
So the solution was simple: I just made the host buffer allocation and the mapping operations lazy.
We force the mapping if a pool's buffer is ever attached to a surface, but if not we just close the FD and forget about it.
Would be more efficient if Xwayland only shared the pools when needed, though.
Pointer events
Wayland delivers pointer events relative to a surface, so we simply forward these on to Xwayland unmodified and everything just works.
I'm kidding - this was the hardest bit! When Xwayland gets a pointer event on a window, it doesn't send it directly to that window.
Instead, it converts the location to screen coordinates and then pushes the event through the old X event handling mechanism, which looks at the X11 window stack to decide where to send it.
However, the X11 window stack (which we saw earlier with xwininfo -tree -root) doesn't correspond to the Wayland window layout at all.
In fact, Wayland doesn't provide us any way to know where our windows are, or how they are stacked.
Sway seems to handle this via a backdoor: X11 applications do get access to location information even though native Wayland clients don't.
This is one of the reasons I want to get X11 support out of the compositor - I want to make sure X11 apps don't have any special access.
Sommelier has a solution though: when the pointer enters a window we raise it to the top of the X11 stack. Since it's the topmost window, it will get the events.
Unfortunately, the raise request goes over the X11 connection while the pointer events go over the Wayland one.
We need to make sure that they arrive in the right order.
If the computer is running normally, this isn't much of a problem,
but if it's swapping or otherwise struggling it could result in events going to the wrong place
(I temporarily added a 2-second delay to test this).
This is what I ended up with:
Get a wayland pointer enter event from Sway.
Pause event delivery from Sway.
Flush any pending Wayland events we previously sent to Xwayland by doing a round-trip on the Wayland connection.
Send a raise on the X11 connection.
Do a round-trip on the X11 connection to ensure the raise has completed.
Forward the enter event on the Wayland connection.
Unpause the event stream from Sway.
At first I tried queuing up just the pointer events,
but that doesn't work because e.g. keyboard events need to be synchronised with pointer events.
Otherwise, if you e.g. Shift-click on something then the click gets delayed but the Shift doesn't and it can do the wrong thing.
Also, Xwayland might ask Sway to destroy the window while we're entering it, and Sway might confirm the deletion.
Pausing the whole event stream from Sway fixes all these problems.
The next problem was how to do the two round-trips.
For X11 we just send an Intern request after the raise and wait to get a reply to that.
Wayland provides the wl_display.sync method to clients, but we're acting as a Wayland server to Xwayland,
not a client.
I remembered that Wayland's xdg-shell extension provides a ping from the server to the client
(the compositor can use this to detect when an application is not responding).
Unfortunately, Xwayland has no reason to use this extension because it doesn't deal with window roles.
Luckily, it uses it anyway (it does need it for non-rootless mode and doesn't bother to check).
wl_display.sync works by creating a fresh callback object, but xdg-shell's ping just sends a pong event to a fixed object,
so we also need a queue to keep track of pings in flight so we don't get confused between our pings and any pings we're relaying for Sway.
Also, xdg-shell's ping requires a serial number and we don't have one.
But since Xwayland is the only app this needs to support, and it doesn't look at that, I cheat and just send zero.
And that's how to get pointer events to go to the right window with Xwayland.
Keyboard events
A very similar problem exists with the keyboard.
When Wayland says the focus has entered a window
we need to send a SetInputFocus over the X11 connection
and then send the keyboard events over the Wayland one,
requiring another two round-trips to synchronise the two connections.
Pointer cursor
Some applications set their own pointer shape, which works fine.
But others rely on the default and for some reason you get no cursor at all in that case.
To fix it, you need to set a cursor on the root window, which applications will then inherit by default.
Unlike Wayland, where every application provides its own cursor bitmaps,
X very sensibly provides a standard set of cursors, in a font called cursor
(this is why I had to implement OpenFont).
As cursors have two colours and a mask, each cursor is two glyphs: even numbered glyphs are the image and the following glyph is its mask:
12345678910
(* Load the default cursor image *)let*cursor_font=X11.Font.open_fontx11"cursor"inlet*default_cursor=X11.Font.create_glyph_cursorx11~source_font:cursor_font~mask_font:cursor_font~source_char:68~mask_char:69~bg:(0xffff,0xffff,0xffff)~fg:(0,0,0)inX11.Window.create_attributes~cursor:default_cursor()|>X11.Window.change_attributesx11root
Selections
The next job was to get copying text between X and Wayland working.
In X11:
When you select something, the application takes ownership of the PRIMARY selection.
When you click the middle button or press Shift-Insert, the application requests PRIMARY.
When you press Ctrl-C, the application takes ownership of the CLIPBOARD selection.
When you press Ctrl-V it requests CLIPBOARD.
It's quite neat that adding support for a Windows-style clipboard didn't require changing the X server at all.
Good forward-thinking design there.
In Wayland, things are not so simple.
I have so far found no less than four separate Wayland protocols for copying text:
gtk_primary_selection supports copying the primary selection, but not the clipboard.
wp_primary_selection_unstable_v1 is identical to gtk_primary_selection except that it renames everything.
wl_data_device_manager supports clipboard transfers but not the primary selection.
zwlr_data_control_manager_v1 supports both, but it's for a "privileged client" to be a clipboard manager.
gtk_primary_selection and wl_data_device_manager both say they're stable, while the other two are unstable.
However, Sway dropped support for gtk_primary_selection a while ago, breaking many applications
(luckily, I had a handy Wayland proxy and was able to add some adaptor code
to route gtk_primary_selection messages to the new "unstable" protocol).
For this project, I went with wp_primary_selection_unstable_v1 and wl_data_device_manager.
On the Wayland side, everything has to be written twice for the two protocols, which are almost-but-not-quite the same.
In particular, wl_data_device_manager also has a load of drag-and-drop stuff you need to ignore.
For each selection (PRIMARY or CLIPBOARD), we can be in one of two states:
An X11 client owns the selection (and we own the Wayland selection).
A Wayland client owns the selection (and we own the X11 selection).
When we own a selection we proxy requests for it to the matching selection on the other protocol.
At startup, we take ownership of the X11 selection, since there are no X11 apps running yet.
When we lose the X11 selection it means that an X11 client now owns it and we take the Wayland selection.
When we lose the Wayland selection it means that a Wayland client now owns it and we take the X11 selection.
One good thing about the Wayland protocols is that you send the data by writing it to a normal Unix pipe.
For X11, we need to write the data to a property on the requesting application's window and then notify it about the data.
And we may need to split it into multiple chunks if there's a lot of data to transfer.
A strange problem I had was that, while pasting into GVim worked fine, xterm would segfault shortly after trying to paste into it.
This turned out to be a bug in the way I was sending the notifications.
If an X11 application requests the special TEXT target, it means that the sender should choose the exact format.
You write the property with the chosen type (e.g. UTF8_STRING),
but you must still send the notification with the target TEXT.
xterm is a C application (thankfully no longer set-uid!) and seems to have a use-after-free bug in the timeout code.
Drag-and-drop
Sadly, I wasn't able to get this working at all.
X itself doesn't know anything about drag-and-drop and instead applications look at the window tree to decide where the user dropped things.
This doesn't work with the proxy, because Wayland doesn't tell us where the windows really are on the screen.
Even without any VMs or proxies, drag-and-drop from X applications to Wayland ones doesn't work,
because the X app can't see the Wayland window and the drop lands on the X window below (if any).
Bonus features
In the last post, I mentioned several other problems, which have also now been solved by the proxy:
HiDPI works
Wayland's support for high resolution screens is a bit strange.
I would have thought that applications really only need to know two things:
The size in pixels of the window.
The size in pixels you want some standard thing (e.g. a normal-sized letter M).
Some systems instead provide the size of the window and the DPI (dots-per-inch),
but this doesn't work well.
For example, a mobile phone might be high DPI but still want small text because you hold it close to your face,
while a display board will have very low DPI but want large text.
Wayland instead redefines the idea of pixel to be a group of pixels corresponding to a single pixel on a typical 1990's display.
So if you set your scale factor to 2 then 1 Wayland pixel is a 2x2 grid of physical pixels.
If you have a 1000x1000 pixel window, Wayland will tell the application it is 500x500 but suggest a scale factor of 2.
If the application supports HiDPI mode, it will double all the numbers and render a 1000x1000 image and things work correctly.
If not, it will render a 500x500 pixel image and the compositor will scale it up.
Since Xwayland doesn't support this, it just draws everything too small and Sway scales it up,
creating a blurry and unusable mess.
This might be made worse by subpixel rendering, which doesn't cope well with being scaled.
With the proxy, the solution is simple enough: when talking to Xwayland we just scale everything back up to the real dimensions,
scaling all coordinates as we relay them:
This will tend to make things sharp but too small, but X applications already have their own ways to handle high resolution screens.
For example, you can set Xft.dpi to make all the fonts bigger. I run this proxy like this, which works for me:
However, there is a problem.
The Wayland specification says:
The new size of the surface is calculated based on the buffer
size transformed by the inverse buffer_transform and the
inverse buffer_scale. This means that at commit time the supplied
buffer size must be an integer multiple of the buffer_scale. If
that's not the case, an invalid_size error is sent.
Let's say we have an X11 image viewer that wants to show a 1001-pixel-high image in a 1001-pixel-high window.
This isn't allowed by the spec, which can only handle even-sized windows when the scale factor is 2.
Regular Wayland applications already have to deal with that somehow, but for X11 applications it becomes our problem.
I tried rounding down, but that has a bad side-effect: if GTK asks for a 1001-pixel high menu and gets a 1000 pixel allocation,
it switches to squashed mode and draws two big bumper arrows at the top and bottom of the menu which you must use to scroll it.
It looks very silly.
I also tried rounding up, but tooltips look bad with any rounding. Either one border is missing, or it's double thickness.
Luckily, it seems that Sway doesn't actually enforce the rule about surfaces being a multiple of the scale factor.
So, I just let the application attach a buffer of whatever size it likes to the surface and it seems to work!
The only problem I had was that when using unscaling, the mouse pointer in GVim would get lost.
Vim hides it when you start typing, but it's supposed to come back when you move the mouse.
The problem seems to be that it hides it by creating a 1x1 pixel cursor.
Sway decides this isn't worth showing (maybe because it's 0x0 in Wayland-pixels?),
and sends Xwayland a leave event saying the cursor is no longer on the screen.
Then when Vim sets the cursor back, Xwayland doesn't bother updating it, since it's not on screen!
The solution was to stop applying unscaling to cursors.
They look better doubled in size, anyway.
True, this does mean that the sharpness of the cursor changes as you move between windows,
but you're unlikely to notice this
due to the far more jarring effect of Wayland cursors also changing size and shape at the same time.
Ring-buffer logging
Even without a proxy to complicate things, Wayland applications often have problems.
To make investigating this easier, I added a ring-buffer log feature.
When on, the proxy keeps the last 512K or so of log messages in memory, and will dump them out on demand.
To use it, you run the proxy with e.g. -v --log-ring-path ~/wayland.log.
When something odd happens (e.g. an application crashes, or opens its menus in the wrong place) you can
dump out the ring buffer and see what just happened with:
echo dump-log > /run/user/1000/wayland-1-ctl
I also added some filtering options (e.g. --log-suppress motion,shm) to suppress certain classes of noisy messages.
Vim windows open correctly
One annoyance with Sway is that Vim's window always appears blank (even when running on the host, without any proxy).
You have to resize it before you can see the text.
My proxy initially suffered from the same problem, although only intermittently.
It turned out to be because Vim sends a ConfigureRequest with its desired size and then waits for the confirmation message.
Since Sway is a tiling window manager, it ignores the new size and no event is generated.
In this case, an X11 window manager is supposed to send a synthetic ConfigureNotify,
so I just got the proxy to do that and the problem disappeared
(I confirmed this by adding a sleep to Vim's gui_mch_update).
By the way, the GVim start-up code is quite interesting.
The code path to opening the window goes though three separate functions which each define a
static int recursive = 0 and then proceed to behave differently depending on how many times they've
been reentered - see gui_init for an example!
Copy-and-paste without ^M characters
The other major annoyance with Sway is that copy-and-paste doesn't work correctly (Sway bug #1839).
Using the proxy avoids that problem completely.
Conclusions
I'm not sure how I feel about this project.
It ended up taking a lot longer than I expected, and I could probably have ported several X11 applications to Wayland in the same time.
On the other hand, I now have working X support in the VMs with no need for ssh -Y from the host, plus support for HiDPI in Wayland, mouse cursors that are large enough to see easily, windows that open reliably, text pasting that works, and I can get logs whenever something misbehaves.
In fact, I'm now also running an instance of the proxy directly on the host to get the same benefits for host X11 applications.
Setting this up is actually a bit tricky:
you want to start Sway with DISPLAY=:0 so that every application it spawns knows it has an X11 display,
but if you set that then Sway thinks you want it to run nested inside an X window provided by the proxy,
which doesn't end well (or, indeed, at all).
Having all the legacy X11 support in a separate binary should make it much easier to write new Wayland compositors,
which might be handy if I ever get some time to try that.
It also avoids having many thousands of lines of legacy C code in the highly-trusted compositor code.
If Wayland had an official protocol for letting applications know the window layout then I could make drag-and-drop between X11 applications within the same VM work, but it still wouldn't work between VMs or to Wayland applications, so it's probably not worth it.
Having two separate connections to Xwayland creates a lot of unnecessary race conditions.
A simple solution might be a Wayland extension that allows the Wayland server to say "please read N bytes from the X11 socket now",
and likewise in the other direction.
Then messages would always arrive in the order in which they were sent.
The code is all available at https://github.com/talex5/wayland-proxy-virtwl if you want to try it.
It works with the applications I use when running under Sway,
but will probably require some tweaking for other programs or compositors.
Here's a screenshot of my desktop using it:
The windows with [dev] in the title are from my Debian VM, while [com] is a SpectrumOS VM I use for email, etc.
Gitk, GVim and ROX-Filer are X11 applications using Xwayland,
while Firefox and xfce4-terminal are using plain Wayland proxying.
]]>Qubes-lite with KVM and Wayland2021-03-07T15:00:00+00:00https://roscidus.com/blog/blog/2021/03/07/qubes-lite-with-kvm-and-waylandI've been running QubesOS as my main desktop since 2015.
It provides good security, by running applications in different Xen VMs.
However, it is also quite slow and has some hardware problems.
I've recently been trying out NixOS, KVM, Wayland and SpectrumOS,
and attempting to create something similar with more modern/compatible/faster technology.
This post gives my initial impressions of these tools and describes my current setup.
QubesOS aims to provide "a reasonably secure operating system".
It does this by running multiple virtual machines under the Xen hypervisor.
Each VM's windows have a different colour and tag, but they appear together as a single desktop.
The VMs I run include:
com for email and similar (the only VM that sees my email password).
dev for software development.
shopping (the only VM that sees my card number).
personal (with no Internet access)
untrusted (general browsing)
The desktop environment itself is another Linux VM (dom0), used for managing the other VMs.
Most of the VMs are running Fedora (the default for Qubes), although I run Debian in dev.
There are also a couple of system VMs; one for dealing with the network hardware,
and one providing a firewall between the VMs.
You can run qvm-copy in a VM to copy a file to another VM.
dom0 pops up a dialog box asking which VM should receive the file, and it arrives there
as ~/QubesIncoming/$source_vm/$file.
You can also press Ctrl-Shift-C to copy a VM's clipboard to the global clipboard, and then
press Ctrl-Shift-V in a window of the target VM to copy to that VM's clipboard,
ready for pasting into an application.
I think Qubes does a very good job at providing a secure environment.
However, it has poor hardware compatibility and it feels sluggish, even on a powerful machine.
I bought a new machine a while ago and found that the motherboard only provided a single video output, limited to 30Hz.
This meant I had to buy a discrete graphics card. With the card enabled, the machine fails to resume from suspend,
and locks up from time to time (it's completely stable with the card removed or disabled).
I spent some time trying to understand the driver code, but I didn't know enough about graphics, the Linux kernel, PCI suspend, or Xen to fix it.
I was also having some other problems with QubesOS:
Graphics performance is terrible (especially on a 4k monitor).
Qubes disables graphics acceleration in VMs for security reasons, but it was slow even for software rendering.
It recently started freezing for a couple of seconds from time to time - annoying when you're trying to type.
It uses LVM thin-pools for VM storage, which I don't understand, and which sometimes need repairing (haven't lost any data, though).
dom0 is out-of-date and generally not usable.
This is intentional (you should be using VMs),
but my security needs aren't that high and it would be nice to be able to do video conferencing these days.
Also, being able to print over USB and use bluetooth would be handy.
Anyway, I decided it was time to try something new.
Linux now has its own built-in hypervisor (KVM), and I thought that would probably work better with my hardware.
I was also keen to try out Wayland, which is built around shared-memory and I thought it might therefore work better with VMs.
How easy would it be to recreate a Qubes-like environment directly on Linux?
NixOS
I've been meaning to try NixOS properly for some time. Ever since I started using Linux, its package management has struck me as absurd. On Debian, Fedora, etc, installing a package means letting it put files wherever it likes; which effectively gives the package author root on your system. Not a good base for sandboxing!
Also, they make it difficult to try out 3rd-party software, or to test newer versions of just some packages.
In 2003 I created 0install to address these problems, and Nix has very similar goals. I thought Nix was a few years younger, but looking at its Git history the first commit was on Mar 12, 2003. I announced the first preview of 0install just two days later, so both projects must have started writing code within a few days of each other!
NixOS is made up of quite a few components. Here is what I've learned so far:
nix-store
The store holds the files of all the programs, and is the central component of the system.
Each version of a package goes in its own directory (or file), at /nix/store/$HASH.
You can add data to the store directly, like this:
Here, the store location is calculated from the hash of the contents of the file we added (as with 0install store add or git hash-object).
However, you can also add things to the store by asking Nix to run a build script.
For example, to compile some source code:
You add the source code and some build instructions (a "derivation" file) to the store.
You ask the store to build the derivation. It runs your build script in a container sandbox.
The results are added to the store, using the hash of the build instructions (not the hash of the result) as the directory name.
If a package in the store depends on another one (at build time or run time), it just refers to it by its full path.
For example, a bash script in the store will start something like:
If two users want to use the same build instructions, the second one will see that the hash already exists and can just reuse that.
This allows users to compile software from source and share the resulting binaries, without having to trust each other.
Ideally, builds should be reproducible.
To encourage this, builds which use the hash of the build instructions for the result path are built in a sandbox without network access.
So, you can't submit a build job like "Download and compile whatever is the latest version of Vim".
But you can discover the latest version yourself and then submit two separate jobs to the store:
"Download Vim 8.2, with hash XXX" (a fixed-output job, which therefore has network access)
"Build Vim from hash XXX"
You can run nix-collect-garbage to delete everything from the store that isn't reachable via the symlinks under /nix/var/nix/gcroots/.
Users can put symlinks to things they care about keeping in /nix/var/nix/gcroots/per-user/$USER/.
By default, the store is also configured with a trusted binary cache service,
and will try to download build results from there instead of compiling locally when possible.
nix-instantiate
Writing derivation files by hand is tedious, so Nix provides a templating language to create them easily.
The Nix language is dynamically typed and based around maps/dictionaries (which it confusingly refers to as "sets").
nix-instantiate file.nix will generate a derivation from file.nix and add it to the store.
Add the generated foo.drv to the store, including the full store path of myfile.
nix-pkgs
Writing Nix expressions for every package you want would also be tedious.
The nixpkgs Git repository contains a Nix expression that evaluates to a set of derivations,
one for each package in the distribution.
It also contains a library of useful helper functions for packages
(e.g. it knows how to handle GNU autoconf packages automatically).
Rather than evaluating the whole lot, you use -A to ask for a single package.
For example, you can use nix-instantiate ./nixpkgs/default.nix -A firefox to generate a derivation for Firefox.
nix-build is a quick way to create a derivation with nix-instantiate and build it with nix-store.
It will also create a ./result symlink pointing to its path in the store,
as well as registering ./result with the garbage collector under /nix/var/nix/gcroots/auto/.
For example, to build and run Firefox:
nix-build ./nixpkgs/default.nix -A firefox
./result/bin/firefox
If you use nixpkgs without making any changes, it will be able to download a pre-built binary from the cache service.
nix-env
Keeping track of all these symlinks would be tedious too,
but you can collect them all together by making a package that depends on every application you want.
Its build script will produce a bin directory full of symlinks to the applications.
Then you could just point your $PATH variable at that bin directory in the store.
To make updating easier, you will actually add ~/.nix-profile/bin/ to $PATH and
update .nix-profile to point at the latest build of your environment package.
This is essentially what nix-env does, except with yet more symlinks to allow for
switching between multiple profiles, and to allow rolling back to previous environments
if something goes wrong.
For example, to install Firefox so you can run it via $PATH:
nix-env -i firefox
NixOS
Finally, just as nix-env can create a user environment with bin, man, etc,
a similar process can create a root filesystem for a Linux distribution.
nixos-rebuild reads the /etc/nixos/configuration.nix configuration file,
generates a system environment,
and then updates grub and the /run/current-system symlink to point to it.
In fact, it also lists previous versions of the system environment in the grub file, so
if you mess up the configuration you can just choose an earlier one from the boot
menu to return to that version.
Installing NixOS
To install NixOS you boot one of the live images at https://nixos.org.
Which you use only affects the installation UI, not the system you end up with.
The manual walks you through the installation process, showing how to partition
the disk, format and mount the partitions, and how to edit the configuration file.
I like this style of installation, where it teaches you things instead of just doing it for you.
Most of the effort in switching to a new system is learning about it, so I'd rather
spend 3 hours learning stuff following an installation guide than use a 15-minute
single-click installer that teaches me nothing.
The configuration file (/etc/nixos/configuration.nix) is just another Nix expression.
Most things are set to off by default (I approve), but can be changed easily.
For example, if you want sound support you change that setting to sound.enable = true,
and if you also want to use PulseAudio then you set hardware.pulseaudio.enable = true too.
Every system service supported by NixOS is controlled from here,
with all kinds of options, from programs.vim.defaultEditor = true (so you don't get trapped in nano)
to services.factorio.autosave-interval.
Use man configuration.nix to see the available settings.
NixOS defaults to an X11 desktop, but I wanted to try Wayland (and Sway).
Based on the NixOS wiki instructions, I used this:
1234567891011121314
programs.sway ={enable =true; wrapperFeatures.gtk =true;# so that gtk works properlyextraSessionCommands ="export MOZ_ENABLE_WAYLAND=1";extraPackages =with pkgs;[ swaylock
swayidle
xwayland
wl-clipboard
mako
alacritty
dmenu
];};
The xwayland bit is important; without that you can't run any X11 applications.
My only complaint with the NixOS installation instructions is that following them will leave you with an unencrypted system,
which isn't very useful.
When partitioning, you have to skip ahead to the LUKS section of the manual, which just gives some options but no firm advice.
I created two primary partitions: a 1G unencrypted /boot, and a LUKS partition for the rest of the disk.
Then I created an LVM volume group from the /dev/mapper/crypted device and added the other partitions in that.
Once the partitions are mounted and the configuration file is complete,
nixos-install downloads everything and configures grub.
Then you reboot into the new system.
Once running the new system you can made further edits to the configuration file there in the same way,
and use nixos-rebuild switch to generate a new system.
It seems to be pretty good at updating the running system to the new settings, so you don't normally need to reboot
after making changes.
The big mistake I made was forgetting to add /boot to fstab.
When I ran nixos-rebuild it put all the grub configuration on the encrypted partition, rendering the system unbootable.
I fixed that with chattr +i /boot on the unmounted partition.
That way, trying to rebuild with /boot unmounted will just give an error message.
Thoughts on NixOS
I've been using the system for a few weeks now and I've had no problems with Nix so far.
Nix has been fast and reliable and there were fairly up-to-date packages for everything I wanted
(I'm using the stable release).
There is a lot to learn, but plenty of documentation.
When I wanted a newer package (socat with vsock support, only just released) I just told Nix to install it from the latest Git checkout of nixpkgs.
Unlike on Debian and similar systems, doing this doesn't interfere with any other packages (such as forcing a system-wide upgrade of libc).
I think Nix does download more data than most other systems, but networks are fast enough now that it doesn't seem to matter.
For example, let's say you're running Python 3.9.0 and you want to update to 3.9.1:
With Debian: apt-get upgrade downloads the new version, which gets unpacked over the old one.
As the files are unpacked, the system moves through an exciting series of intermediate states no-one has thought about.
Running programs may crash as they find their library versions changing under them (though it's usually OK).
Only root can update software.
With 0install: 0install update downloads the new version, unpacking it to a new directory.
Running programs continue to use the old version.
When a new program is started, 0install notices the update and runs the solver again.
If the program is compatible with the new Python then it uses that. If not, it continues with the old one.
You can run any previous version if there is a problem.
With Nix: nix-env -u downloads the new version, unpacking it to a new directory.
It also downloads (or rebuilds) every package depending on Python, creating new directories for each of them.
It then creates a new environment with symlinks to the latest version of everything.
Running programs continue to use the old version.
Starting a new program will use the new version.
You can revert the whole environment back to the previous version if there is a problem.
With Docker: docker pull downloads the new version of a single application,
downloading most or all of the application's packages, whether Python related or not.
Existing containers continue running with the old version.
New containers will default to using the new version.
You can specify which version to use when starting a program.
Other applications continue using the old version of Python until their authors update them
(you must update each application individually, rather than just updating Python itself).
The main problem with NixOS is that it's quite different to other Linux systems, so there's a lot to relearn.
Also, existing knowledge about how to edit fstab, sudoers, etc, isn't so useful, as you have to provide all configuration in Nix syntax.
However, having a single (fairly sane) syntax for everything is a nice bonus, and being able to generate things using the templating language is useful.
For example, for my network setup I use a bunch of tap devices (one for each of my VMs).
It was easy to write a little Nix function (mktap) to generate them all from a simple list.
Here's that section of my configuration.nix:
With NixOS I had a nice host environment, but after using Qubes I wanted to run my applications in VMs.
The basic problem is that Linux is the only thing that knows how to drive all the hardware,
but Linux security is not ideal. There are several problems:
Linux is written in C.
This makes security bugs rather common and, more importantly, means that a bug in one part of the code
can impact any other part of the code. Nothing is secure unless everything is secure.
Linux has a rather large API (hundreds of syscalls).
The Linux (Unix) design predates the Internet, and security has been somewhat bolted on afterwards.
For example, imagine that we want to run a program with access to the network, but not to the graphical display.
We can create a new Linux container for it using bubblewrap, like this:
$ ls -l /run/user/1000/wayland-0 /tmp/.X11-unix/X0
srwxr-xr-x 1 tal users 0 Feb 18 16:41 /run/user/1000/wayland-0
srwxr-xr-x 1 tal users 0 Feb 18 16:41 /tmp/.X11-unix/X0
$ bwrap \
--ro-bind / / \
--dev /dev \
--tmpfs /home/tal \
--tmpfs /run/user \
--tmpfs /tmp \
--unshare-all --share-net \
bash
$ ls -l /run/user/1000/wayland-0 /tmp/.X11-unix/X0
ls: cannot access '/run/user/1000/wayland-0': No such file or directory
ls: cannot access '/tmp/.X11-unix/X0': No such file or directory
The container has an empty home directory, empty /tmp, and no access to the display sockets.
If we run Firefox in this environment then... it opens its window just fine!
How? strace shows what happened:
connect(4, {sa_family=AF_UNIX, sun_path="/run/user/1000/wayland-0"}, 27) = -1 ENOENT (No such file or directory)
socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC, 0) = 4
connect(4, {sa_family=AF_UNIX, sun_path=@"/tmp/.X11-unix/X0"}, 20) = 0
After failing to connect to Wayland, it then tried using X11 (via Xwayland) instead. Why did that work?
If the first byte of the socket pathname is \0 then Linux instead interprets it as an "abstract" socket address,
not subject to the usual filesystem permission rules.
Trying to anticipate these kinds of special cases is just too much work.
Linux really wants everything on by default, and you have to find and disable every feature individually.
By contrast, virtual machines tend to have integrations with the host off by default.
The also tend to have much smaller APIs (e.g. just reading and writing disk blocks or network frames),
with the rich Unix API entirely inside the VM, provided by a separate instance of Linux.
SpectrumOS
I was able to set up a qemu guest and restore my dev Qubes VM in that, but it didn't integrate nicely with the rest of the desktop.
Installing ssh allowed me to connect in with ssh -Y dev, allowing apps in the VM to open an X connection to Xwayland on the host.
That was somewhat usable, but still a bit slower than Qubes had been (which was already a bit too slow).
Searching for a way to forward the Wayland connection directly, I came across the SpectrumOS project.
SpectrumOS aims to use one virtual machine per application, using shared directories so that VM files are stored on the host,
simplifying management.
It uses crosvm from the ChromiumOS project instead of qemu, because it has a driver that allows forwarding Wayland connections
(and also because it's written in Rust rather than C).
The project's single developer is currently taking a break from the project, and says "I'm currently working towards a proof of concept".
However, there is some useful stuff in the SpectrumOS repository (which is a fork of nixpkgs).
In particular, it contains:
A version of Linux with the virtwl kernel module, which connects to crosvm's Wayland driver.
A package for sommelier, which connects applications to virtwl.
A Nix expression to build a root filesystem for the VM.
Building that, I was able to run the project's demo, which runs the Wayfire compositor inside the VM, appearing in a window on the host.
Dragging the nested window around, the pixels flowed smoothly across my screen in exactly the way that pixels on QubesOS don't.
This was encouraging, but I didn't want to run a nested window manager.
I tried running Firefox directly (without Wayfire),
but it complained that sommelier didn't provide a new enough version of something, and
running weston-terminal immediately segfaulted sommelier.
Why do we need the sommelier process anyway?
The problem is that, while virtwl mostly proxies Wayland messages directly, it can't send arbitrary FDs to the host.
For example, if you want to forward a writable stream from an application to virtwl
you must first create a pipe from the host using a special virtwl ioctl,
then read from that and copy the data to the application's regular Linux pipe.
I enabled VIRTIO_FS, allowing me to mount a host directory into the VM (for sharing files).
I created some tap devices (as mentioned above) to get guest networking going.
Adding ext4 to the kernel image allowed me to mount the VM's LVM partition.
Setting FONTCONFIG_FILE got some usable fonts (otherwise, there was no monospace font for the terminal).
I hacked sommelier to claim it supported the latest protocols, which got Firefox running.
Configuring sommelier for Xwayland let X applications run.
I replaced the non-interactive bash shell with fish so I could edit commands.
I ran (while true; do socat vsock-listen:5000 exec:dash; done) at the end of the VM's boot script.
Then I could start e.g. the VM's Firefox with echo 'firefox&' | socat stdin vsock-connect:7:5000
on the host, allowing me to add launchers for guest applications.
Making changes to the root filesystem was fairly easy once I'd read the Nix manuals.
To add an application (e.g. libreoffice), you import it at the start of rootfs/default.nix and add it to the path variable.
The Nix expression gets the transitive dependencies of path from the Nix store and packs them into a squashfs image.
True, my squashfs image is getting a bit big.
Maybe I should instead make a minimal squashfs boot image, plus a shared directory of hard links to the required files.
That would allow sharing the data with the host.
I could also just share the whole /nix/store directory, if I wanted to make all host software available to guests.
I made another Nix script to add various VM boot commands to my host environment.
For example, running qvm-start-shopping boots my shopping VM using crosvm,
with the appropriate LVM data partition, network settings, and shared host directory.
I think, ideally, this would be a systemd socket-activated user service rather than a shell script.
Then attempting to run Firefox by sending a command to the VM socket would cause systemd to boot the VM
(if not already running).
For now, I boot each VM manually in a terminal and then press Win-Shift-2 to banish it to workspace 2,
with all the other VM root consoles.
The virlwl Wayland forwarding feels pretty fast (much faster than Qubes' X graphics).
Wayland
I now had a mostly functional Qubes-like environment, running most of my applications in VMs,
with their windows appearing on the host desktop like any other application.
However, I also had some problems:
A stated goal of Wayland is "every frame is perfect". However, applications generally seemed to open at the wrong size and then jump to their correct size, which was a bit jarring.
Vim opened its window with the scrollbar at the far left of the window, making the text invisible until you resized the window.
Wayland is supposed to have better support for high-DPI displays.
However, this doesn't work with Xwayland, which turns everything blurry,
and the recommended work-around is to use a scale-factor of 1
and configure each application to use bigger fonts.
This is easy enough with X applications (e.g. set ft.dpi: 150 with xrdb), but Wayland apps must be configured individually.
Wayland doesn't have cursor themes and you have to configure every application individually to use a larger cursor too.
Copying text didn't seem to work reliably. Sometimes there would be a long delay, after which the text might or might not appear. More often, it would just paste something completely different and unexpected. Even when it did paste the right text, it would often have ^M characters inserted into it.
I decided it was time to learn more about Wayland.
I discovered wayland-book.com, which does a good job of introducing it
(though the book is only half finished at the moment).
Protocol
One very nice feature of Wayland is that you can run any Wayland application with WAYLAND_DEBUG=1
and it will display a fairly readable trace of all the Wayland messages it sends and receives.
Let's look at a simple application that just connects to the server (compositor) and opens a window:
The client connects to the server's socket at /run/user/1000/wayland-0 and sends two messages
to object 1 (of type wl_display), which is the only object available in a new connection.
The get_registry request asks the server to add the registry to the conversation and call it object 2.
The sync request just asks the server to confirm it got it, using a new callback object (with ID 3).
Both clients and servers can add objects to the conversation.
To avoid numbering conflicts, clients assign low numbers and servers pick high ones.
On the wire, each message gives the object ID, the operation ID, the length in bytes, and then the arguments.
Objects are thought of as being at the server, so the client sends request messages to objects,
while the server emits event messages from objects.
At the wire level there's no difference though.
When the server gets the get_registry request it adds the registry,
which immediately emits one event for each available service, giving the maximum supported version.
The client receives these messages, followed by the callback notification from the sync message:
The callback tells the client it has seen all the available services, and so it now picks the ones it wants.
It has to choose a version no higher than the one offered by the server.
Protocols starting with wl_ are from the core Wayland protocol; the others are extensions.
The leading z in zxdg_output_manager_v1 indicates that the protocol is "unstable" (under development).
The protocols are defined in various XML files, which are scattered over the web.
The core protocol is defined in wayland.xml.
These XML files can be used to generate typed bindings for your programming language of choice.
Here, the application picks wl_compositor (for managing drawing surfaces), wl_shm (for sharing memory with the server),
and xdg_wm_base (for desktop windows).
The bind message is unusual in that the client gives the interface and version of the object it is creating.
For other messages, both sides know the type from the schema, and the version is always the same as the parent object.
Because the client chose the new IDs, it doesn't need to wait for the server;
it continues by using the new objects to create a top-level window:
This API is pretty strange.
The core Wayland protocol says how to make generic drawing surfaces, but not how to make windows,
so the application is using the xdg_wm_base extension to do that.
Logically, there's only one object here (a toplevel window),
but it ends up making three separate Wayland objects representing the different aspects of it.
The commit tells the server that the client has finished setting up the window and the server should
now do something with it.
The above was all in response to the callback firing.
The client now processes the last message in that batch, which is the server destroying the callback:
<- wl_display@1.delete_id id:3
Object destruction is a bit strange in Wayland.
Normally, clients ask for things to be destroyed (by sending a "destructor" message)
and the server confirms by sending delete_id from object 1.
But this isn't symmetrical: there is no standard way for a client to confirm deletion when the server calls
a destructor (such as the callback's done), so these have to be handled on a case-by-case basis.
Since callbacks don't accept any messages, there is no need for the client to confirm that it got the done
message and the server just sends a delete message immediately.
The client now waits for the server to respond to all the messages it sent about the new window,
and gets a bunch of replies:
It gets some messages telling it what pixel formats are supported, a ping message (which the server sends from time to time to check the client is still alive),
and a configure message giving the size for the new window.
Oddly, Sway has set the size to 0x0, which means the client should choose whatever size it likes.
The client picks a suitable default size, allocates some shared memory (by opening a tmpfs file and immediately unlinking it),
shares the file descriptor with the server (create_pool), and then carves out a portion of the memory to use as a buffer for the pixel data:
In this case it used the whole memory region. It could also have allocated two buffers for double-buffering.
The client then draws whatever it wants into the buffer (mapping the file into its memory and writing to it directly),
attaches the buffer to the window's surface, marks the whole area as "damaged" (in need of being redrawn) and calls commit,
telling the server the surface is ready for display:
Although the window is visible, the content is the wrong size.
Sway now suddenly remembers that it's a tiling window manager.
It sends another configure event with the correct size, causing the client to allocate a fresh memory pool of the correct size,
allocate a fresh buffer from it, redraw everything at the new size, and tell the server to draw it.
This process of telling the client to pick a size and then overruling it explains why Firefox draws itself incorrectly at first and then flickers into position a moment later. It probably also explains why Vim tries to open a 0x0 window.
Copying text
A bit of searching revealed that the ^M problem is a known Sway bug.
However, the main reason copying text wasn't working turned out to be a limitation in the design of the core wl_data_device_manager protocol.
The normal way to copy text on X11 is to select the text you want to copy,
then click the middle mouse button where you want it (or press Shift-Insert).
X also supports a clipboard mechanism, where you select text, then press Ctrl-C, then click at the destination, then press Ctrl-V.
The original Wayland protocol only supports the clipboard system, not the selection, and so Wayland compositors have added selection support through extensions.
Sommelier didn't proxy these extensions, leading to failure when copying in or out of VMs.
I also found that the reason weston-terminal wouldn't start was because I didn't have anything in my clipboard,
and sommelier was trying to dereference a null pointer.
One problem with the Wayland protocol is that it's very hard to proxy.
Although the wire protocol gives the length in bytes of each message, it doesn't say how many file descriptors it has.
This means that you can't just pass through messages you don't understand, because you don't know which FDs go with which message.
Also, the wire protocol doesn't give types for FDs (nor does the schema),
which is a problem for anything that needs to proxy across a VM boundary or over a network.
This all meant that VMs could only use protocols explicitly supported by sommelier, and sommelier limited the version too.
Which means that supporting extra extensions or new versions means writing (and debugging) loads of C++ code.
I didn't have time to write and debug C++ code for every missing Wayland protocol, so I took a short-cut:
I wrote my own Wayland library, ocaml-wayland, and then used that to write my own version of sommelier.
With that, adding support for copying text was fairly easy.
For each Wayland interface we need to handle each incoming message from the client and forward it to the host,
and also forward each message from the host to the client.
Here's the code to handle the "selection" event in OCaml,
which we receive from the host and send to the client (c):
The host passes us an "offer" argument, which is a previously-created host offer object.
We look up the corresponding client object with to_client and pass that as the argument
to the client.
I think this is a great demonstration of the difference between "type safety" and "type ceremony".
The C++ code is covered in types, making the code very hard to read, yet it crashes at runtime because it
fails to consider that data_offer can be NULL.
By contract, the OCaml version has no type annotations, but the compiler would reject if I forgot to handle this (with Option.map).
Security
According to the GNOME wiki, the original justification for not supporting selection copies was
"security concerns with unexpected data stealing if the mere act of selecting a text fragment makes it available to all running applications".
The implication is that applications stealing data instead from the clipboard is OK,
and that you should therefore never put anything confidential on the clipboard.
This seemed a bit odd, so I read the security section of the Wayland specification to learn more about its security model.
That section of the specification is fairly short, so I'll reproduce it here in full:
Security and Authentication
mostly about access to underlying buffers, need new drm auth mechanism (the grant-to ioctl idea), need to check the cmd stream?
getting the server socket depends on the compositor type, could be a system wide name, through fd passing on the session dbus. or the client is forked by the compositor and the fd is already opened.
It looks like implementations have to figure things out for themselves.
The main advantage of Wayland over X11 here is that Wayland mostly isolates applications from each other.
In X11 applications collaborate together to manage a tree of windows, and any application can access any window.
In the Wayland protocol, each application's connection only includes that application's objects.
Applications only get events relevant to their own windows
(for example, you only get pointer motion events while the pointer is over your window).
Communication between applications (e.g. copy-and-paste or drag-and-drop) is all handled though the compositor.
Also, to request the contents of the clipboard you need to quote the serial number of the mouse click or key press that triggered it.
If it's too far in the past, the compositor can ignore the request.
I've also heard people say that security is the reason you can't take screenshots with Wayland.
However, Sway lets you take screenshots, and this worked even from inside a VM through virtwl.
I didn't add screenshot support to the proxy, because I don't want VMs to be able to take screenshots,
but the proxy isn't a security tool (it runs inside the VM, which isn't trusted).
Clearly, the way to fix this was with a new compositor.
One that would offer a different Wayland socket to each VM, tag the windows with the VM name, colour the frames,
confirm copies across VM boundaries, and work with Vim.
Luckily, I already had a handy pure-OCaml Wayland protocol library available.
Unluckily, at this point I ran out of holiday.
Future work
There are quite a few things left to do here:
One problem with virtwl is that, while we can receive shared memory FDs from the host, we can't export guest memory to the host.
This is unfortunate, because in Wayland the shared memory for window contents is allocated by the application from guest memory,
and the proxy therefore has to copy each frame. If the host provided the memory to the guest, this wouldn't be needed.
There is a wl_drm protocol for allocating video memory, which might help here, but I don't know how that works and,
like many Wayland specifications, it seems to be in the process of being replaced by something else.
Also, if we're going to copy the memory, we should at least only copy the damaged region, not the whole thing.
I only got this code working just far enough to run the Wayland applications I use (mainly Firefox and Evince).
I'm still using ssh to proxy X11 connections (mainly for Vim and gitk).
I'd prefer to run Xwayland in the VM, but it seems you need to provide a bit of extra support for that,
which I haven't implemented yet.
Sommelier can do this, but then copying doesn't work.
The host Wayland compositor needs to be aware of VMs, so it can colour the titles appropriately and
limit access to privileged operations.
For the full Qubes experience, the network card should be handled by a VM, with another VM managing the firewall.
Perhaps the Mirage unikernel firewall could be made to work on KVM too.
I'm not sure how guest-to-guest communication works with KVM.
However, because the host NixOS environment is a fully-working Linux system,
I can always trade off some security to get things working
(e.g. by doing video conferencing directly on the host).
I hope the SpectrumOS project will resume at some point,
or that Qubes will find a solution to its hardware compatibility and performance problems.
]]>CI/CD pipelines: Monad, Arrow or Dart?2019-11-14T09:59:40+00:00https://roscidus.com/blog/blog/2019/11/14/cicd-pipelinesIn this post I describe three approaches to building a language for writing CI/CD pipelines. My first attempt used a monad, but this prevented static analysis of the pipelines. I then tried using an arrow, but found the syntax very difficult to use. Finally, I ended up using a light-weight alternative to arrows that I will refer to here as a dart (I don't know if this has a name already). This allows for static analysis like an arrow, but has a syntax even simpler than a monad.
I was asked to build a system for creating CI/CD pipelines.
The initial use for it was to build a CI for testing OCaml projects on GitHub (testing each commit against multiple versions of the OCaml compiler and on multiple operating systems).
Here's a simple pipeline that gets the Git commit at the head of a branch, builds it,
and then runs the tests:
The colour-scheme here is that green boxes are completed, orange ones are in progress and grey means the step can't be started yet.
Here's a slightly more complex example, which also downloads a Docker base image, builds the commit in parallel using two different versions of the OCaml compiler, and then tests the resulting images. Here the red box indicates that this step failed:
A more complex example is testing the project itself and then searching for other projects that depend on it and testing those against the new version too:
Here, the circle means that we should wait for the tests to pass before checking the reverse dependencies.
We could describe these pipelines using YAML or similar, but that would be very limiting.
Instead, I decided to use an Embedded Domain Specific Language, so that we can use the host
language's features for free (e.g. string manipulation, variables, functions, imports,
type-checking, etc).
The most obvious approach is making each box a regular function.
Then the first example above could be (here, using OCaml syntax):
However, we'd like to add some extras to the language:
Pipeline steps should run in parallel when possible.
The example2 function above would do the builds one at a time.
Pipeline steps should be recalculated whenever their input changes.
e.g. when a new commit is made we need to rebuild.
The user should be able to view the progress of each step.
The user should be able to trigger a rebuild for any step.
We should be able to generate the diagrams automatically from the code,
so we can see what the pipeline will do before running it.
The failure of one step shouldn't stop the whole pipeline.
The exact extras don't matter too much to this blog post,
so for simplicity I'll focus on just running steps concurrently.
Attempt one: a monad
Without the extra features, we have functions like this:
12
valfetch:commit->sourcevalbuild:source->image
You can read this as "build is a function that takes a source value and returns a (Docker) image".
These functions compose together easily to make a larger function that will fetch a
commit and build it:
123
letfabc=letsrc=fetchcinbuildsrc
We could also shorten this to build (fetch c) or to fetch c |> build.
The |> (pipe) operator in OCaml just calls the function on its right with the argument on its left.
To extend these functions to be concurrent, we can make them return promises, e.g.
But now we can't compose them easily using let (or |>), because the output type of fetch doesn't match the input of build.
However, we can define a similar operation, let* (or >>=) that works with promises. It immediately returns a promise for the final
result, and calls the body of the let* later, when the first promise is fulfilled. Then we have:
123
letfabc=let*src=fetchcinbuildsrc
In order words, by sprinkling a few * characters around we can turn our plain old pipeline into a new concurrent one!
The rules for when you can compose promise-returning functions using let* are exactly the same as the rules about when
you can compose regular functions using let, so writing programs using promises is just as easy as writing regular programs.
Just using let* doesn't add any concurrency within our pipeline
(it just allows it to execute concurrently with other code).
But we can define extra functions for that, such as all to evaluate every promise in a list at once,
or an and* operator to indicate that two things should run in parallel:
1234567891011121314
letexample2commit=(* Fetch the source code and Docker base image in parallel: *)let*src=fetchcommitand*base=docker_pull"ocaml/opam2"inletbuildocaml_version=letdockerfile=make_dockerfile~base~ocaml_versioninlet*image=build~dockerfilesrc~label:ocaml_versionintestimagein(* Build and test against each compiler version in parallel: *)all[build"4.07";build"4.08"]
As well as handling promises,
we could also define a let* for functions that might return errors (the body of the let is called only if the first value
is successful), or for live updates (the body is called each time the input changes), or for all of these things together.
This is the basic idea of a monad.
This actually works pretty well.
In 2016, I used this approach to make DataKitCI, which was used initially as the CI system for Docker-for-Mac.
Later, Anil Madhavapeddy used it to create opam-repo-ci, which is the CI system for opam-repository, OCaml's main package repository.
This checks each new PR to see what packages it adds or modifies,
tests each one against multiple OCaml compiler versions and Linux distributions (Debian, Ubuntu, Alpine, CentOS, Fedora and OpenSUSE),
and then finds all versions of all packages depending on the changed packages and tests those too.
The main problem with using a monad is that we can't statically analyse the pipeline.
Consider the example2 function above. Until we have queried GitHub to get a commit to
test, we cannot run the function and therefore have no idea what it will do.
Once we have commit we can call example2 commit,
but until the fetch and docker_pull operations complete we cannot evaluate the body of the let* to find out what the pipeline will do next.
In other words, we can only draw diagrams showing the bits of the pipeline that have already
executed or are currently executing, and we must indicate opportunities for concurrency
manually using and*.
Attempt two: an arrow
An arrow makes it possible to analyse pipelines statically.
Instead of our monadic functions:
An ('a, 'b) arrow is a pipeline that takes an input of type 'a and produces a result of type 'b.
If we define type ('a, 'b) arrow = 'a -> 'b promise then this is the same as the monadic version.
However, we can instead make the arrow type abstract and extend it to store whatever static information we require.
For example, we could label the arrows:
1234
type('a,'b)arrow={f:'a->'bpromise;label:string;}
Here, arrow is a record. f is the old monadic function and label is the "static analysis".
Users can't see the internals of the arrow type, and must build up pipelines using functions provided by the arrow implementation.
There are three basic functions available:
arr takes a pure function and gives the equivalent arrow.
For our promise example, that means the arrow returns a promise that is already fulfilled.
>>> joins two arrows together.
first takes an arrow from 'a to 'b and makes it work on pairs instead.
The first element of the pair will be processed by the given arrow and
the second component is returned unchanged.
We can have these operations automatically create new arrows with appropriate f and label fields.
For example, in a >>> b, the resulting label field could be the string {a.label} >>> {b.label}.
This means that we can display the pipeline without having to run it first,
and we could easily replace label with something more structured if needed.
That seems quite pleasant, although we did have to give up our variable names.
But things start to get complicated with larger examples. For example2, we
need to define a few standard combinators:
1234567891011121314
(** Process the second component of a tuple, leaving the first unchanged. *)letsecondf=letswap(x,y)=(y,x)inarrswap>>>firstf>>>arrswap(** [f *** g] processes the first component of a pair with [f] and the second with [g]. *)let(***)fg=firstf>>>secondg(** [f &&& g] processes a single value with [f] and [g] in parallel and returns a pair with the results. *)let(&&&)fg=arr(funx->(x,x))>>>(f***g)
We've lost most of the variable names and instead have to use tuples, remembering where our values are.
It's not too bad here with two values,
but it gets very difficult very quickly as more are added and we start nesting tuples.
We also lost the ability to use an optional labelled argument in build ~dockerfile src
and instead need to use a new operation that takes a tuple of the dockerfile and the source.
Imagine that running the tests now requires getting the test cases from the source code.
In the original code, we'd just change test image to test image ~using:src.
In the arrow version, we need to duplicate the source before the build step,
run the build with first build_with_dockerfile,
and make sure the arguments are the right way around for a new test_using.
Attempt three: a dart
I started wondering whether there might be an easier way to achieve the same static analysis that you get with arrows,
but without the point-free syntax, and it seems that there is. Consider the monadic version of example1.
We had:
If you didn't know about monads, there is another way you might try to do this.
Instead of using let* to wait for the fetch to complete and then calling build with
the source, you might define build and test to take promises as inputs:
After all, fetching gives you a source promise and you want an image promise, so this seems very natural.
We could even have example1 take a promise of the commit.
Then it looks like this:
That's good, because it's identical to the simple version we started with.
The problem is that it is inefficient:
We call example1 with the promise of the commit (we don't know what it is yet).
Without waiting to find out which commit we're testing, we call fetch, getting back a promise of some source.
Without waiting to get the source, we call build, getting a promise of an image.
Without waiting for the build, we call test, getting a promise of the results.
We return the final promise of the test results immediately, but we haven't done any real work yet.
Instead, we've built up a long chain of promises, wasting memory.
However, in this situation what we want is to perform a static analysis.
i.e. we want to build up in memory some data structure representing the pipeline...
and this is exactly what our "inefficient" use of the monad produces!
To make this useful, we need the primitive operations (such as fetch)
to provide some information (e.g. labels) for the static analysis.
OCaml's let syntax doesn't provide an obvious place for a label,
but I was able to define an operator (let**) that returns a function taking a label argument.
It can be used to build primitive operations like this:
1234
letfetchcommit="fetch"|>let**commit=commitin(* (standard monadic implementation of fetch goes here) *)
So, fetch takes a promise of a commit, does a monadic bind on it to wait for the actual commit and then proceeds as before,
but it labels the bind as a fetch operation.
If fetch took multiple arguments, it could use and* to wait for all of them in parallel.
In theory, the body of the let** in fetch could contain further binds.
In that case, we wouldn't be able to analyse the whole pipeline at the start.
But as long as the primitives wait for all their inputs at the start and don't do any binds internally,
we can discover the whole pipeline statically.
We can choose whether to expose these bind operations to application code or not.
If let* (or let**) is exposed, then applications get to use all the expressive power of monads,
but there will be points where we cannot show the whole pipeline until some promise resolves.
If we hide them, then applications can only make static pipelines.
My approach so far has been to use let* as an escape hatch, so that any required pipeline can be built,
but I later replace any uses of it by more specialised operations. For example, I added:
1
vallist_map:('at->'bt)->'alistt->'blistt
This processes each item in a list that isn't known until runtime.
However, we can still know statically what pipeline we will apply to each item,
even though we don't know what the items themselves are.
list_map could have been implemented using let*, but then we wouldn't be able to see the pipeline statically.
Here are the other two examples, using the dart approach:
Compared to the original, we have an all to combine the results, and there's an extra let+ base = base when calculating the dockerfile.
let+ is just another syntax for map, used here because I chose not to change the signature of make_dockerfile.
Alternatively, we could have make_dockerfile take a promise of the base image and do the map inside it instead.
Because map takes a pure body (make_dockerfile just generates a string; there are no promises or errors) it doesn't need its own box
on the diagrams and we don't lose anything by allowing its use.
This shows another custom operation: gate revdeps ~on:ok is a promise that only resolves once both revdeps and ok have resolved.
This prevents it from testing the library's revdeps until the library's own tests have passed,
even though it could do this in parallel if we wanted it to.
Whereas with a monad we have to enable concurrency explicitly where we want it (using and*),
with a dart we have to disable concurrency explicitly where we don't want it (using gate).
I also added a list_iter convenience function,
and gave it a pretty-printer argument so that we can label the cases in the diagrams once the list inputs are known.
Finally, although I said that you can't use let* inside a primitive,
you can still use some other monad (that doesn't generate diagrams).
In fact, in the real system I used a separate let> operator for primitives.
That expects a body using non-diagram-generating promises provided by the underlying promise library,
so you can't use let* (or let>) inside the body of a primitive.
Comparison with arrows
Given a "dart" you can create an arrow interface from it easily by defining e.g.
1
type('a,'b)arrow='apromise->'bpromise
Then arr is just map and f >>> g is just fun x -> g (f x). first can be defined easily too, assuming you have some kind
of function for doing two things in parallel (like our and* above).
So a dart API (even with let* hidden) is still enough to express any pipeline you can express using an arrow API.
The Haskell Arrow tutorial uses an example where an arrow is a stateful function.
For example, there is a total arrow that returns the sum of its input and every previous input it has been called with.
e.g. calling it three times with inputs 1 2 3 produces outputs 1 3 6.
Running a pipeline on a sequence of inputs returns the sequence of outputs.
The tutorial uses total to define a mean1 function like this:
So this pipeline duplicates each input number,
replaces the second one with 1,
totals both streams, and then
replaces each pair with its ratio.
Each time you put another number into the pipeline, you get out the average of all values input so far.
The equivalent code using the dart style would be (OCaml uses /. for floating-point division):
This is not a great example of an arrow anyway,
because we don't use the output of one stateful function as the input to another,
so this is actually just a plain applicative.
We could easily extend the example pipeline with another stateful function though,
perhaps by adding some smoothing.
That would look like mean1 >>> smooth in the arrow notation,
and values |> mean |> smooth (or smooth (mean values)) in the dart notation.
Note: Haskell does also have an Arrows syntax extension, which allows the Haskell code to be written as:
I've put up a library using a slightly extended version of these ideas at ocurrent/ocurrent.
The lib_term subdirectory is the part relevant to this blog post, with the various combinators described in TERM.
The other directories handle more concrete details, such as integration with the Lwt promise library,
and providing the admin web UI or the Cap'n Proto RPC interface, as well as plugins with primitives
for using Git, GitHub, Docker and Slack.
OCaml Docker base image builder
ocurrent/docker-base-images contains a pipeline that builds Docker base images for OCaml for various Linux distributions, CPU architectures, OCaml compiler versions and configuration options.
For example, to test OCaml 4.09 on Debian 10, you can do:
$ docker run --rm -it ocurrent/opam:debian-10-ocaml-4.09
:~$ ocamlopt --version
4.09.0
:~$ opam depext -i utop
[...]
:~$ utop
----+-------------------------------------------------------------+------------------
| Welcome to utop version 2.4.2 (using OCaml version 4.09.0)! |
+-------------------------------------------------------------+
Type #utop_help for help about using utop.
-( 11:50:06 )-< command 0 >-------------------------------------------{ counter: 0 }-
utop #
Here's what the pipeline looks like (click for full-size):
It pulls the latest Git commit of opam-repository each week, then builds base images containing that and the opam package manager for each distribution version, then builds one image for each supported compiler variant. Many of the images are built on multiple architectures (amd64, arm32, arm64 and ppc64) and pushed to a staging area on Docker Hub. Then, the pipeline combines all the hashes to push a multi-arch manifest to Docker Hub. There are also some aliases (e.g. debian means debian-10-ocaml-4.09 at the moment). Finally, if there is any problem then the pipeline sends the error to a Slack channel.
You might wonder whether we really need a pipeline for this, rather than a simple script run from a cron-job.
But having a pipeline allows us to see what the pipeline will do before running it, watch the pipeline's progress, restart failed jobs individually, etc, with almost the same code we would have written anyway.
You can read pipeline.ml if you want to see the full pipeline.
OCaml CI
ocurrent/ocaml-ci is an (experimental) GitHub app for testing OCaml projects.
The pipeline gets the list of installations of the app,
gets the configured repositories for each installation,
gets the branches and PRs for each repository,
and then tests the head of each one against multiple Linux distributions and OCaml compiler versions.
If the project uses ocamlformat, it also checks that the commit is formatted exactly as ocamlformat would do it.
The results are pushed back to GitHub as the commit status, and also recorded in a local index for the web and tty UIs.
There's quite a lot of red here mainly because if a project doesn't support a particular version of OCaml then the build is marked
as failed and shows up as red in the pipeline, although these failures are filtered out when making the GitHub status report.
We probably need a new colour for skipped stages.
Conclusions
It's convenient to write CI/CD pipelines as if they were single-shot scripts
that run the steps once, in series, and always succeed,
and then with only minor changes have the pipeline run the steps whenever
the input changes, in parallel, with logging, error reporting, cancellation
and rebuild support.
Using a monad allows any program to be converted easily to have these features,
but, as with a regular program, we don't know what the program will do with some
data until we run it. In particular, we can only automatically generate diagrams
showing steps that have already started.
The traditional way to do static analysis is to use an arrow.
This is a little more limited than a monad, because the structure of the pipeline
can't change depending on the input data, although we can add limited flexibility
such as optional steps or a choice between two branches.
However, writing pipelines using arrow notation is difficult because we have to
program in a point-free style (without variables).
We can get the same benefits of static analysis by using a monad in an unusual way,
here referred to as a "dart".
Instead of functions that take plain values and return wrapped values, our functions
both take and return wrapped values. This results in a syntax that looks
identical to plain programming, but allows static analysis (at the cost of not being
able to manipulate the wrapped values directly).
If we hide (or don't use) the monad's let* (bind) function then the pipelines we
create can always be determined statically. If we use a bind, then there will be holes
in the pipeline that may expand to more pipeline stages as the pipeline runs.
Primitive steps can be created by using a single "labelled bind", where the label
provides the static analysis for the atomic component.
I haven't seen this pattern used before (or mentioned in the arrow documentation),
and it seems to provide exactly the same benefits as arrows with much less difficulty.
If this has a proper name, let me know!
This work was funded by OCaml Labs.
]]>Using TLA+ to understand Xen vchan2019-01-01T09:15:18+00:00https://roscidus.com/blog/blog/2019/01/01/using-tla-plus-to-understand-xen-vchanThe vchan protocol is used to stream data between virtual machines on a Xen host without needing any locks.
It is largely undocumented.
The TLA Toolbox is a set of tools for writing and checking specifications.
In this post, I'll describe my experiences using these tools to understand how the vchan protocol works.
I run QubesOS on my laptop.
A QubesOS desktop environment is made up of multiple virtual machines.
A privileged VM, called dom0, provides the desktop environment and coordinates the other VMs.
dom0 doesn't have network access, so you have to use other VMs for doing actual work.
For example, I use one VM for email and another for development work (these are called "application VMs").
There is another VM (called sys-net) that connects to the physical network, and
yet another VM (sys-firewall) that connects the application VMs to net-vm.
My QubesOS desktop. The windows with blue borders are from my Debian development VM, while the green one is from a Fedora VM, etc.
The default sys-firewall is based on Fedora Linux.
A few years ago, I replaced sys-firewall with a MirageOS unikernel.
MirageOS is written in OCaml, and has very little C code (unlike Linux).
It boots much faster and uses much less RAM than the Fedora-based VM.
But recently, a user reported that restarting mirage-firewall was taking a very long time.
The problem seemed to be that it was taking several minutes to transfer the information about the network configuration to the firewall.
This is sent over vchan.
The user reported that stracing the QubesDB process in dom0 revealed that it was sleeping for 10 seconds
between sending the records, suggesting that a wakeup event was missing.
The lead developer of QubesOS said:
I'd guess missing evtchn trigger after reading/writing data in vchan.
Perhaps ocaml-vchan, the OCaml implementation of vchan, wasn't implementing the vchan specification correctly?
I wanted to check, but there was a problem: there was no vchan specification.
This library implements a bidirectional communication interface between
applications in different domains, similar to unix sockets. Data can be
sent using the byte-oriented libvchan_read/libvchan_write or the
packet-oriented libvchan_recv/libvchan_send.
Channel setup is done using a client-server model; domain IDs and a port
number must be negotiated prior to initialization. The server allocates
memory for the shared pages and determines the sizes of the
communication rings (which may span multiple pages, although the default
places rings and control within a single page).
With properly sized rings, testing has shown that this interface
provides speed comparable to pipes within a single Linux domain; it is
significantly faster than network-based communication.
I looked in the xen-devel mailing list around this period in case the reviewers had asked about how it worked.
Please could you say a few words about the functionality this new
library enables and perhaps the design etc? In particular a protocol
spec would be useful for anyone who wanted to reimplement for another
guest OS etc. [...]
I think it would be appropriate to add protocol.txt at the same time as
checking in the library.
However, the submitter pointed out that this was unnecessary, saying:
The comments in the shared header file explain the layout of the shared
memory regions; any other parts of the protocol are application-defined.
Now, ordinarily, I wouldn't be much interested in spending my free time
tracking down race conditions in 3rd-party libraries for the benefit of
strangers on the Internet. However, I did want to have another play with TLA...
TLA+
TLA+ is a language for specifying algorithms.
It can be used for many things, but it is particularly designed for stateful parallel algorithms.
I learned about TLA while working at Docker.
Docker EE provides software for managing large clusters of machines.
It includes various orchestrators (SwarmKit, Kubernetes and Swarm Classic) and
a web UI.
Ensuring that everything works properly is very important, and to this end
a large collection of tests had been produced.
Part of my job was to run these tests.
You take a test from a list in a web UI and click whatever buttons it tells you to click,
wait for some period of time,
and then check that what you see matches what the test says you should see.
There were a lot of these tests, and they all had to be repeated on every
supported platform, and for every release, release candidate or preview release.
There was a lot of waiting involved and not much thinking required, so to keep
my mind occupied, I started reading the TLA documentation.
I read The TLA+ Hyperbook and Specifying Systems.
Both are by Leslie Lamport (the creator of TLA), and are freely available online.
They're both very easy to read.
The hyperbook introduces the tools right away so you can start playing, while
Specifying Systems starts with more theory and discusses the tools later.
I think it's worth reading both.
Once Docker EE 2.0 was released,
we engineers were allowed to spend a week on whatever fun (Docker-related) project we wanted.
I used the time to read the SwarmKit design documents and make a TLA model of that.
I felt that using TLA prompted useful discussions with the SwarmKit developers
(which can see seen in the pull request comments).
A specification document can answer questions such as:
What does it do? (requirements / properties)
How does it do it? (the algorithm)
Does it work? (model checking)
Why does it work? (inductive invariant)
Does it really work? (proofs)
You don't have to answer all of them to have a useful document,
but I will try to answer each of them for vchan.
Is TLA useful?
In my (limited) experience with TLA, whenever I have reached the end of a specification
(whether reading it or writing it), I always find myself thinking "Well, that was obvious.
It hardly seems worth writing a spec for that!".
You might feel the same after reading this blog post.
To judge whether TLA is useful, I suggest you take a few minutes to look at the code.
If you are good at reading C code then you might find, like the Xen reviewers,
that it is quite obvious what it does, how it works, and why it is correct.
Or, like me, you might find you'd prefer a little help.
You might want to jot down some notes about it now, to see whether you learn anything new.
To give the big picture:
Two VMs decide to communicate over vchan. One will be the server and the other the client.
The server allocates three chunks of memory: one to hold data in transit from the client to
the server, one for data going from server to client, and the third to track information about
the state of the system. This includes counters saying how much data has been written and how
much read, in each direction.
The server tells Xen to grant the client access to this memory.
The client asks Xen to map the memory into its address space.
Now client and server can both access it at once.
There are no locks in the protocol, so be careful!
Either end sends data by writing it into the appropriate buffer and updating the appropriate counter
in the shared block. The buffers are ring buffers, so after getting to the end, you
start again from the beginning.
The data-written (producer) counter and the data-read (consumer) counter together
tell you how much data is in the buffer, and where it is.
When the difference is zero, the reader must stop reading and wait for more data.
When the difference is the size of the buffer, the writer must stop writing and wait for more space.
When one end is waiting, the other can signal it using a Xen event channel.
This essentially sets a pending flag to true at the other end, and wakes the VM if it is sleeping.
If a VM tries to sleep while it has an event pending, it will immediately wake up again.
Sending an event when one is already pending has no effect.
The public/io/libxenvchan.h header file provides some information,
including the shared structures and comments about them:
structring_shared{uint32_tcons,prod;};#define VCHAN_NOTIFY_WRITE 0x1#define VCHAN_NOTIFY_READ 0x2/** * vchan_interface: primary shared data structure */structvchan_interface{/** * Standard consumer/producer interface, one pair per buffer * left is client write, server read * right is client read, server write */structring_sharedleft,right;/** * size of the rings, which determines their location * 10 - at offset 1024 in ring's page * 11 - at offset 2048 in ring's page * 12+ - uses 2^(N-12) grants to describe the multi-page ring * These should remain constant once the page is shared. * Only one of the two orders can be 10 (or 11). */uint16_tleft_order,right_order;/** * Shutdown detection: * 0: client (or server) has exited * 1: client (or server) is connected * 2: client has not yet connected */uint8_tcli_live,srv_live;/** * Notification bits: * VCHAN_NOTIFY_WRITE: send notify when data is written * VCHAN_NOTIFY_READ: send notify when data is read (consumed) * cli_notify is used for the client to inform the server of its action */uint8_tcli_notify,srv_notify;/** * Grant list: ordering is left, right. Must not extend into actual ring * or grow beyond the end of the initial shared page. * These should remain constant once the page is shared, to allow * for possible remapping by a client that restarts. */uint32_tgrants[0];};
You might also like to look at the vchan source code.
Note that the libxenvchan.h file in this directory includes and extends
the above header file (with the same name).
For this blog post, we will ignore the Xen-specific business of sharing the memory
and telling the client where it is, and assume that the client has mapped the
memory and is ready to go.
Basic TLA concepts
We'll take a first look at TLA concepts and notation using a simplified version of vchan.
TLA comes with excellent documentation, so I won't try to make this a full tutorial,
but hopefully you will be able to follow the rest of this blog post after reading it.
We will just consider a single direction of the channel (e.g. client-to-server) here.
Variables, states and behaviour
A variable in TLA is just what a programmer expects: something that changes over time.
For example, I'll use Buffer to represent the data currently being transmitted.
We can also add variables that are just useful for the specification.
I use Sent to represent everything the sender-side application asked the vchan library to transmit,
and Got for everything the receiving application has received:
1
VARIABLESGot,Buffer,Sent
A state in TLA represents a snapshot of the world at some point.
It gives a value for each variable.
For example, { Got: "H", Buffer: "i", Sent: "Hi", ... } is a state.
The ... is just a reminder that a state also includes everything else in the world,
not just the variables we care about.
Here are some more states:
State
Got
Buffer
Sent
s0
s1
H
H
s2
H
H
s3
H
i
Hi
s4
Hi
Hi
s5
iH
Hi
A behaviour is a sequence of states, representing some possible history of the world.
For example, << s0, s1, s2, s3, s4 >> is a behaviour.
So is << s0, s1, s5 >>, but not one we want.
The basic idea in TLA is to specify precisely which behaviours we want and which we don't want.
A state expression is an expression that can be evaluated in the context of some state.
For example, this defines Integrity to be a state expression that is true whenever what we have got
so far matches what we wanted to send:
12345678
(* Take(m, i) is just the first i elements of message m. *)Take(m,i)==SubSeq(m,1,i)(* Everything except the first i elements of message m. *)Drop(m,i)==SubSeq(m,i+1,Len(m))Integrity==Take(Sent,Len(Got))=Got
Integrity is true for all the states above except for s5.
I added some helper operators Take and Drop here.
Sequences in TLA+ can be confusing because they are indexed from 1 rather than from 0,
so it is easy to make off-by-one errors.
These operators just use lengths, which we can all agree on.
In Python syntax, it would be written something like:
12
defIntegrity(s):returns.Sent.starts_with(s.Got)
A temporal formula is an expression that is evaluated in the context of a complete behaviour.
It can use the temporal operators, which include:
[] (that's supposed to look like a square) : "always"
<> (that's supposed to look like a diamond) : "eventually"
[] F is true if the expression F is true at every point in the behaviour.
<> F is true if the expression F is true at any point in the behaviour.
Messages we send should eventually arrive.
Here's one way to express that:
TLA syntax is a bit odd. It's rather like LaTeX (which is not surprising: Lamport is also the "La" in LaTeX).
\A means "for all" (rendered as an upside-down A).
So this says that for every number x, it is always true that if we have sent x bytes then
eventually we will have received at least x bytes.
This pattern of [] (F => <>G) is common enough that it has a shorter notation of F ~> G, which
is read as "F (always) leads to G". So, Availability can also be written as:
123
Availability==\Ax\inNat:Len(Sent)=x~>Len(Got)>=x
We're only checking the lengths in Availability, but combined with Integrity that's enough to ensure
that we eventually receive what we want.
So ideally, we'd like to ensure that every possible behaviour of the vchan library will satisfy
the temporal formula Properties:
12
Properties==Availability/\[]Integrity
That /\ is "and" by the way, and \/ is "or".
I did eventually start to be able to tell one from the other, though I still think && and || would be easier.
In case I forget to explain some syntax, A Summary of TLA lists most of it.
Actions
It is hopefully easy to see that Properties defines properties we want.
A user of vchan would be happy to see that these are things they can rely on.
But they don't provide much help to someone trying to implement vchan.
For that, TLA provides another way to specify behaviours.
An action in TLA is an expression that is evaluated in the context of a pair of states,
representing a single atomic step of the system.
For example:
The Read action is true of a step if that step transfers all the data from Buffer to Got.
Unprimed variables (e.g. Buffer) refer to the current state and primed ones (e.g. Buffer')
refer to the next state.
There's some more strange notation here too:
We're using /\ to form a bulleted list here rather than as an infix operator.
This is indentation-sensitive. TLA also supports \/ lists in the same way.
Actions correspond more closely to code than temporal formulas,
because they only talk about how the next state is related to the current one.
This action only allows one thing: reading the whole buffer at once.
In the C implementation of vchan the receiving application can provide a buffer of any size
and the library will read at most enough bytes to fill the buffer.
To model that, we will need a slightly more flexible version:
This says that a step is a Read step if there is any n (in the range 1 to the length of the buffer)
such that we transferred n bytes from the buffer. \E means "there exists ...".
A CONSTANT defines a parameter (input) of the specification
(it's constant in the sense that it doesn't change between states).
A Write operation adds some message m to the buffer, and also adds a copy of it to Sent
so we can talk about what the system is doing.
Seq(Byte) is the set of all possible sequences of bytes,
and \ {<< >>} just excludes the empty sequence.
A step of the combined system is either a Read step or a Write step:
12
Next==Read\/Write
We also need to define what a valid starting state for the algorithm looks like:
1234
Init==/\Sent=<<>>/\Buffer=<<>>/\Got=<<>>
Finally, we can put all this together to get a temporal formula for the algorithm:
[Next]_vars (that's Next in brackets with a subscript vars) means
Next \/ UNCHANGED vars.
Using Init (a state expression) in a temporal formula means it must be
true for the first state of the behaviour.
[][Action]_vars means that [Action]_vars must be true for each step.
TLA syntax requires the _vars subscript here.
This is because other things can be going on in the world beside our algorithm,
so it must always be possible to take a step without our algorithm doing anything.
Spec defines behaviours just like Properties does,
but in a way that makes it more obvious how to implement the protocol.
Correctness of Spec
Now we have definitions of Spec and Properties,
it makes sense to check that every behaviour of Spec satisfies Properties.
In Python terms, we want to check that all behaviours b satisfy this:
12
defSpecOK(b):returnSpec(b)=FalseorProperties(b)
i.e. either b isn't a behaviour that could result from the actions of our algorithm or,
if it is, it satisfies Properties. In TLA notation, we write this as:
12
SpecOK==Spec=>Properties
It's OK if a behaviour is allowed by Properties but not by Spec.
For example, the behaviour which goes straight from Got="", Sent="" to
Got="Hi", Sent="Hi" in one step meets our requirements, but it's not a
behaviour of Spec.
The real implementation may itself further restrict Spec.
For example, consider the behaviour << s0, s1, s2 >>:
State
Got
Buffer
Sent
s0
Hi
Hi
s1
H
i
Hi
s2
Hi
Hi
The sender sends two bytes at once, but the reader reads them one at a time.
This is a behaviour of the C implementation,
because the reading application can ask the library to read into a 1-byte buffer.
However, it is not a behaviour of the OCaml implementation,
which gets to choose how much data to return to the application and will return both bytes together.
That's fine.
We just need to show that OCamlImpl => Spec and Spec => Properties and we can deduce that
OCamlImpl => Properties.
This is, of course, the key purpose of a specification:
we only need to check that each implementation implements the specification,
not that each implementation directly provides the desired properties.
It might seem strange that an implementation doesn't have to allow all the specified behaviours.
In fact, even the trivial specification Spec == FALSE is considered to be a correct implementation of Properties,
because it has no bad behaviours (no behaviours at all).
But that's OK.
Once the algorithm is running, it must have some behaviour, even if that behaviour is to do nothing.
As the user of the library, you are responsible for checking that you can use it
(e.g. by ensuring that the Init conditions are met).
An algorithm without any behaviours corresponds to a library you could never use,
not to one that goes wrong once it is running.
The model checker
Now comes the fun part: we can ask TLC (the TLA model checker) to check that Spec => Properties.
You do this by asking the toolbox to create a new model (I called mine SpecOK) and setting Spec as the
"behaviour spec". It will prompt for a value for BufferSize. I used 2.
There will be various things to fix up:
To check Write, TLC first tries to get every possible Seq(Byte), which is an infinite set.
I defined MSG == Seq(Byte) and changed Write to use MSG.
I then added an alternative definition for MSG in the model so that we only send messages of limited length.
In fact, my replacement MSG ensures that Sent will always just be an incrementing sequence (<< 1, 2, 3, ... >>).
That's enough to check Properties, and much quicker than checking every possible message.
The system can keep sending forever. I added a state constraint to the model: Len(Sent) < 4
This tells TLC to stop considering any execution once this becomes false.
With that, the model runs successfully.
This is a nice feature of TLA: instead of changing our specification to make it testable,
we keep the specification correct and just override some aspects of it in the model.
So, the specification says we can send any message, but the model only checks a few of them.
Now we can add Integrity as an invariant to check.
That passes, but it's good to double-check by changing the algorithm.
I changed Read so that it doesn't clear the buffer, using Buffer' = Drop(Buffer, 0)
(with 0 instead of n).
Then TLC reports a counter-example ("Invariant Integrity is violated"):
The sender writes << 1, 2 >> to Buffer.
The reader reads one byte, to give Got=1, Buffer=12, Sent=12.
The reader reads another byte, to give Got=11, Buffer=12, Sent=12.
Looks like it really was checking what we wanted.
It's good to be careful. If we'd accidentally added Integrity as a "property" to check rather than
as an "invariant" then it would have interpreted it as a temporal formula and reported success just because
it is true in the initial state.
One really nice feature of TLC is that (unlike a fuzz tester) it does a breadth-first search and therefore
finds minimal counter-examples for invariants.
The example above is therefore the quickest way to violate Integrity.
Checking Availability complains because of the use of Nat (we're asking it to check for every possible
length).
I replaced the Nat with AvailabilityNat and overrode that to be 0..4 in the model.
It then complains "Temporal properties were violated" and shows an example where the sender wrote
some data and the reader never read it.
The problem is, [Next]_vars always allows us to do nothing.
To fix this, we can specify a "weak fairness" constraint.
WF_vars(action), says that we can't just stop forever with action being always possible but never happening.
I updated Spec to require the Read action to be fair:
1
Spec==Init/\[][Next]_vars/\WF_vars(Read)
Again, care is needed here.
If we had specified WF_vars(Next) then we would be forcing the sender to keep sending forever, which users of vchan are not required to do.
Worse, this would mean that every possible behaviour of the system would result in Sent growing forever.
Every behaviour would therefore hit our Len(Sent) < 4 constraint and
TLC wouldn't consider it further.
That means that TLC would never check any actual behaviour against Availability,
and its reports of success would be meaningless!
Changing Read to require n \in 2..Len(Buffer) is a quick way to see that TLC is actually checking Availability.
The simple Spec algorithm above has some limitations.
One obvious simplification is that Buffer is just the sequence of bytes in transit, whereas in the real system it is a ring buffer, made up of an array of bytes along with the producer and consumer counters.
We could replace it with three separate variables to make that explicit.
However, ring buffers in Xen are well understood and I don't feel that it would make the specification any clearer
to include that.
A more serious problem is that Spec assumes that there is a way to perform the Read and Write operations atomically.
Otherwise the real system would have behaviours not covered by the spec.
To implement the above Spec correctly, you'd need some kind of lock.
The real vchan protocol is more complicated than Spec, but avoids the need for a lock.
The real system has more shared state than just Buffer.
I added extra variables to the spec for each item of shared state in the C code, along with its initial value:
SenderLive = TRUE (sender sets to FALSE to close connection)
ReceiverLive = TRUE (receiver sets to FALSE to close connection)
NotifyWrite = TRUE (receiver wants to be notified of next write)
DataReadyInt = FALSE (sender has signalled receiver over event channel)
NotifyRead = FALSE (sender wants to be notified of next read)
SpaceAvailableInt = FALSE (receiver has notified sender over event channel)
DataReadyInt represents the state of the receiver's event port.
The sender can make a Xen hypercall to set this and wake (or interrupt) the receiver.
I guess sending these events is somewhat slow,
because the NotifyWrite system is used to avoid sending events unnecessarily.
Likewise, SpaceAvailableInt is the sender's event port.
The algorithm
Here is my understanding of the protocol. On the sending side:
The sending application asks to send some bytes.
We check whether the receiver has closed the channel and abort if so.
We check the amount of buffer space available.
If there isn't enough, we set NotifyRead so the receiver will notify us when there is more.
We also check the space again after this, in case it changed while setting the flag.
If there is any space:
We write as much data as we can to the buffer.
If the NotifyWrite flag is set, we clear it and notify the receiver of the write.
If we wrote everything, we return success.
Otherwise, we wait to be notified of more space.
We check whether the receiver has closed the channel.
If so we abort. Otherwise, we go back to step 2.
On the receiving side:
The receiving application asks us to read up to some amount of data.
We check the amount of data available in the buffer.
If there isn't as much as requested, we set NotifyWrite so the sender will notify us when there is.
We also check the space again after this, in case it changed while setting the flag.
If there is any data, we read up to the amount requested.
If the NotifyRead flag is set, we clear it and notify the sender of the new space.
We return success to the application (even if we didn't get as much as requested).
Otherwise (if there was no data), we check whether the sender has closed the connection.
If not (if the connection is still open), we wait to be notified of more data,
and then go back to step 2.
Either side can close the connection by clearing their "live" flag and signalling
the other side. I assumed there is also some process-local way that the close operation
can notify its own side if it's currently blocked.
To make expressing this kind of step-by-step algorithm easier,
TLA+ provides a programming-language-like syntax called PlusCal.
It then translates PlusCal into TLA actions.
Confusingly, there are two different syntaxes for PlusCal: Pascal style and C style.
This means that, when you search for examples on the web,
there is a 50% chance they won't work because they're using the other flavour.
I started with the Pascal one because that was the first example I found, but switched to C-style later because it was more compact.
Here is my attempt at describing the sender algorithm above in PlusCal:
fairprocess(SenderWrite=SenderWriteID)variablesfree=0,\* Our idea of how much free space is available.msg=<<>>,\* The data we haven't sent yet.Sent=<<>>;\* Everything we were asked to send.{sender_ready:-while(TRUE){if(~SenderLive\/~ReceiverLive)gotoDoneelse{with(m\inMSG){msg:=m};Sent:=Sent\omsg;\* Remember we wanted to send this};sender_write:while(TRUE){free:=BufferSize-Len(Buffer);sender_request_notify:if(free>=Len(msg))gotosender_write_dataelseNotifyRead:=TRUE;sender_recheck_len:free:=BufferSize-Len(Buffer);sender_write_data:if(free>0){Buffer:=Buffer\oTake(msg,Min(Len(msg),free));msg:=Drop(msg,Min(Len(msg),free));free:=0;sender_check_notify_data:if(NotifyWrite){NotifyWrite:=FALSE;\* Atomic test-and-clearsender_notify_data:DataReadyInt:=TRUE;\* Signal receiverif(msg=<<>>)gotosender_ready}elseif(msg=<<>>)gotosender_ready};sender_blocked:awaitSpaceAvailableInt\/~SenderLive;if(~SenderLive)gotoDone;elseSpaceAvailableInt:=FALSE;sender_check_recv_live:if(~ReceiverLive)gotoDone;}}}
The labels (e.g. sender_request_notify:) represent points in the program where other actions can happen.
Everything between two labels is considered to be atomic.
I checked that every block of code between labels accesses only one shared variable.
This means that the real system can't see any states that we don't consider.
The toolbox doesn't provide any help with this; you just have to check manually.
The sender_ready label represents a state where the client application hasn't yet decided to send any data.
Its label is tagged with - to indicate that fairness doesn't apply here, because the protocol doesn't
require applications to keep sending more data forever.
The other steps are fair, because once we've decided to send something we should keep going.
Taking a step from sender_ready to sender_write corresponds to the vchan library's write function
being called with some argument m.
The with (m \in MSG) says that m could be any message from the set MSG.
TLA also contains a CHOOSE operator that looks like it might do the same thing, but it doesn't.
When you use with, you are saying that TLC should check all possible messages.
When you use CHOOSE, you are saying that it doesn't matter which message TLC tries (and it will always try the
same one).
Or, in terms of the specification, a CHOOSE would say that applications can only ever send one particular message, without telling you what that message is.
In sender_write_data, we set free := 0 for no obvious reason.
This is just to reduce the number of states that the model checker needs to explore,
since we don't care about its value after this point.
Some of the code is a little awkward because I had to put things in else branches that would more naturally go after the whole if block, but the translator wouldn't let me do that.
The use of semi-colons is also a bit confusing: the PlusCal-to-TLA translator requires them after a closing brace in some places, but the PDF generator messes up the indentation if you include them.
Here's how the code block starting at sender_request_notify gets translated into a TLA action:
pc is a mapping from process ID to the label where that process is currently executing.
So sender_request_notify can only be performed when the SenderWriteID process is
at the sender_request_notify label.
Afterwards pc[SenderWriteID] will either be at sender_write_data or sender_recheck_len
(if there wasn't enough space for the whole message).
fairprocess(ReceiverRead=ReceiverReadID)variableshave=0,\* The amount of data we think the buffer contains.want=0,\* The amount of data the user wants us to read.Got=<<>>;\* Pseudo-variable recording all data ever received by receiver.{recv_ready:while(ReceiverLive){with(n\in1..MaxReadLen)want:=n;recv_reading:while(TRUE){have:=Len(Buffer);recv_got_len:if(have>=want)gotorecv_read_dataelseNotifyWrite:=TRUE;recv_recheck_len:have:=Len(Buffer);recv_read_data:if(have>0){Got:=Got\oTake(Buffer,Min(want,have));Buffer:=Drop(Buffer,Min(want,have));want:=0;have:=0;recv_check_notify_read:if(NotifyRead){NotifyRead:=FALSE;\* (atomic test-and-clear)recv_notify_read:SpaceAvailableInt:=TRUE;gotorecv_ready;\* Return success}elsegotorecv_ready;\* Return success}elseif(~SenderLive\/~ReceiverLive){gotoDone;};recv_await_data:awaitDataReadyInt\/~ReceiverLive;if(~ReceiverLive){want:=0;gotoDone}elseDataReadyInt:=FALSE;}}}
It's quite similar to before.
recv_ready corresponds to a state where the application hasn't yet called read.
When it does, we take n (the maximum number of bytes to read) as an argument and
store it in the local variable want.
Note: you can use the C library in blocking or non-blocking mode.
In blocking mode, a write (or read) waits until data is sent (or received).
In non-blocking mode, it returns a special code to the application indicating that it needs to wait.
The application then does the waiting itself and then calls the library again.
I think the specification above covers both cases, depending on whether you think of
sender_blocked and recv_await_data as representing code inside or outside of the library.
We also need a way to close the channel.
It wasn't clear to me, from looking at the C headers, when exactly you're allowed to do that.
I think that if you had a multi-threaded program and you called the close function while the write
function was blocked, it would unblock and return.
But if you happened to call it at the wrong time, it would try to use a closed file descriptor and fail
(or read from the wrong one).
So I guess it's single threaded, and you should use the non-blocking mode if you want to cancel things.
That means that the sender can close only when it is at sender_ready or sender_blocked,
and similarly for the receiver.
The situation with the OCaml code is the same, because it is cooperatively threaded and so the close
operation can only be called while blocked or idle.
However, I decided to make the specification more general and allow for closing at any point
by modelling closing as separate processes:
123456789
fairprocess(SenderClose=SenderCloseID){sender_open:-SenderLive:=FALSE;\* Clear liveness flagsender_notify_closed:DataReadyInt:=TRUE;\* Signal receiver}fairprocess(ReceiverClose=ReceiverCloseID){recv_open:-ReceiverLive:=FALSE;\* Clear liveness flagrecv_notify_closed:SpaceAvailableInt:=TRUE;\* Signal sender}
Again, the processes are "fair" because once we start closing we should finish,
but the initial labels are tagged with "-" to disable fairness there: it's OK if
you keep a vchan open forever.
There's a slight naming problem here.
The PlusCal translator names the actions it generates after the starting state of the action.
So sender_open is the action that moves from the sender_open label.
That is, the sender_open action actually closes the connection!
Finally, we share the event channel with the buffer going in the other direction, so we might
get notifications that are nothing to do with us.
To ensure we handle that, I added another process that can send events at any time:
either/or says that we need to consider both possibilities.
This process isn't marked fair, because we can't rely these interrupts coming.
But we do have to handle them when they happen.
Testing the full spec
PlusCal code is written in a specially-formatted comment block, and you have to press Ctrl-T to
generate (or update) then TLA translation before running the model checker.
Be aware that the TLA Toolbox is a bit unreliable about keyboard short-cuts.
While typing into the editor always works, short-cuts such as Ctrl-S (save) sometimes get disconnected.
So you think you're doing "edit/save/translate/save/check" cycles, but really you're just checking some old version over and over again.
You can avoid this by always running the model checker with the keyboard shortcut too, since that always seems to fail at the same time as the others.
Focussing a different part of the GUI and then clicking back in the editor again fixes everything for a while.
Anyway, running our model on the new spec shows that Integrity is still OK.
However, the Availability check fails with the following counter-example:
The sender writes << 1 >> to Buffer.
The sender closes the connection.
The receiver closes the connection.
All processes come to a stop, but the data never arrived.
We need to update Availability to consider the effects of closing connections.
And at this point, I'm very unsure what vchan is intended to do.
We could say:
That passes.
But vchan describes itself as being like a Unix socket.
If you write to a Unix socket and then close it, you still expect the data to be delivered.
So actually I tried this:
This says that if a sender write operation completes successfully (we're back at sender_ready)
and at that point the sender hasn't closed the connection, then the receiver will eventually receive
the data (or close its end).
That is how I would expect it to behave.
But TLC reports that the new spec does not satisfy this, giving this example (simplified - there are 16 steps in total):
The receiver starts reading. It finds that the buffer is empty.
The sender writes some data to Buffer and returns to sender_ready.
The sender closes the channel.
The receiver sees that the connection is closed and stops.
Is this a bug? Without a specification, it's impossible to say.
Maybe vchan was never intended to ensure delivery once the sender has closed its end.
But this case only happens if you're very unlucky about the scheduling.
If the receiving application calls read when the sender has closed the connection but there is data
available then the C code does return the data in that case.
It's only if the sender happens to close the connection just after the receiver has checked the buffer and just before it checks the close flag that this happens.
It's also easy to fix.
I changed the code in the receiver to do a final check on the buffer before giving up:
With that change, we can be sure that data sent while the connection is open will always be delivered
(provided only that the receiver doesn't close the connection itself).
If you spotted this issue yourself while you were reviewing the code earlier, then well done!
Note that when TLC finds a problem with a temporal property (such as Availability),
it does not necessarily find the shortest example first.
I changed the limit on Sent to Len(Sent) < 2 and added an action constraint of ~SpuriousInterrupts
to get a simpler example, with only 1 byte being sent and no spurious interrupts.
Some odd things
I noticed a couple of other odd things, which I thought I'd mention.
First, NotifyWrite is initialised to TRUE, which seemed unnecessary.
We can initialise it to FALSE instead and everything still works.
We can even initialise it with NotifyWrite \in {TRUE, FALSE} to allow either behaviour,
and thus test that old programs that followed the original version of the spec still work
with either behaviour.
That's a nice advantage of using a specification language.
Saying "the code is the spec" becomes less useful as you build up more and more versions of the code!
However, because there was no spec before, we can't be sure that existing programs do follow it.
And, in fact, I found that QubesDB uses the vchan library in a different and unexpected way.
Instead of calling read, and then waiting if libvchan says to, QubesDB blocks first in all cases, and
then calls the read function once it gets an event.
We can document that by adding an extra step at the start of ReceiverRead:
12345
recv_init:eithergotorecv_ready\* (recommended)or{\* (QubesDB does this)with(n\in1..MaxReadLen)want:=n;gotorecv_await_data;};
Then TLC shows that NotifyWrite cannot start as FALSE.
The second odd thing is that the receiver sets NotifyRead whenever there isn't enough data available
to fill the application's buffer completely.
But usually when you do a read operation you just provide a buffer large enough for the largest likely message.
It would probably make more sense to set NotifyWrite only when the buffer is completely empty.
After checking the current version of the algorithm, I changed the specification to allow either behaviour.
Why does vchan work?
At this point, we have specified what vchan should do and how it does it.
We have also checked that it does do this, at least for messages up to 3 bytes long with a buffer size of 2.
That doesn't sound like much, but we still checked 79,288 distinct states, with behaviours up to 38 steps long.
This would be a perfectly reasonable place to declare the specification (and blog post) finished.
However, TLA has some other interesting abilities.
In particular, it provides a very interesting technique to help discover why the algorithm works.
We'll start with Integrity.
We would like to argue as follows:
Integrity is true in any initial state (i.e. Init => Integrity).
Any Next step preserves Integrity (i.e. Integrity /\ Next => Integrity').
Then it would just be a matter looking at each possible action that makes up Next and
checking that each one individually preserves Integrity.
However, we can't do this with Integrity because (2) isn't true.
For example, the state { Got: "", Buffer: "21", Sent: "12" } satisfies Integrity,
but if we take a read step then the new state won't.
Instead, we have to argue "If we take a Next step in any reachable state then Integrity'",
but that's very difficult because how do we know whether a state is reachable without searching them all?
So the idea is to make a stronger version of Integrity, called IntegrityI, which does what we want.
IntegrityI is called an inductive invariant.
The first step is fairly obvious - I began with:
12
IntegrityI==Sent=Got\oBuffer\omsg
Integrity just said that Got is a prefix of Sent.
This says specifically that the rest is Buffer \o msg - the data currently being transmitted and the data yet to be transmitted.
We can ask TLC to check Init /\ [][Next]_vars => []IntegrityI to check that it is an invariant, as before.
It does that by finding all the Init states and then taking Next steps to find all reachable states.
But we can also ask it to check IntegrityI /\ [][Next]_vars => []IntegrityI.
That is, the same thing but starting from any state matching IntegrityI instead of Init.
I created a new model (IntegrityI) to do that.
It reports a few technical problems at the start because it doesn't know the types of anything.
For example, it can't choose initial values for SenderLive without knowing that SenderLive is a boolean.
I added a TypeOK state expression that gives the expected type of every variable:
You might imagine that the PlusCal translator would generate that for you, but it doesn't.
We also need to override MESSAGE with FINITE_MESSAGE(n) for some n (I used 2).
Otherwise, it can't enumerate all possible messages.
Now we have:
1234
IntegrityI==/\TypeOK/\PCOK/\Sent=Got\oBuffer\omsg
With that out of the way, TLC starts finding real problems
(that is, examples showing that IntegrityI /\ Next => IntegrityI' isn't true).
First, recv_read_data would do an out-of-bounds read if have = 1 and Buffer = << >>.
Our job is to explain why that isn't a valid state.
We can fix it with an extra constraint:
(note: that => is "implies", while the <= is "less-than-or-equal-to")
Now it complains that if we do recv_got_len with Buffer = << >>, have = 1, want = 0 then we end up in recv_read_data with
Buffer = << >>, have = 1, and we have to explain why that can't happen and so on.
Because TLC searches breadth-first, the examples it finds never have more than 2 states.
You just have to explain why the first state can't happen in the real system.
Eventually, you get a big ugly pile of constraints, which you then think about for a bit and simply.
I ended up with:
It's a good idea to check the final IntegrityI with the original SpecOK model,
just to check it really is an invariant.
So, in summary, Integrity is always true because:
Sent is always the concatenation of Got, Buffer and msg.
That's fairly obvious, because sender_ready sets msg and appends the same thing to Sent,
and the other steps (sender_write_data and recv_read_data) just transfer some bytes from
the start of one variable to the end of another.
Although, like all local information, the receiver's have variable might be out-of-date,
there must be at least that much data in the buffer, because the sender process will only
have added more, not removed any. This is sufficient to ensure that we never do an
out-of-range read.
Likewise, the sender's free variable is a lower bound on the true amount of free space,
because the receiver only ever creates more space. We will therefore never write beyond the
free space.
I think this ability to explain why an algorithm works, by being shown examples where the inductive property
doesn't hold, is a really nice feature of TLA.
Inductive invariants are useful as a first step towards writing a proof,
but I think they're valuable even on their own.
If you're documenting your own algorithm,
this process will get you to explain your own reasons for believing it works
(I tried it on a simple algorithm in my own code and it seemed helpful).
Some notes:
Originally, I had the free and have constraints depending on pc.
However, the algorithm sets them to zero when not in use so it turns out they're always true.
IntegrityI matches 532,224 states, even with a maximum Sent length of 1, but it passes!
There are some games you can play to speed things up;
see Using TLC to Check Inductive Invariance for some suggestions
(I only discovered that while writing this up).
Proving Integrity
TLA provides a syntax for writing proofs,
and integrates with TLAPS (the TLA+ Proof System) to allow them to be checked automatically.
Proving IntegrityI is just a matter of showing that Init => IntegrityI and that it is preserved
by any possible [Next]_vars step.
To do that, we consider each action of Next individually, which is long but simple enough.
I was able to prove it, but the recv_read_data action was a little difficult
because we don't know that want > 0 at that point, so we have to do some extra work
to prove that transferring 0 bytes works, even though the real system never does that.
I therefore added an extra condition to IntegrityI that want is non-zero whenever it's in use,
and also conditions about have and free being 0 when not in use, for completeness:
Integrity was quite easy to prove, but I had more trouble trying to explain Availability.
One way to start would be to add Availability as a property to check to the IntegrityI model.
However, it takes a while to check properties as it does them at the end, and the examples
it finds may have several steps (it took 1m15s to find a counter-example for me).
Here's a faster way (37s).
The algorithm will deadlock if both sender and receiver are in their blocked states and neither
interrupt is pending, so I made a new invariant, I, which says that deadlock can't happen:
I discovered some obvious facts about closing the connection.
For example, the SenderLive flag is set if and only if the sender's close thread hasn't done anything.
I've put them all together in CloseOK:
123456789101112
(* Some obvious facts about shutting down connections. *)CloseOK==\* An endpoint is live iff its close thread hasn't done anything:/\pc[SenderCloseID]="sender_open"<=>SenderLive/\pc[ReceiverCloseID]="recv_open"<=>ReceiverLive\* The send and receive loops don't terminate unless someone has closed the connection:/\pc[ReceiverReadID]\in{"recv_final_check","Done"}=>~ReceiverLive\/~SenderLive/\pc[SenderWriteID]\in{"Done"}=>~ReceiverLive\/~SenderLive\* If the receiver closed the connection then we will get (or have got) the signal:/\pc[ReceiverCloseID]="Done"=>\/SpaceAvailableInt\/pc[SenderWriteID]\in{"sender_check_recv_live","Done"}
But I had problems with other examples TLC showed me, and
I realised that I didn't actually know why this algorithm doesn't deadlock.
Intuitively it seems clear enough:
the sender puts data in the buffer when there's space and notifies the receiver,
and the receiver reads it and notifies the writer.
What could go wrong?
But both processes are working with information that can be out-of-date.
By the time the sender decides to block because the buffer looked full, the buffer might be empty.
And by the time the receiver decides to block because it looked empty, it might be full.
Maybe you already saw why it works from the C code, or the algorithm above,
but it took me a while to figure it out!
I eventually ended up with an invariant of the form:
SendMayBlock is TRUE if we're in a state that may lead to being blocked without checking the
buffer's free space again. Likewise, ReceiveMayBlock indicates that the receiver might block.
SpaceWakeupComing and DataWakeupComing predict whether we're going to get an interrupt.
The idea is that if we're going to block, we need to be sure we'll be woken up.
It's a bit ugly, though, e.g.
1234567891011121314
DataWakeupComing==\/DataReadyInt\* Event sent\/pc[SenderWriteID]="sender_notify_data"\* Event being sent\/pc[SenderCloseID]="sender_notify_closed"\/pc[ReceiverCloseID]="recv_notify_closed"\//\NotifyWrite\* Event requested and .../\ReceiverLive\* Sender can see receiver is still alive and .../\\/pc[SenderWriteID]="sender_write_data"/\free>0\/pc[SenderWriteID]="sender_check_notify_data"\/pc[SenderWriteID]="sender_recheck_len"/\Len(Buffer)<BufferSize\/pc[SenderWriteID]="sender_ready"/\SenderLive/\Len(Buffer)<BufferSize\/pc[SenderWriteID]="sender_write"/\Len(Buffer)<BufferSize\/pc[SenderWriteID]="sender_request_notify"/\Len(Buffer)<BufferSize\/SpaceWakeupComing/\Len(Buffer)<BufferSize/\SenderLive
It did pass my model that tested sending one byte, and I decided to try a proof.
Well, it didn't work.
The problem seems to be that DataWakeupComing and SpaceWakeupComing are really mutually recursive.
The reader will wake up if the sender wakes it, but the sender might be blocked, or about to block.
That's OK though, as long as the receiver will wake it, which it will do, once the sender wakes it...
You've probably already figured it out, but I thought I'd document my confusion.
It occurred to me that although each process might have out-of-date information,
that could be fine as long as at any one moment one of them was right.
The last process to update the buffer must know how full it is,
so one of them must have correct information at any given time, and that should be enough to avoid deadlock.
That didn't work either.
When you're at a proof step and can't see why it's correct, you can ask TLC to show you an example.
e.g. if you're stuck trying to prove that sender_request_notify preserves I when the
receiver is at recv_ready, the buffer is full, and ReceiverLive = FALSE,
you can ask for an example of that:
You then create a new model that searches Example /\ [][Next]_vars and tests I.
As long as Example has several constraints, you can use a much larger model for this.
I also ask it to check the property [][FALSE]_vars, which means it will show any step starting from Example.
It quickly became clear what was wrong: it is quite possible that neither process is up-to-date.
If both processes see the buffer contains X bytes of data, and the sender sends Y bytes and the receiver reads Z bytes, then the sender will think there are X + Y bytes in the buffer and the receiver will think there are X - Z bytes, and neither is correct.
My original 1-byte buffer was just too small to find a counter-example.
The real reason why vchan works is actually rather obvious.
I don't know why I didn't see it earlier.
But eventually it occurred to me that I could make use of Got and Sent.
I defined WriteLimit to be the total number of bytes that the sender would write before blocking,
if the receiver never did anything further.
And I defined ReadLimit to be the total number of bytes that the receiver would read if the sender
never did anything else.
Did I define these limits correctly?
It's easy to ask TLC to check some extra properties while it's running.
For example, I used this to check that ReadLimit behaves sensibly:
123456789
ReadLimitCorrect==\* We will eventually receive what ReadLimit promises:/\WF_vars(ReceiverRead)=>\Ai\inAvailabilityNat:ReadLimit=i~>Len(Got)>=i\/~ReceiverLive\* ReadLimit can only decrease if we decide to shut down:/\[][ReadLimit'>=ReadLimit\/~ReceiverLive]_vars\* ReceiverRead steps don't change the read limit:/\[][ReceiverRead=>UNCHANGEDReadLimit\/~ReceiverLive]_vars
Because ReadLimit is defined in terms of what it does when no other processes run,
this property should ideally be tested in a model without the fairness conditions
(i.e. just Init /\ [][Next]_vars).
Otherwise, fairness may force the sender to perform a step.
We still want to allow other steps, though, to show that ReadLimit is a lower bound.
With this, we can argue that e.g. a 2-byte buffer will eventually transfer 3 bytes:
The receiver will eventually read 3 bytes as long as the sender eventually sends 3 bytes.
The sender will eventually send 3, if the receiver reads at least 1.
The receiver will read 1 if the sender sends at least 1.
The sender will send 1 if the reader has read at least 0 bytes, which is always true.
By this point, I was learning to be more cautious before trying a proof,
so I added some new models to check this idea further.
One prevents the sender from ever closing the connection and the other prevents the receiver from ever closing.
That reduces the number of states to consider and I was able to check a slightly larger model.
12345678910111213141516171819202122
I==/\IntegrityI/\CloseOK\* If the reader is stuck, but data is available, the sender will unblock it:/\ReaderShouldBeUnblocked=>\* The sender is going to write more:\/WriteLimit>Len(Got)+Len(Buffer)/\Len(msg)>0/\SenderLive\* The sender is about to increase ReadLimit:\/(\/pc[SenderWriteID]="sender_check_notify_data"/\NotifyWrite\/pc[SenderWriteID]="sender_notify_data")/\ReadLimit<Len(Got)+Len(Buffer)\* The sender is about to notify us of shutdown:\/pc[SenderCloseID]\in{"sender_notify_closed"}\* If the writer is stuck, but there is now space available, the receiver will unblock it:/\WriterShouldBeUnblocked=>\* The reader is going to read more:\/ReadLimit>Len(Got)/\ReceiverLive\* The reader is about to increase WriteLimit:\/(\/pc[ReceiverReadID]="recv_check_notify_read"/\NotifyRead\/pc[ReceiverReadID]="recv_notify_read")/\WriteLimit<Len(Got)+BufferSize\* The receiver is about to notify us of shutdown:\/pc[ReceiverCloseID]\in{"recv_notify_closed"}/\NotifyFlagsCorrect
If a process is on a path to being blocked then it must have set its notify flag.
NotifyFlagsCorrect says that in that case, the flag it still set, or the interrupt has been sent,
or the other process is just about to trigger the interrupt.
I managed to use that to prove that the sender's steps preserved I,
but I needed a little extra to finish the receiver proof.
At this point, I finally spotted the obvious invariant (which you, no doubt, saw all along):
whenever NotifyRead is still set, the sender has accurate information about the buffer.
12345
/\NotifyRead=>\* The sender has accurate information about the buffer:\/WriteLimit=Len(Got)+BufferSize\* Or the flag is being cleared right now:\/pc[ReceiverReadID]="recv_check_notify_read"
That's pretty obvious, isn't it?
The sender checks the buffer after setting the flag, so it must have accurate information at that point.
The receiver clears the flag after reading from the buffer (which invalidates the sender's information).
Now I had a dilemma.
There was obviously going to be a matching property about NotifyWrite.
Should I add that, or continue with just this?
I was nearly done, so I continued and finished off the proofs.
With I proved, I was able to prove some other nice things quite easily:
That says that whenever the receiver is blocked, the sender can fill the buffer.
That's pretty nice.
It would be possible to make a vchan system that e.g. could only send 1 byte at a time and still
prove it couldn't deadlock and would always deliver data,
but here we have shown that the algorithm can use the whole buffer.
At least, that's what these theorems say as long as you believe that ReadLimit and WriteLimit are defined correctly.
With the proof complete, I then went back and deleted all the stuff about ReadLimit and WriteLimit from I
and started again with just the new rules about NotifyRead and NotifyWrite.
Instead of using WriteLimit = Len(Got) + BufferSize to indicate that the sender has accurate information,
I made a new SenderInfoAccurate that just returns TRUE whenever the sender will fill the buffer without further help.
That avoids some unnecessary arithmetic, which TLAPS needs a lot of help with.
1234567891011121314151617
(* The sender's information is accurate if whenever it is going to block, the buffer really is full. *)SenderInfoAccurate==\* We have accurate information:\/Len(Buffer)+free=BufferSize\* In these states, we're going to check the buffer before blocking:\/pc[SenderWriteID]\in{"sender_ready","sender_request_notify","sender_write","sender_recheck_len","sender_check_recv_live","Done"}\/pc[SenderWriteID]\in{"sender_request_notify"}/\free<Len(msg)\* If we've been signalled, we'll immediately wake next time we try to block:\/SpaceAvailableInt\* We're about to write some data:\//\pc[SenderWriteID]\in{"sender_write_data"}/\free>=Len(msg)\* But we won't need to block\* If we wrote all the data we intended to, we'll return without blocking:\//\pc[SenderWriteID]\in{"sender_check_notify_data","sender_notify_data"}/\Len(msg)=0
By talking about accuracy instead of the write limit, I was also able to include "Done" in with
the other happy cases.
Before, that had to be treated as a possible problem because the sender can't use the full buffer when it's Done.
With this change, the proof of Spec => []I became much simpler (384 lines shorter).
And most of the remaining steps were trivial.
The ReadLimit and WriteLimit idea still seemed useful, though,
but I found I was able to prove the same things from I.
e.g. we can still conclude this, even if I doesn't mention WriteLimit:
That's nice, because it keeps the invariant and its proofs simple,
but we still get the same result in the end.
I initially defined WriteLimit to be the number of bytes the sender could write if
the sending application wanted to send enough data,
but I later changed it to be the actual number of bytes it would write if the application didn't
try to send any more.
This is because otherwise, with packet-based sends
(where we only write when the buffer has enough space for the whole message at once)
WriteLimit could go down.
e.g. we think we can write another 3 bytes,
but then the application decides to write 10 bytes and now we can't write anything more.
The limit theorems above are useful properties,
but it would be good to have more confidence that ReadLimit and WriteLimit are correct.
I was able to prove some useful lemmas here.
First, ReceiverRead steps don't change ReadLimit (as long as the receiver hasn't closed
the connection):
This gives us a good reason to think that ReadLimit is correct:
When the receiver is blocked it cannot read any more than it has without help.
ReadLimit is defined to be Len(Got) then, so ReadLimit is obviously correct for this case.
Since read steps preserve ReadLimit, this shows that ReadLimit is correct in all cases.
e.g. if ReadLimit = 5 and no other processes do anything,
then we will end up in a state with the receiver blocked, and ReadLimit = Len(Got) = 5
and so we really did read a total of 5 bytes.
I was also able to prove that it never decreases (unless the receiver closes the connection):
So, if ReadLimit = n then it will always be at least n,
and if the receiver ever blocks then it will have read at least n bytes.
I was able to prove similar properties about WriteLimit.
So, I feel reasonably confident that these limit predictions are correct.
Disappointingly, we can't actually prove Availability using TLAPS,
because currently it understands very little temporal logic (see TLAPS limitations).
However, I could show that the system can't deadlock while there's data to be transmitted:
(* We can't get into a state where the sender and receiver are both blocked and there is no wakeup pending: *)THEOREMDeadlockFree1==ASSUMEIPROVE~/\pc[SenderWriteID]="sender_blocked"/\~SpaceAvailableInt/\SenderLive/\pc[ReceiverReadID]="recv_await_data"/\~DataReadyInt/\ReceiverLive<1>SUFFICESASSUME/\pc[SenderWriteID]="sender_blocked"/\~SpaceAvailableInt/\SenderLive/\pc[ReceiverReadID]="recv_await_data"/\~DataReadyInt/\ReceiverLivePROVEFALSEOBVIOUS<1>NotifyFlagsCorrectBYDEFI<1>NotifyReadBYDEFNotifyFlagsCorrect<1>NotifyWrite<2>have=0BYDEFIntegrityI,I<2>QEDBYDEFNotifyFlagsCorrect<1>SenderInfoAccurate/\ReaderInfoAccurateBYDEFI<1>free=0BYDEFIntegrityI,I<1>Len(Buffer)=BufferSizeBYDEFSenderInfoAccurate<1>Len(Buffer)=0BYDEFReaderInfoAccurate<1>QEDBYBufferSizeType(* We can't get into a state where the sender is idle and the receiver is blocked unless the buffer is empty (all data sent has been consumed): *)THEOREMDeadlockFree2==ASSUMEI,pc[SenderWriteID]="sender_ready",SenderLive,pc[ReceiverReadID]="recv_await_data",ReceiverLive,~DataReadyIntPROVELen(Buffer)=0
I've included the proof of DeadlockFree1 above:
To show deadlock can't happen, it suffices to assume it has happened and show a contradiction.
If both processes are blocked then NotifyRead and NotifyWrite must both be set
(because processes don't block without setting them,
and if they'd been unset then an interrupt would now be pending and we wouldn't be blocked).
Since NotifyRead is still set,
the sender is correct in thinking that the buffer is still full.
Since NotifyWrite is still set,
the receiver is correct in thinking that the buffer is still empty.
That would be a contradiction, since BufferSize isn't zero.
If it doesn't deadlock, then some process must keep getting woken up by interrupts,
which means that interrupts keep being sent.
We only send interrupts after making progress (writing to the buffer or reading from it),
so we must keep making progress.
We'll have to content ourselves with that argument.
Experiences with TLAPS
The toolbox doesn't come with the proof system, so you need to install it separately.
The instructions are out-of-date and have a lot of broken links.
In May, I turned the steps into a Dockerfile, which got it partly installed, and asked on the TLA group for help,
but no-one else seemed to know how to install it either.
By looking at the error messages and searching the web for programs with the same names, I finally managed to get it working in December.
If you have trouble installing it too, try using my Docker image.
Once installed, you can write a proof in the toolbox and then press Ctrl-G, Ctrl-G to check it.
On success, the proof turns green. On failure, the failing step turns red.
You can also do the Ctrl-G, Ctrl-G combination on a single step to check just that step.
That's useful, because it's pretty slow.
It takes more than 10 minutes to check the complete specification.
TLA proofs are done in the mathematical style,
which is to write a set of propositions and vaguely suggest that thinking about these will lead you to the proof.
This is good for building intuition, but bad for reproducibility.
A mathematical proof is considered correct if the reader is convinced by it, which depends on the reader.
In this case, the "reader" is a collection of automated theorem-provers with various timeouts.
This means that whether a proof is correct or not depends on how fast your computer is,
how many programs are currently running, etc.
A proof might pass one day and fail the next.
Some proof steps consistently pass when you try them individually,
but consistently fail when checked as part of the whole proof.
If a step fails, you need to break it down into smaller steps.
Sometimes the proof system is very clever, and immediately solves complex steps.
For example, here is the proof that the SenderClose process (which represents the sender closing the channel),
preserves the invariant I:
A step such as IntegrityI' BY DEF IntegrityI says
"You can see that IntegrityI will be true in the next step just by looking at its definition".
So this whole lemma is really just saying "it's obvious".
And TLAPS agrees.
At other times, TLAPS can be maddeningly stupid.
And it can't tell you what the problem is - it can only make things go red.
We're trying to say that pc[2] is unchanged, given that pc' is the same as pc except that we changed pc[1].
The problem is that TLA is an untyped language.
Even though we know we did a mapping update to pc,
that isn't enough (apparently) to conclude that pc is in fact a mapping.
To fix it, you need:
The extra pc \in [Nat -> STRING] tells TLA the type of the pc variable.
I found missing type information to be the biggest problem when doing proofs,
because you just automatically assume that the computer will know the types of things.
Another example:
We're just trying to remove the x + ... from both sides of the equation.
The problem is, TLA doesn't know that Min(y, 10) is a number,
so it doesn't know whether the normal laws of addition apply in this case.
It can't tell you that, though - it can only go red.
Here's the solution:
The BY DEF Min tells TLAPS to share the definition of Min with the solvers.
Then they can see that Min(y, 10) must be a natural number too and everything works.
Another annoyance is that sometimes it can't find the right lemma to use,
even when you tell it exactly what it needs.
Here's an extreme case:
1234567891011121314151617181920212223242526272829
LEMMATransferFacts==ASSUMENEWsrc,NEWsrc2,\* (TLAPS doesn't cope with "NEW VARAIBLE src")NEWdst,NEWdst2,NEWi\in1..Len(src),src\inMESSAGE,dst\inMESSAGE,dst2=dst\oTake(src,i),src2=Drop(src,i)PROVE/\src2\inMESSAGE/\Len(src2)=Len(src)-i/\dst2\inMESSAGE/\Len(dst2)=Len(dst)+i/\UNCHANGED(dst\osrc)PROOFOMITTEDLEMMASameAgain==ASSUMENEWsrc,NEWsrc2,\* (TLAPS doesn't cope with "NEW VARAIBLE src")NEWdst,NEWdst2,NEWi\in1..Len(src),src\inMESSAGE,dst\inMESSAGE,dst2=dst\oTake(src,i),src2=Drop(src,i)PROVE/\src2\inMESSAGE/\Len(src2)=Len(src)-i/\dst2\inMESSAGE/\Len(dst2)=Len(dst)+i/\UNCHANGED(dst\osrc)BYTransferFacts
TransferFacts states some useful facts about transferring data between two variables.
You can prove that quite easily.
SameAgain is identical in every way, and just refers to TransferFacts for the proof.
But even with only one lemma to consider - one that matches all the assumptions and conclusions perfectly -
none of the solvers could figure this one out!
My eventual solution was to name the bundle of results.
This works:
Most of the art of using TLAPS is in controlling how much information to share with the provers.
Too little (such as failing to provide the definition of Min) and they don't have enough information to find the proof.
Too much (such as providing the definition of TransferResults) and they get overwhelmed and fail to find the proof.
It's all a bit frustrating, but it does work,
and being machine checked does give you some confidence that your proofs are actually correct.
Another, perhaps more important, benefit of machine checked proofs is that
when you decide to change something in the specification you can just ask it to re-check everything.
Go and have a cup of tea, and when you come back it will have highlighted in red any steps that need to be updated.
I made a lot of changes, and this worked very well.
The TLAPS philosophy is that
If you are concerned with an algorithm or system, you should not be spending your time proving basic mathematical facts.
Instead, you should assert the mathematical theorems you need as assumptions or theorems.
So even if you can't find a formal proof of every step, you can still use TLAPS to break it down into steps than you
either can prove, or that you think are obvious enough that they don't require a proof.
However, I was able to prove everything I needed for the vchan specification within TLAPS.
The final specification
I did a little bit of tidying up at the end.
In particular, I removed the want variable from the specification.
I didn't like it because it doesn't correspond to anything in the OCaml implementation,
and the only place the algorithm uses it is to decide whether to set NotifyWrite,
which I thought might be wrong anyway.
That always allows an implementation to set NotifyWrite if it wants to,
or to skip that step just as long as have > 0.
That covers the current C behaviour, my proposed C behaviour, and the OCaml implementation.
It also simplifies the invariant, and even made the proofs shorter!
I put the final specification online at spec-vchan.
I also configured Travis CI to check all the models and verify all the proofs.
That's useful because sometimes I'm too impatient to recheck everything on my laptop before pushing updates.
You can generate a PDF version of the specification with make pdfs.
Expressions there can be a little easier to read because they use proper symbols, but
it also breaks things up into pages, which is highly annoying.
It would be nice if it could omit the proofs too, as they're really only useful if you're trying to edit them.
I'd rather just see the statement of each theorem.
The original bug
With my new understanding of vchan, I couldn't see anything obvious wrong with the C code
(at least, as long as you keep the connection open, which the firewall does).
I then took a look at ocaml-vchan.
The first thing I noticed was that someone had commented out all the memory barriers,
noting in the Git log that they weren't needed on x86.
I am using x86, so that's not it, but I filed a bug about it anyway: Missing memory barriers.
The other strange thing I saw was the behaviour of the read function.
It claims to implement the Mirage FLOW interface, which says that read
"blocks until some data is available and returns a fresh buffer containing it".
However, looking at the code, what it actually does is to return a pointer directly into the shared buffer.
It then delays updating the consumer counter until the next call to read.
That's rather dangerous, and I filed another bug about that: Read has very surprising behaviour.
However, when I checked the mirage-qubes code, it just takes this buffer and makes a copy of it immediately.
So that's not the bug either.
Also, the original bug report mentioned a 10 second timeout,
and neither the C implementation nor the OCaml one had any timeouts.
Time to look at QubesDB itself.
QubesDB accepts messages from either the guest VM (the firewall) or from local clients connected over Unix domain sockets.
The basic structure is:
The suspicion was that we were missing a vchan event,
but then it was discovering that there was data in the buffer anyway due to the timeout.
Looking at the code, it does seem to me that there is a possible race condition here:
A local client asks to send some data.
handle_client_data sends the data to the firewall using a blocking write.
The firewall sends a message to QubesDB at the same time and signals an event because the firewall-to-db buffer has data.
QubesDB gets the event but ignores it because it's doing a blocking write and there's still no space in the db-to-firewall direction.
The firewall updates its consumer counter and signals another event, because the buffer now has space.
The blocking write completes and QubesDB returns to the main loop.
QubesDB goes to sleep for 10 seconds, without checking the buffer.
I don't think this is the cause of the bug though,
because the only messages the firewall might be sending here are QDB_RESP_OK messages,
and QubesDB just discards such messages.
I managed to reproduce the problem myself,
and saw that in fact QubesDB doesn't make any progress due to the 10 second timeout.
It just tries to go back to sleep for another 10 seconds and then
immediately gets woken up by a message from a local client.
So, it looks like QubesDB is only sending updates every 10 seconds because its client, qubesd,
is only asking it to send updates every 10 seconds!
And looking at the qubesd logs, I saw stacktraces about libvirt failing to attach network devices, so
I read the Xen network device attachment specification to check that the firewall implemented that correctly.
I'm kidding, of course.
There isn't any such specification.
But maybe this blog post will inspire someone to write one...
Conclusions
As users of open source software, we're encouraged to look at the source code and check that it's correct ourselves.
But that's pretty difficult without a specification saying what things are supposed to do.
Often I deal with this by learning just enough to fix whatever bug I'm working on,
but this time I decided to try making a proper specification instead.
Making the TLA specification took rather a long time, but it was quite pleasant.
Hopefully the next person who needs to know about vchan will appreciate it.
A TLA specification generally defines two sets of behaviours.
The first is the set of desirable behaviours (e.g. those where the data is delivered correctly).
This definition should clearly explain what users can expect from the system.
The second defines the behaviours of a particular algorithm.
This definition should make it easy to see how to implement the algorithm.
The TLC model checker can check that the algorithm's behaviours are all acceptable,
at least within some defined limits.
Writing a specification using the TLA notation forces us to be precise about what we mean.
For example, in a prose specification we might say "data sent will eventually arrive", but in an
executable TLA specification we're forced to clarify what happens if the connection is closed.
I would have expected that if a sender writes some data and then closes the connection then the data would still arrive,
but the C implementation of vchan does not always ensure that.
The TLC model checker can find a counter-example showing how this can fail in under a minute.
To explain why the algorithm always works, we need to find an inductive invariant.
The TLC model checker can help with this,
by presenting examples of unreachable states that satisfy the invariant but don't preserve it after taking a step.
We must add constraints to explain why these states are invalid.
This was easy for the Integrity invariant, which explains why we never receive incorrect data, but
I found it much harder to prove that the system cannot deadlock.
I suspect that the original designer of a system would find this step easy, as presumably they already know why it works.
Once we have found an inductive invariant, we can write a formal machine-checked proof that the invariant is always true.
Although TLAPS doesn't allow us to prove liveness properties directly,
I was able to prove various interesting things about the algorithm: it doesn't deadlock; when the sender is blocked, the receiver can read everything that has been sent; and when the receiver is blocked, the sender can fill the entire buffer.
Writing formal proofs is a little tedious, largely because TLA is an untyped language.
However, there is nothing particularly difficult about it,
once you know how to work around various limitations of the proof checkers.
You might imagine that TLA would only work on very small programs like libvchan, but this is not the case.
It's just a matter of deciding what to specify in detail.
For example, in this specification I didn't give any details about how ring buffers work,
but instead used a single Buffer variable to represent them.
For a specification of a larger system using vchan, I would model each channel using just Sent and Got
and an action that transferred some of the difference on each step.
The TLA Toolbox has some rough edges.
The ones I found most troublesome were: the keyboard shortcuts frequently stop working;
when a temporal property is violated, it doesn't tell you which one it was; and
the model explorer tooltips appear right under the mouse pointer,
preventing you from scrolling with the mouse wheel.
It also likes to check its "news feed" on a regular basis.
It can't seem to do this at the same time as other operations,
and if you're in the middle of a particularly complex proof checking operation,
it will sometimes suddenly pop up a box suggesting that you cancel your job,
so that it can get back to reading the news.
However, it is improving.
In the latest versions, when you get a syntax error, it now tells you where in the file the error is.
And pressing Delete or Backspace while editing no longer causes it to crash and lose all unsaved data.
In general I feel that the TLA Toolbox is quite usable now.
If I were designing a new protocol, I would certainly use TLA to help with the design.
TLA does not integrate with any language type systems, so even after you have a specification
you still need to check manually that your code matches the spec.
It would be nice if you could check this automatically, somehow.
One final problem is that whenever I write a TLA specification, I feel the need to explain first what TLA is.
Hopefully it will become more popular and that problem will go away.
Update 2019-01-10: Marek Marczykowski-Górecki told me that the state model for network devices is the same as
the one for block devices, which is documented in the blkif.h block device header file, and provided libvirt debugging help -
so the bug is now fixed!
]]>A Unikernel Firewall for QubesOS2016-01-01T17:55:00+00:00https://roscidus.com/blog/blog/2016/01/01/a-unikernel-firewall-for-qubesosQubesOS provides a desktop operating system made up of multiple virtual machines, running under Xen.
To protect against buggy network drivers, the physical network hardware is accessed only by a dedicated (and untrusted) "NetVM", which is connected to the rest of the system via a separate (trusted) "FirewallVM".
This firewall VM runs Linux, processing network traffic with code written in C.
In this blog post, I replace the Linux firewall VM with a MirageOS unikernel.
The resulting VM uses safe (bounds-checked, type-checked) OCaml code to process network traffic,
uses less than a tenth of the memory of the default FirewallVM, boots several times faster,
and should be much simpler to audit or extend.
QubesOS is a security-focused desktop operating system that uses virtual machines to isolate applications from each other. The screenshot below shows my current desktop. The windows with green borders are running Fedora in my "comms" VM, which I use for gmail and similar trusted sites (with NoScript). The blue windows are from a Debian VM which I use for software development. The red windows are another Fedora VM, which I use for general browsing (with flash, etc) and running various untrusted applications:
Another Fedora VM ("dom0") runs the window manager and drives most of the physical hardware (mouse, keyboard, screen, disks, etc).
Networking is a particularly dangerous activity, since attacks can come from anywhere in the world and handling network hardware and traffic is complex.
Qubes therefore uses two extra VMs for networking:
NetVM drives the physical network device directly. It runs network-manager and provides the system tray applet for configuring the network.
FirewallVM sits between the application VMs and NetVM. It implements a firewall and router.
The full system looks something like this:
The lines between VMs in the diagram above represent network connections.
If NetVM is compromised (e.g. by exploiting a bug in the kernel module driving the wifi card) then the system as a whole can still be considered secure - the attacker is still outside the firewall.
Besides traditional networking, all VMs can communicate with dom0 via some Qubes-specific protocols.
These are used to display window contents, tell VMs about their configuration, and provide direct channels between VMs where appropriate.
Qubes networking
There are three IP networks in the default configuration:
192.168.1.* is the external network (to my house router).
10.137.1.* is a virtual network connecting NetVM to the firewalls (you can have multiple firewall VMs).
10.137.2.* connects the app VMs to the default FirewallVM.
Both NetVM and FirewallVM perform NAT, so packets from "comms" appear to NetVM to have been sent by the firewall, and packets from the firewall appear to my house router to have come from NetVM.
Each of the AppVMs is configured to use the firewall (10.137.2.1) as its DNS resolver.
FirewallVM uses an iptables rule to forward DNS traffic to its resolver, which is NetVM.
Problems with FirewallVM
After using Qubes for a while, there are a number of things about the default FirewallVM that I'm unhappy about:
It runs a full Linux system, which uses at least 300 MB of RAM. This seems excessive.
It takes several seconds to boot.
There is a race somewhere setting up the DNS redirection. Adding some debug to track down the bug made it disappear.
The iptables configuration is huge and hard to understand.
There is another, more serious, problem.
Xen virtual network devices are implemented as a client ("netfront") and a server ("netback"), which are Linux kernel modules in sys-firewall.
In a traditional Xen system, the netback driver runs in dom0 and is fully trusted. It is coded to protect itself against misbehaving client VMs. Netfront, by contrast, assumes that netback is trustworthy.
The Xen developers only considers bugs in netback to be security critical.
In Qubes, NetVM acts as netback to FirewallVM, which acts as a netback in turn to its clients.
But in Qubes, NetVM is supposed to be untrusted! So, we have code running in kernel mode in the (trusted) FirewallVM that is talking to and trusting the (untrusted) NetVM!
For example, as the Qubes developers point out in Qubes Security Bulletin #23, the netfront code that processes responses from netback uses the request ID quoted by netback as an index into an array without even checking if it's in range (they have fixed this in their fork).
What can an attacker do once they've exploited FirewallVM's trusting netfront driver?
Presumably they now have complete control of FirewallVM.
At this point, they can simply reuse the same exploit to take control of the client VMs, which are running the same trusting netfront code!
A Unikernel Firewall
I decided to see whether I could replace the default firewall ("sys-firewall") with a MirageOS unikernel.
A Mirage unikernel is an OCaml program compiled to run as an operating system kernel.
It pulls in just the code it needs, as libraries.
For example, my firewall doesn't require or use a hard disk, so it doesn't contain any code for dealing with block devices.
If you want to follow along, my code is on GitHub in my qubes-mirage-firewall repository.
The README explains how to build it from source.
For testing, you can also just download the mirage-firewall-bin-0.1.tar.bz2 binary kernel tarball.
dom0 doesn't have network access, but you can proxy the download through another VM:
[tal@dom0 ~]$ cd /tmp
[tal@dom0 tmp]$ qvm-run -p sys-net 'wget -O - https://github.com/talex5/qubes-mirage-firewall/releases/download/0.1/mirage-firewall-bin-0.1.tar.bz2' > mirage-firewall-bin-0.1.tar.bz2
[tal@dom0 tmp]$ tar tf mirage-firewall-bin-0.1.tar.bz2
mirage-firewall/
mirage-firewall/vmlinuz
mirage-firewall/initramfs
mirage-firewall/modules.img
[tal@dom0 ~]$ cd /var/lib/qubes/vm-kernels/
[tal@dom0 vm-kernels]$ tar xf /tmp/mirage-firewall-bin-0.1.tar.bz2
The tarball contains vmlinuz, which is the unikernel itself, plus a couple of dummy files that Qubes requires to recognise it as a kernel (modules.img and initramfs).
Create a new ProxyVM named "mirage-firewall" to run the unikernel:
You can use any template, and make it standalone or not. It doesn't matter, since we don't use the hard disk.
Set the type to ProxyVM.
Select sys-net for networking (not sys-firewall).
Click OK to create the VM.
Go to the VM settings, and look in the "Advanced" tab.
Set the kernel to mirage-firewall.
Turn off memory balancing and set the memory to 32 MB or so (you might have to fight a bit with the Qubes GUI to get it this low).
Set VCPUs (number of virtual CPUs) to 1.
(this installation mechanism is obviously not ideal; hopefully future versions of Qubes will be more unikernel-friendly)
You can run mirage-firewall alongside your existing sys-firewall and you can choose which AppVMs use which firewall using the GUI.
For example, to configure "untrusted" to use mirage-firewall:
You can view the unikernel's log output from the GUI, or with sudo xl console mirage-firewall in dom0 if you want to see live updates.
If you want to explore the code but don't know OCaml, a good tip is that most modules (.ml files) have a corresponding .mli interface file which describes the module's public API (a bit like a .h file in C).
It's usually worth reading those interface files first.
I tested initially with Qubes 3.0 and have just upgraded to the 3.1 alpha. Both seem to work.
Booting a Unikernel on Qubes
Qubes runs on Xen and a Mirage application can be compiled to a Xen kernel image using mirage configure --xen.
However, Qubes expects a VM to provide three Qubes-specific services and doesn't consider the VM to be running until it has connected to each of them. They are qrexec (remote command execution), gui (displaying windows on the dom0 desktop) and QubesDB (a key-value store).
I wrote a little library, mirage-qubes, to implement enough of these three protocols for the firewall (the GUI does nothing except handshake with dom0, since the firewall has no GUI).
Here's the full boot code in my firewall, showing how to connect the agents:
unikernel.ml
1234567891011121314151617181920212223
letstart()=letstart_time=Clock.time()inLog_reporter.init_logging();(* Start qrexec agent, GUI agent and QubesDB agent in parallel *)letqrexec=RExec.connect~domid:0()inletgui=GUI.connect~domid:0()inletqubesDB=DB.connect~domid:0()in(* Wait for clients to connect *)qrexec>>=funqrexec->letagent_listener=RExec.listenqrexecCommand.handleringui>>=fungui->Lwt.async(fun()->GUI.listengui);qubesDB>>=funqubesDB->Log.info"agents connected in %.3f s (CPU time used since boot: %.3f s)"(funf->f(Clock.time()-.start_time)(Sys.time()));(* Watch for shutdown requests from Qubes *)letshutdown_rq=OS.Lifecycle.await_shutdown()>>=fun(`Poweroff|`Reboot)->return()in(* Set up networking *)letnet_listener=networkqubesDBin(* Run until something fails or we get a shutdown request. *)Lwt.choose[agent_listener;net_listener;shutdown_rq]>>=fun()->(* Give the console daemon time to show any final log messages. *)OS.Time.sleep1.0
After connecting the agents, we start a thread watching for shutdown requests (which arrive via XenStore, a second database) and then configure networking.
Tips on reading OCaml
let x = ... defines a variable.
let fn args = ... defines a function.
Clock.time is the time function in the Clock module.
() is the empty tuple (called "unit"). It's used for functions that don't take arguments, or return nothing useful.
~foo is a named argument. connect ~domid:0 is like connect(domid = 0) in Python.
promise >>= f calls function f when the promise resolves. It's like promise.then(f) in JavaScript.
foo () >>= fun result -> is the asynchronous version of let result = foo () in.
return x creates an already-resolved promise (it does not make the function return).
Networking
The general setup is simple enough: we read various configuration settings (IP addresses, netmasks, etc) from QubesDB,
set up our two networks (the client-side one and the one with NetVM), and configure a router to send packets between them:
unikernel.ml
1234567891011121314151617181920212223
(* Set up networking and listen for incoming packets. *)letnetworkqubesDB=(* Read configuration from QubesDB *)letconfig=Dao.read_network_configqubesDBinLogs.info"Client (internal) network is %a"(funf->fIpaddr.V4.Prefix.pp_humconfig.Dao.clients_prefix);(* Initialise connection to NetVM *)Uplink.connectconfig>>=funuplink->(* Report success *)Dao.set_iptables_errorqubesDB"">>=fun()->(* Set up client-side networking *)letclient_eth=Client_eth.create~client_gw:config.Dao.clients_our_ip~prefix:config.Dao.clients_prefixin(* Set up routing between networks and hosts *)letrouter=Router.create~client_eth~uplink:(Uplink.interfaceuplink)in(* Handle packets from both networks *)Lwt.join[Client_net.listenrouter;Uplink.listenuplinkrouter]
OCaml notes
config.Dao.clients_our_ip means the clients_our_ip field of the config record, as defined in the Dao module.
~client_eth is short for ~client_eth:client_eth - i.e. pass the value of the client_eth variable as a parameter also named client_eth.
The Xen virtual network layer
At the lowest level, networking requires the ability to send a blob of data from one VM to another.
This is the job of the Xen netback/netfront protocol.
For example, consider the case of a new AppVM (Xen domain ID 5) being connected to FirewallVM (4).
First, dom0 updates its XenStore database (which is shared with the VMs). It creates two directories:
/local/domain/4/backend/vif/5/0/
/local/domain/5/device/vif/0/
Each directory contains a state file (set to 1, which means initialising) and information about the other end.
The first directory is monitored by the firewall (domain 4).
When it sees the new entry, it knows it has a new network connection to domain 5, interface 0.
It writes to the directory information about what features it supports and sets the state to 2 (init-wait).
The second directory will be seen by the new domain 5 when it boots.
It tells it that is has a network connection to dom 4.
The client looks in the dom 4's backend directory and waits for the state to change to init-wait, the checks the supported features.
It allocates memory to share with the firewall, tells Xen to grant access to dom 4, and writes the ID for the grant to the XenStore directory.
It sets its own state to 4 (connected).
When the firewall sees the client is connected, it reads the grant refs, tells Xen to map those pages of memory into its own address space, and sets its own state to connected too.
The two VMs can now use the shared memory to exchange messages (blocks of data up to 64 KB).
The reason I had to find out about all this is that the mirage-net-xen library only implemented the netfront side of the protocol.
Luckily, Dave Scott had already started adding support for netback and I was able to complete that work.
Getting this working with a Mirage client was fairly easy, but I spent a long time trying to figure out why my code was making Linux VMs kernel panic.
It turned out to be an amusing bug in my netback serialisation code, which only worked with Mirage by pure luck.
However, this did alert me to a second bug in the Linux netfront driver: even if the ID netback sends is within the array bounds, that entry isn't necessarily valid.
Sending an unused ID would cause netfront to try to unmap someone else's grant-ref.
Not exploitable, perhaps, but another good reason to replace this code!
The Ethernet layer
It might seem like we're nearly done: we want to send IP (Internet Protocol) packets between VMs, and we have a way to send blocks of data.
However, we must now take a little detour down Legacy Lane...
Operating systems don't expect to send IP packets directly.
Instead, they expect to be connected to an Ethernet network, which requires each IP packet to be wrapped in an Ethernet "frame".
Our virtual network needs to emulate an Ethernet network.
In an Ethernet network, each network interface device has a unique "MAC address" (e.g. 01:23:45:67:89:ab).
An Ethernet frame contains source and destination MAC addresses, plus a type (e.g. "IPv4 packet").
When a client VM wants to send an IP packet, it first broadcasts an Ethernet ARP request, asking for the MAC address of the target machine.
The target machine responds with its MAC address.
The client then transmits an Ethernet frame addressed to this MAC address, containing the IP packet inside.
If we were building our system out of physical machines, we'd connect everything via an Ethernet switch, like this:
This layout isn't very good for us, though, because it means the VMs can talk to each other directly.
Normally you might trust all the machines behind the firewall, but the point of Qubes is to isolate the VMs from each other.
Instead, we want a separate Ethernet network for each client VM:
In this layout, the Ethernet addressing is completely pointless - a frame simply goes to the machine at the other end of the link.
But we still have to add an Ethernet frame whenever we send a packet and remove it when we receive one.
And we still have to implement the ARP protocol for looking up MAC addresses.
That's the job of the Client_eth module (dom0 puts the addresses in XenStore for us).
As well as sending queries, a VM can also broadcast a "gratuitous ARP" to tell other VMs its address without being asked.
Receivers of a gratuitous ARP may then update their ARP cache, although FirewallVM is configured not to do this (see /proc/sys/net/ipv4/conf/all/arp_accept).
For mirage-firewall, I just log what the client requested but don't let it update anything:
I'm not sure whether or not Qubes expects one client VM to be able to look up another one's MAC address.
It sets /qubes-netmask in QubesDB to 255.255.255.0, indicating that all clients are on the same Ethernet network.
Therefore, I wrote my ARP responder to respond on behalf of the other clients to maintain this illusion.
However, it appears that my Linux VMs have ignored the QubesDB setting and used a netmask of 255.255.255.255. Puzzling, but it should work either way.
Here's the code that connects a new client virtual interface (vif) to our router (in Client_net):
client_net.ml
123456789101112131415161718192021
(** Connect to a new client's interface and listen for incoming frames. *)letadd_vif{Dao.domid;device_id;client_ip}~router~cleanup_tasks=Netback.make~domid~device_id>>=funbackend->Log.info"Client %d (IP: %s) ready"(funf->fdomid(Ipaddr.V4.to_stringclient_ip));ClientEth.connectbackend>>=or_fail"Can't make Ethernet device">>=funeth->letclient_mac=Netback.macbackendinletiface=newclient_ifaceethclient_ipclient_macinRouter.add_clientrouteriface;Cleanup.on_cleanupcleanup_tasks(fun()->Router.remove_clientrouteriface);letfixed_arp=Client_eth.ARP.create~net:router.Router.client_ethifaceinNetback.listenbackend(funframe->matchWire_structs.parse_ethernet_frameframewith|None->Log.warn"Invalid Ethernet frame"Logs.unit;return()|Some(typ,_destination,payload)->matchtypwith|SomeWire_structs.ARP->input_arp~fixed_arp~ethpayload|SomeWire_structs.IPv4->input_ipv4~client_ip~routerframepayload|SomeWire_structs.IPv6->return()|None->Logs.warn"Unknown Ethernet type"Logs.unit;Lwt.return_unit)
OCaml note:{ x = 1; y = 2 } is a record (struct). { x = x; y = y } can be abbreviated to just { x; y }. Here we pattern-match on a Dao.client_vif record passed to the function to extract the fields.
The Netback.listen at the end runs a loop that communicates with the netfront driver in the client.
Each time a frame arrives, we check the type and dispatch to either the ARP handler or, for IPv4 packets,
the firewall code.
We don't support IPv6, since Qubes doesn't either.
client_net.ml
1234567891011121314
letinput_arp~fixed_arp~ethrequest=matchClient_eth.ARP.inputfixed_arprequestwith|None->return()|Someresponse->ClientEth.writeethresponse(** Handle an IPv4 packet from the client. *)letinput_ipv4~client_ip~routerframepacket=letsrc=Wire_structs.Ipv4_wire.get_ipv4_srcpacket|>Ipaddr.V4.of_int32inifsrc=client_ipthenFirewall.ipv4_from_clientrouterframeelse(Log.warn"Incorrect source IP %a in IP packet from %a (dropping)"(funf->fIpaddr.V4.pp_humsrcIpaddr.V4.pp_humclient_ip);return())
OCaml note:|> is the "pipe" operator. x |> fn is the same as fn x, but sometimes it reads better to have the values flowing left-to-right. You can also think of it as the synchronous version of >>=.
Notice that we check the source IP address is the one we expect.
This means that our firewall rules can rely on client addresses.
There is similar code in Uplink, which handles the NetVM side of things:
uplink.mk
12345678910111213141516171819202122
letconnectconfig=letip=config.Dao.uplink_our_ipinNetif.connect"tap0">>=or_fail"Can't connect uplink device">>=funnet->Eth.connectnet>>=or_fail"Can't make Ethernet device for tap">>=funeth->Arp.connecteth>>=or_fail"Can't add ARP">>=funarp->Arp.add_iparpip>>=fun()->letnetvm_mac=Arp.queryarpconfig.Dao.uplink_netvm_ip>|=function|`Timeout->failwith"ARP timeout getting MAC of our NetVM"|`Oknetvm_mac->netvm_macinletmy_ip=Ipaddr.V4ipinletinterface=newnetvm_ifaceethnetvm_macconfig.Dao.uplink_netvm_ipinreturn{net;eth;arp;interface;my_ip}letlistentrouter=Netif.listent.net(funframe->(* Handle one Ethernet frame from NetVM *)Eth.inputt.eth~arpv4:(Arp.inputt.arp)~ipv4:(fun_ip->Firewall.ipv4_from_netvmrouterframe)~ipv6:(fun_ip->return())frame)
OCaml note:Arp.input t.arp is a partially-applied function. It's short for fun x -> Arp.input t.arp x.
Here we just use the standard Eth.input code to dispatch on the frame.
It checks that the destination MAC matches ours and dispatches based on type.
We couldn't use it for the client code above because there we also want to
handle frames addressed to other clients, which Eth.input would discard.
Eth.input extracts the IP packet from the Ethernet frame and passes that to our callback,
but the NAT library I used likes to work on whole Ethernet frames, so I ignore the IP packet
(_ip) and send the frame instead.
The IP layer
Once an IP packet has been received, it is sent to the Firewall module
(either ipv4_from_netvm or ipv4_from_client, depending on where it came from).
The process is similar in each case:
Check if we have an existing NAT entry for this packet. If so, it's part of a conversation we've already approved, so perform the translation and send it on its way. NAT support is provided by the handy mirage-nat library.
If not, collect useful information about the packet (source, destination, protocol, ports) and check against the user's firewall rules, then take whatever action they request.
Here's the code that takes a client IPv4 frame and applies the firewall rules:
firewall.ml
1234567891011121314
letipv4_from_clienttframe=matchMemory_pressure.status()with|`Memory_critical->(* TODO: should happen before copying and async *)Log.warn"Memory low - dropping packet"Logs.unit;return()|`Ok->(* Check for existing NAT entry for this packet *)matchtranslatetframewith|Someframe->forward_ipv4tframe(* Some existing connection or redirect *)|None->(* No existing NAT entry. Check the firewall rules. *)matchclassifytframewith|None->return()|Someinfo->apply_rulestRules.from_clientinfo
Qubes provides a GUI that lets the user specify firewall rules.
It then encodes these as Linux iptables rules and puts them in QubesDB.
This isn't a very friendly format for non-Linux systems, so I ignore this and hard-code the rules in OCaml instead, in the Rules module:
12345678910111213
(** Decide what to do with a packet from a client VM. Note: If the packet matched an existing NAT rule then this isn't called. *)letfrom_client=function|{dst=(`External_|`NetVM)}->`NAT|{dst=`Client_gateway;proto=`UDP{dport=53}}->`NAT_to(`NetVM,53)|{dst=(`Client_gateway|`Firewall_uplink)}->`Drop"packet addressed to firewall itself"|{dst=`Client_}->`Drop"prevent communication between client VMs"|{dst=`Unknown_client_}->`Drop"target client not running"(** Decide what to do with a packet received from the outside world. Note: If the packet matched an existing NAT rule then this isn't called. *)letfrom_netvm=function|_->`Drop"drop by default"
For packets from clients to the outside world we use the NAT action to rewrite the source address so the packets appear to come from the firewall (via some unused port).
DNS queries sent to the firewall get redirected to NetVM (UDP port 53 is DNS).
In both cases, the NAT actions update the NAT table so that we will forward any responses back to the client.
Everything else is dropped, with a log message.
I think it's rather nice the way we can use OCaml's existing support for pattern matching to implement the rules, without having to invent a new syntax.
Originally, I had a default-drop rule at the end of from_client, but OCaml helpfully pointed out that it wasn't needed, as the previous rules already covered every case.
The incoming policy is to drop everything that wasn't already allowed by a rule added by the out-bound NAT.
I don't know much about firewalls, but this scheme works for my needs.
For comparison, the Linux iptables rules currently in my sys-firewall are:
I find it hard to tell, looking at these tables, exactly what sys-firewall's security policy will actually do.
Evaluation
I timed start-up for the Linux-based "sys-firewall" and for "mirage-firewall" (after shutting them both down):
[tal@dom0 ~]$ time qvm-start sys-firewall
--> Creating volatile image: /var/lib/qubes/servicevms/sys-firewall/volatile.img...
--> Loading the VM (type = ProxyVM)...
--> Starting Qubes DB...
--> Setting Qubes DB info for the VM...
--> Updating firewall rules...
--> Starting the VM...
--> Starting the qrexec daemon...
Waiting for VM's qrexec agent......connected
--> Starting Qubes GUId...
Connecting to VM's GUI agent: .connected
--> Sending monitor layout...
--> Waiting for qubes-session...
real 0m9.321s
user 0m0.163s
sys 0m0.262s
[tal@dom0 ~]$ time qvm-start mirage-firewall
--> Loading the VM (type = ProxyVM)...
--> Starting Qubes DB...
--> Setting Qubes DB info for the VM...
--> Updating firewall rules...
--> Starting the VM...
--> Starting the qrexec daemon...
Waiting for VM's qrexec agent.connected
--> Starting Qubes GUId...
Connecting to VM's GUI agent: .connected
--> Sending monitor layout...
--> Waiting for qubes-session...
real 0m1.079s
user 0m0.130s
sys 0m0.192s
So, mirage-firewall starts in 1 second rather than 9. However, even most of this time is Qubes code running in dom0. xl list shows:
[tal@dom0 ~]$ sudo xl list
Name ID Mem VCPUs State Time(s)
dom0 0 6097 4 r----- 623.8
sys-net 4 294 4 -b---- 79.2
sys-firewall 17 1293 4 -b---- 9.9
mirage-firewall 18 30 1 -b---- 0.0
I guess sys-firewall did more work after telling Qubes it was ready, because Xen reports it used 9.9 seconds of CPU time.
mirage-firewall uses too little time for Xen to report anything.
Notice also that sys-firewall is using 1293 MB with no clients (it's configured to balloon up or down; it could probably go down to 300 MB without much trouble). I gave mirage-firewall a fixed 30 MB allocation, which seems to be enough.
I'm not sure how it compares with Linux for transmission performance, but it can max out my 30 Mbit/s Internet connection with its single CPU, so it's unlikely to matter.
Exercises
I've only implemented the minimal features to let me use it as my firewall.
The great thing about having a simple unikernel is that you can modify it easily.
Here are some suggestions you can try at home (easy ones first):
Change the policy to allow communication between client VMs.
Query the QubesDB /qubes-debug-mode key. If present and set, set logging to debug level.
Edit command.ml to provide a qrexec command to add or remove rules at runtime.
When a packet is rejected, add the frame to a ring buffer. Edit command.ml to provide a "dump-rejects" command that returns the rejected packets in pcap format, ready to be loaded into wireshark. Hint: you can use the ocaml-pcap library to read and write the pcap format.
All client VMs are reported as Client to the policy. Add a table mapping IP addresses to symbolic names, so you can e.g. allow DevVM to talk to TestVM or control access to specific external machines.
Qubes allows each VM to have two DNS servers. I only implemented the primary. Read the /qubes-secondary-dns and /qubes-netvm-secondary-dns keys from QubesDB and proxy that too.
Add a Reject action that sends an ICMP rejection message.
Find out what we're supposed to do when a domain shuts down. Currently, we set the netback state to closed, but the directory in XenStore remains. Who is responsible for deleting it?
Update the firewall to use the latest version of the mirage-nat library, which has extra features such as expiry of old NAT table entries.
Due to a silly mistake made by the Qubes Team, the IPv6 filtering rules
have been set to ALLOW by default in all Service VMs, which results in
lack of filtering for IPv6 traffic originating between NetVM and the
corresponding FirewallVM, as well as between AppVMs and the
corresponding FirewallVM. Because the RPC services (rpcbind and
rpc.statd) are, by default, bound also to the IPv6 interfaces in all the
VMs by default, this opens up an avenue to attack a FirewallVM from a
corresponding NetVM or AppVM, and further attack another AppVM from the
compromised FirewallVM, using a hypothetical vulnerability in the above
mentioned RPC services (chained attack).
What changes would be needed to mirage-firewall to reproduce this bug?
Summary
QubesOS provides a desktop environment made from multiple virtual machines, isolated using Xen.
It runs the network drivers (which it doesn't trust) in a Linux "NetVM", which it assumes may be compromised, and places a "FirewallVM" between that and the VMs running user applications.
This design is intended to protect users from malicious or buggy network drivers.
However, the Linux kernel code running in FirewallVM is written with the assumption that NetVM is trustworthy.
It is fairly likely that a compromised NetVM could successfully attack FirewallVM.
Since both FirewallVM and the client VMs all run Linux, it is likely that the same exploit would then allow the client VMs to be compromised too.
I used MirageOS to write a replacement FirewallVM in OCaml.
The new virtual machine contains almost no C code (little more than malloc, printk, the OCaml GC and libm), and should therefore avoid problems such as the unchecked array bounds problem that recently affected the Qubes firewall.
It also uses less than a tenth of the minimum memory of the Linux FirewallVM, boots several times faster, and when it starts handling network traffic it is already fully configured, avoiding e.g. any race setting up firewalls or DNS forwarding.
The code is around 1000 lines of OCaml, and makes it easy to follow the progress of a network frame from the point where the network driver reads it from a Xen shared memory ring, through the Ethernet handling, to the IP firewall code, to the user firewall policy, and then finally to the shared memory ring of the output interface.
The code has only been lightly tested (I've just started using it as the FirewallVM on my main laptop), but will hopefully prove easy to extend (and, if necessary, debug).
]]>CueKeeper internals: Experiences with Irmin, React, TyXML and IndexedDB2015-06-22T09:25:23+00:00https://roscidus.com/blog/blog/2015/06/22/cuekeeper-internals-irminIn CueKeeper: Gitting Things Done in the browser, I wrote about CueKeeper, a Getting Things Done application that runs client-side in your browser.
It stores your actions in a Git-like data-store provided by Irmin, allowing you to browse the history, revert changes, and sync (between tabs and, once the server backend is available, between devices).
Several people asked about the technologies used to build it, so that's what this blog will cover.
CueKeeper is written in OCaml and compiled to Javascript using js_of_ocaml.
The HTML is produced using TyXML, and kept up-to-date with React (note: that's OCaml React, not Facebook React).
Records are serialised using Sexplib and stored by Irmin in a local IndexedDB database in your browser.
Action descriptions are written in Markdown, which is parsed using Omd.
Here's a diagram of the main modules that make up CueKeeper:
disk_node defines the on-disk data types representing stored items such as actions and projects.
rev loads all the items in a single Git commit (revision), which together represent the state of the system at some point.
update keeps track of the current branch head, loading the new version when it updates. It is also responsible for writing changes to storage.
merge can merge any two branches using a 3-way merge.
model queries the state to extract the information to be displayed (e.g. list of current actions).
template renders the results to HTML. It also uses e.g. the Pikaday date-picker widget.
client is the main entry point for the Javascript (client-side) part of CueKeeper (the server is currently under development).
git_storage provides a Git-like interface to Irmin, which uses the irmin_IDB backend to store the data in the browser using IndexedDB (plus a little HTML storage for cross-tab notifications).
To test it, create an HTML file to load the new test.js code and open the HTML file in a web browser:
test.html
1234567
<!DOCTYPE html><html><body><p>Open the browser's Javascript console to see the output.</p><scriptsrc="test.js"></script></body></html>
OCaml bytecode statically includes any OCaml libraries it uses, so this method also works for complex real-world programs.
Many OCaml libraries can be used directly.
For example, I used ocaml-tar to create .tar archives in the browser for the export feature, and
the omd Markdown parser for the descriptions.
If the OCaml code uses external C functions (that aren't already provided) then you need to implement them in Javascript.
In the case of CueKeeper, I had to implement a few trivial functions for blitting blocks of memory between OCaml strings, bigarrays and bin_prot buffers.
I put these in a helpers.js file and added it to the js_of_ocaml arguments.
Using Javascript APIs
My first attempt at writing code for the browser was my Lwt trace visualiser.
I initially wrote that for the desktop but it turned out that running it in the browser was just a matter of replacing calls to GTK's Cairo canvas with calls to the very similar HTML canvas.
Writing CueKeeper required learning a bit more about the mysterious world of the Javascript DOM.
I also needed to integrate with the Pikaday date picker widget.
To do this, you first declare an OCaml class type for each Javascript class (you only have to define the methods you want to use), like this:
This says that a pikaday object has a getDate method which returns an optional Javascript date object, and that
a config object provides properties such as onSelect, which is a callback of a pikaday object which takes a date and returns nothing.
They're "unsafe" because this isn't type checked; there's no way to know whether Pikaday really implements the interface we defined above.
However, from this point on everything we do with Pikaday is statically checked against our definitions.
js_of_ocaml provides a syntax extension for OCaml to make using native Javascript objects easier.
object##property reads a property, object##property <- value sets a property, and object##method(args) calls a method.
Note that parentheses around the arguments are required, unlike with regular OCaml method calls.
Note also that js_of_ocaml ignores underscores in various places to avoid differences between Javascript and OCaml naming conventions (properties can't start with an uppercase character, for example).
It's interesting the way OCaml's type inference is used here: Js.Unsafe.global can take any type, and OCaml infers that its type is "object with a Pikaday property, which is a pikaday constructor taking a config argument" because that's how we use it.
Finally, here's the code that creates a new Pikaday object:
Here, we create a <div> element and use it as the container field of the Pikaday config object.
on_select is an OCaml function to handle the result, which we wrap with Js.wrap_callback and set as the Javascript callback.
If an initial date is given, we construct a Javascript Date object and set that as the default.
Finally, we create the Pikaday object and return it, along with the containing div.
All this means that binding to Javascript APIs is very easy and, thanks to the extra type-checking, feels more pleasant even than using Javascript libraries directly from Javascript.
Data structures
In CueKeeper, areas, projects and actions all share a common set of fields, which I defined using an OCaml record:
A Ck_id.t is a UUID (unique string).
I refer to other nodes using UUIDs so that renaming a node doesn't require updating everything that points to it.
This simplifies merging.
Each record is stored as a single file, and the name of the file is the item's UUID.
The conflicts field is used to store messages about any conflicts that had to be resolved during merging.
The with sexp annotation makes use of Sexplib to auto-generate code for serialising and deserialising these structures.
I use sexp_option and sexp_list rather than option and list to provide slightly nicer output: these fields will be omitted if empty.
I also (rather lazily) reuse this structure for contacts and contexts, but always keep parent and contact as None for them.
For actions and projects, we also need to record some extra data:
Here's what a project looks like when printed with Sexplib.Sexp.to_string_hum
(the hum suffix turns on pretty-printing; the real code uses plain to_string):
1234
(Project(((pstarredfalse)(pstateActive))((parent3eba7466-dafd-4b96-9fad-c9859ef825f2)(name"Make a Mirage unikernel")(description"")(ctime1429555212.546))))
Note that the child nodes don't appear at all here.
Instead, we find them through their parent field.
Finally, I wrapped everything up in some polymorphic variants:
This is very useful, because other parts of the code often want to deal with subsets of the types.
The interface lists which types can be used in each operation:
Actions and inactive projects don't appear (they return the accumulator unmodified),
while for areas and active projects we add a node, including a recursive call to get the children.
One problem I had with this scheme was the return types for modifications:
ck_disk_node.mli
1
valwith_conflict:string->([<generic]as'a)->'a
with_conflict msg node returns a copy of node with its conflict messages field extended with the given message.
The type says that it works with any subset of the node types, and that the result will be the same subset.
For example, when adding a conflict about repeats to an action, the result will be an action.
When adding a message to something that could be an area, project or action, the result will be another area, project or action.
However, I couldn't work out how to implement this signature without using Obj.magic (unsafe cast).
I asked on StackOverflow (Map a subset of a polymorphic variant) and it seems there's no easy answer.
I also experimented with a couple of other approaches:
Using GADTs didn't work because they don't support arbitrary subsets. A function either handles a specific node type, or all node types, but not e.g. just projects and actions.
Using objects avoided the need for the unsafe cast, but required more code elsewhere. Objects work well when you have a fixed set of operations and you want to make it easy to add new kinds of thing, but in GTD the set of types is fixed, while the operations (report generation, rendering on different devices, merging) are more open-ended.
Backwards compatibility
Although this is the 0.1-alpha release, I made various changes to the format during development and it's never too early to check that smooth upgrades are possible.
Besides, I've been recklessly using it as my action tracker during development and I don't like typing things in twice.
You'll notice some fields above have a with_default annotation.
This provides a default value when loading from earlier versions.
For more complex cases, it's possible to write custom code.
For example, I changed the date representation at one point from Unix timestamps to calendar dates (this provides more intuitive behaviour when moving between time-zones I think).
There is code in Ck_time to handle this:
ck_time.ml
123456
typeuser_date=(int*int*int)withsexp_ofletuser_date_of_sexp=letopenSexplib.Typeinfunction|Atom_asx-><:of_sexp<float>>x|>of_unix_time(* Old format *)|List_asx-><:of_sexp<int*int*int>>x
In the implementation (ck_time.ml) I use with sexp_of so that only the serialisation code is created automatically, while it uses my custom code for deserialising.
In the interface (ck_time.mli), I just declare it as with sexp and code outside doesn't see anything special.
Irmin
The next step was to write the data to the Irmin repository.
Irmin itself provides a fairly traditional key/value store API with some extra features for version control.
That might be useful for existing applications, but I wanted a more Git-like API.
For example, Irmin allows you to read files directly from the branch head, but in the browser another tab might update the branch between the two reads, leading to inconsistent results.
I wanted something that would force me to use atomic operations.
Also, the Irmin API is still being finalised, so I wanted to provide an example of my "ideal" API.
Here's the API wrapper I used (it doesn't provide access to all Irmin's features, just the ones I needed):
A Staging.t corresponds to the Git staging area / working directory. It is mutable, and not shared with other tabs:
A Commit.t represents a single (immutable) Git commit.
You can check out a commit to get a staging area, modify that, and then commit it to create a new Commit.t:
A branch is a mutable pointer to a commit.
The head is represented as a reactive signal (more on React later), making it easy to follow updates.
The only thing you can do with a branch is fast-forward it to a new commit.
Finally, a Repository.t represents a repository as a whole.
You can look up a branch by name or a commit by hash:
12345678910111213
moduleRepository:sigtypetvalbranch:t->if_new:(Commit.tLwt.tLazy.t)->branch_name->Branch.tLwt.t(** Get the named branch. * If the branch does not exist yet, [if_new] is called to get the initial commit. *)valcommit:t->Irmin.Hash.SHA1.t->Commit.toptionLwt.t(** Look up a commit by its hash. *)valempty:t->Staging.tLwt.t(** Create an empty checkout with no parent. *)end
Thomas Gazagnaire provided many useful updates to Irmin to let me implement this API: atomic operations (needed for a reliable fast_forward_to), support for creating commits with arbitrary parents (needed for custom merging, described below), and performance improvements (very important for running in a browser!).
IndexedDB backend
Irmin provides a Git backend that supports normal Git repositories, as well as a simpler filesystem backend, a remote HTTP backend, and an in-memory-only backend.
To run Irmin in the browser, I initially added a backend for HTML 5 storage.
However, HTML 5 storage is limited to 5 MB of data and since my backend lacked compression, it eventually ran out, so I then replaced it with support for IndexedDB.
js_of_ocaml supports most (standardised) HTML features, but IndexedDB had only just come out, so I had to write my own bindings (as for Pikaday, above).
IndexedDB is rather complicated compared to local storage, so I split it across several modules.
I first defined the Javascript API (indexedDB.mli), then wrapped it in a nicer OCaml API, providing asynchronous operations with Lwt threading rather than callbacks (indexedDB_lwt.mli).
I then made an Irmin backend that uses it (irmin_IDB.ml).
The Irmin API for backends can be a little confusing at first.
An Irmin "branch consistent" (Git-like) repository internally consists of two simpler stores: an append-only store that stores immutable blobs (files, directories and commits), indexed by their SHA1 hash, and a read-write store that is used to record which commit each branch currently points to.
If you can provide implementations of these two APIs, Irmin can automatically provide the full branch-consistent database API itself.
One problem with moving to IndexedDB is that it doesn't support notifications.
To get around this, when CueKeeper updates the master branch to point at a new commit, it also writes the SHA1 hash to local storage.
Other open windows or tabs get notified of this and then read the new data from IndexedDB.
I also found a couple of browser bugs while testing this.
Firefox seems to not clean up IndexedDB transactions, though this doesn't cause any obvious problems in practice.
Safari, however, has a more serious problem: if two threads (tabs) try to read from the database at the same time, one of the transactions will fail!
I was able to reproduce the error with a few lines of JavaScript (see idb_reads.html).
The page will:
Open a test database, creating a single key=value pair if it doesn't exist.
Attempt to read the value of the key ten times, once per second.
If you open this in two windows in Safari at once, one of them will likely fail with AbortError.
I reported it to Apple, but their feedback form says they don't respond to feedback, and they were as good as their word.
In the end, I added some code to sleep for a random period and retry on aborted reads.
Revisions and merging
Each object (project, action, contact, etc) in CueKeeper is a file in Irmin and each change creates a new commit.
This model tends to avoid race conditions.
For example, when you edit the title of an action and press Return, CueKeeper will:
Create a new commit with the updates, whose parent is the commit you started editing.
Merge this commit with the master branch.
Usually nothing else has changed since you started editing and the merge is a trivial "fast-forward" merge.
However, if you had edited something else about that action at the same time then instead of overwriting the changes, CueKeeper will merge them.
If you change the same field in two tabs at once, CueKeeper will pick one value and add a merge conflict note telling you the change it discarded.
You can try it here (click the image for an interactive page running two copies of CueKeeper split-screen):
The merge code takes three commits (the tips of the two branches being merged and an optional-but-usually-present "least common ancestor"), and produces a resulting commit (which may include merge conflict notes for the user to check):
ck_merge.mli
12345678910
moduleMake(Git:Git_storage_s.S)(R:Ck_rev.Swithtypecommit=Git.Commit.t):sigvalmerge:?base:Git.Commit.t->theirs:Git.Commit.t->Git.Commit.t->[`OkofGit.Commit.t|`Nothing_to_do]Lwt.t(* [merge ?base ~theirs ours] merges changes from [base] to [ours] into [theirs] and * returns the resulting merge commit. *)valrevert:repo:Git.Repository.t->master:Git.Commit.t->Git_storage_s.Log_entry.t->[`OkofGit.Commit.t|`Nothing_to_do|`Errorofstring]Lwt.t(** [revert ~master log_entry] returns a new commit on [master] which reverts the changes in [log_entry]. *)end
A revert operation is essentially the same as a merge, except that the base commit is the commit being undone, its (single) parent is one branch and the current state is the other.
It's a separate operation in the API because the commit it generates has a different format (it has only one parent and gives the commit being reverted in the log message).
I wanted to make sure that the merge code would always produce a valid result (e.g. the parent field of a node should point to a node that exists in the merged version).
I wrote a unit-test that performs many merges at random and checks the result loads without error.
My first thought was to perform edits at random to get a base commit, then make two branches from that and perform more random edits on each one.
After a while, I realised that you can edit any valid state into pretty-much any other valid state, so a simpler approach is to generate three commits at random.
You have to be a little bit careful here, however.
If the three commits are completely random then they won't have any UUIDs in common and the merges will be trivial.
Therefore, the UUIDs (and all field values) are chosen from a small set of candidates to ensure they're often the same.
I wrote the tests before the merge code, and as I wrote the merge code I deliberately failed to implement the required features first to check the tests caught each possible failure.
The tests found these problems automatically:
Commit refers to a contact or context that doesn't exist.
Project has area as child.
Repeating action marked as done.
Action, project or area has a missing parent.
It was easy enough to check which cases I'd missed because each possible failure corresponds to a call to bug in ck_rev.ml.
These problems weren't detected initially by the tests:
Cycles in the parent relation
Initially, my random state generator created nodes with random IDs, but at the time there was a bug in Irmin (since fixed) where it didn't sort the entries before writing them, which confused the Git tools I was using to examine the test results.
To work around this, I changed the test code to create the nodes with monotonically increasing IDs.
However, it would only set the parent to a previously-created node, so this meant that e.g. node 1 could never have a parent of node 2, which meant it could never generate two commits with the parent relation the other way around.
Easily fixed.
A Waiting_for_contact action has no contact
I was running 1000 iterations of the tests with a fixed seed while writing them.
This particular case only triggered after 1500 iterations, but it would have been found eventually when I removed the fixed seed.
To help things along, I added a slow_test make target that compiles the tests to native code and runs 10,000 iterations, and set this to run on the Travis build (it still only takes 14 seconds, but that's too long to do on every build, and long enough that the extra couple of seconds compiling to native code is worth it).
An action is a parent of another node
This one was a bit surprising.
To trigger it, you start with a base containing an action and a project.
On one branch, make the action a child of the project (only the action changes).
On the other, convert the project to an action (only the project changes).
If the bug is present, you end up with one action being a child of the other.
This wasn't picked up because it only happens if the project doesn't change at all in the first branch.
If it does change, the code for merging nodes gets called, and that copes with trying to merge a project with an action by converting the action to a project, which avoids the bug.
Because the nodes were being generated at random, the chance that every field in the base and the first branch would be identical was very low.
To fix it, I now generate a random number at the start of each test iteration and use it to bias the creation of the three states so that many of the fields will be shared.
This is enough to trigger detection of the bug.
React
The OCaml React library provides support for Functional reactive programming.
The idea here is to represent a (mutable) variable as a "signal".
Instead of operating on the current value of the variable, you operate on the signal as a whole.
Say you want to show a live display of the number of actions.
A traditional approach might be:
1234
letactions=ref0inletupdate()=show(Printf.sprintf"There are %d actions"!actions)inupdate()
Then you have to remember to call update whenever you change actions.
Instead, in FRP you work on the signal as a whole:
12
letactions,set_actions=S.create0inactions|>S.map(Printf.sprintf"There are %d actions")|>show
Here, actions is a signal, the S.map creates a new (string valued) signal from the old (int valued) one, and show ensures that the current value of the signal is displayed on the screen.
It's a bit like using a spreadsheet: you just enter the formulae, and the system ensures everything stays up-to-date.
CueKeeper uses signals all over the place: the Git commit at the tip of a branch, the description of an action, the currently selected tab, etc.
TyXML
I initially tried to generate the HTML using Caml on the Web (COW).
This provides a syntax extension for embedding HTML in your code.
For example, I wrote some code to render a tree to HTML, something like this:
It wasn't really suitable for what I wanted, though, because there was no obvious way to make it update (except by regenerating the whole thing and setting the innerHTML DOM attribute).
Also, while embedding another language with its own syntax is usually a nice feature, in the case of HTML I'm happy to make an exception.
I'd come across TyXML before, but had given up after being baffled by the documentation.
However, spurred on by the promise of React integration, I started reading the source code and it turned out to be fairly simple.
For every HTML element, TyXML provides a function with the same name.
The function takes a list of child nodes as its argument and, optionally, a list of attributes.
Written this way, the above code looks something like this:
It didn't compile, though, with a typically complicated error:
Error: This expression has type
([> Html5_types.ul ] as 'a) Tyxml_js.Html5.elt
but an expression was expected of type
Html5_types.li Tyxml_js.Html5.elt
Type 'a = [> `Ul ] is not compatible with type
Html5_types.li = [ `Li of Html5_types.li_attrib ]
The second variant type does not allow tag(s) `Ul
Eventually, I realised what it was saying.
My COW code above was wrong: it output each item as <li>name</li><ul>...</ul>.
The browser accepted this, but it's not valid HTML - the <ul> needs to go inside the <li>.
In fact, all we need is:
Shorter and more correct - a win for TyXML!
It also type-checks attributes.
For example, if you provide an onclick attribute then you can't provide a handler function with the wrong type (or get the name of the attribute wrong, or use a non-standard attribute, at least without explicit use of "unsafe" features).
Reactive TyXML
The Tyxml_js.Html5 module provides static elements, while Tyxml_js.R.Html5 provides reactive ones.
These take signals for attribute values and child lists and update the display automatically as the signal changes.
You can mix them freely (e.g. a static element with a reactive attribute).
For example, here's a (slightly simplified) version of the code that displays the tabs along to the top:
The tabs are an HTML <ul> element with one <li> for each tab.
current_mode is a reactive signal for the currently selected mode, which is initially Work.
Each <li> has a reactive class attribute which is "active" when the tab's mode is equal to the current mode.
Clicking the tab sets the mode.
Problems with React
My experience with using react is that it's very easy to write code that is short, clear, and subtly wrong.
Consider this (slightly contrived) example, which shows up-to-date information about how many of our actions have been completed:
We have two signals, representing the total number of actions and the number of them that are complete.
We connect the complete_actions signal to a function that outputs one of two signals: either a constant "(nothing complete)" signal if there are no complete actions, or a signal that shows the number and percentage complete.
This string signal is then connected up to an output function which, in this case, just prints it to the console with Update: prepended.
The loop at the end sets the total to a random number and the number complete to a random number less than or equal to that.
We use a "step" to ensure that the two signals are updated atomically.
Looks reasonable, right?
Running it, it works for a bit, but gets slower and slower as it runs, before eventually failing in one of two ways:
First, if the total_actions signal ever becomes zero again after being non-zero, it will crash with Division_by_zero:
The reason is that callbacks are not removed immediately.
When complete_actions is non-zero, we attach a callback to track complete and show the percentage.
When complete_actions becomes zero again, this callback continues to run, even though its output is no longer used.
If it doesn't crash, the garbage collector will eventually be run and the old callbacks will be removed.
Unfortunately, this will also garbage collect the callback that prints the status updates, and the program will simply stop producing any new output at this point.
At least, that's what happens with native code.
Javascript doesn't have weak references, so old callbacks are never removed there.
Early versions of CueKeeper uses React extensively, but I had to scale back my use of it due to these kinds of problems with callback lifetimes.
My general work-around is to break the reactive signal chains into disconnected sub-graphs, which can be garbage-collected individually.
For example, each panel in the display (e.g. showing the details of an action) contains a number of signals (name, parent, children, etc) which are used to keep the display up-to-date, but these signals are updated using imperative code, not by connecting them to the signal of the Irmin branch head.
When you close the panel, the functions for updating these signals become unreachable, allowing them to be GC'd, and they immediately stop being called.
Thus, we make leak a few callbacks while the panel is open, but closing it returns us to a clean state.
In a similar way, the tree view in the left column is a collection of signals that are updated manually.
Switching to a different tab will allow them to be freed.
It's not ideal, but it works.
I think that to complete its goal of having well-defined semantics, React needs to stop relying on weak references.
I imagine it would be possible to define a "global sink" object of some sort, such that a signal is live if and only if it is connected to that sink, or is a dependency of something else that is.
Then the let _ = above could be replaced with a connection to the global sink and the rest of the program would behave as expected.
I haven't thought too much about exactly how this would work, though.
Debugging
There was another problem, which I hit twice.
OCaml always optimises tail calls, but Javascript doesn't (I'm not sure about ES6).
In most cases where it matters, js_of_ocaml turns the code into a loop, but it doesn't handle continuation-passing style.
Both Sexplib and Omd failed to parse larger documents, and did so unpredictably.
I suspect that Firefox's JIT may be affecting things, because my test case didn't always trigger at the same point.
In both cases, I was able to modify the code to avoid the problem.
Conclusions
For CueKeeper, I used js_of_ocaml to let me write reliable type-checked OCaml code and compile it to Javascript.
js_of_ocaml is surprisingly easy to use, provides most of the standard DOM APIs and is easy to extend to other APIs such as Pikaday or IndexedDB.
TyXML provides a pleasant way to generate HTML output, checking at compile time that it will produce valid (not just well-formed) HTML.
Functional reactive programming makes it easy to define user interfaces that always show up-to-date information.
However, I had problems with signals leaking or running after they were no longer needed due to the React library's reliance on weak references and the garbage collector to clean up old signals.
If this problem could be fixed, this would be an ideal way to write interactive applications.
As it is, it is still useful but must be used with care.
Data structures are defined in OCaml and (de)serialised automatically using the Sexplib library.
Sexplib is easy to extend with custom behaviour, for example to support changes in the format, but required a minor patch to work reliably in the browser.
Most applications store data using filesystems or relational databases.
CueKeeper uses Irmin to store data in a Git-like repository.
Writing the merge code can be somewhat tricky, but you have to do this anyway if you want your application to support off-line use or multiple users, and once done you get race-free operation, multi-tab support, history and revert for free.
Irmin can be extended with new backends and I created one that uses IndexedDB to store the data client-side in the browser.
The standard is rather new and there are still browser bugs to watch out for, but it seems to be working reliably now.
I hope to get back to working on sync between devices.
I made a start on the server branch, which runs a sync service as a Mirage unikernel, but there's no access control yet, so don't use it unless you want to share your TODO list with the whole world!
However, I got distracted by an interesting TCP bug, where a connection would sometimes hang, and wondering what caused that made me think there should be a way to ask the system why a thread didn't resolve, which resulted in some interesting improvements to the tracing and visualisation system...
Acknowledgements
Some of the research leading to these results has received funding from the European Union's Seventh Framework Programme FP7/2007-2013 under the UCN project, grant agreement no 611001.
]]>CueKeeper: Gitting Things Done in the browser2015-04-28T10:18:23+00:00https://roscidus.com/blog/blog/2015/04/28/cuekeeper-gitting-things-done-in-the-browserGit repositories store data with history, supporting replication, merging and revocation.
The Irmin library lets applications use Git-style storage for their data.
To try it out, I've written a GTD-based action tracker that runs entirely client-side in the browser.
CueKeeper uses Irmin to handle history and merges, with state saved in the browser using the new IndexedDB standard (requires a recent browser; Firefox 37, Chromium 41 and IE 11.0.9600 all work, but Safari apparently has problems if you open the page in multiple tabs).
In the future, I plan to have the browser sync to a master Git repository and use the browser storage only for off-line use, but for now note that:
All data is stored only in your browser.
There is no server communication.
Any changes you make will persist for you, but will not affect other users.
Mozilla's IndexedDB docs say that "the general philosophy of the browser vendors is to make the best effort to keep the data when possible", but vaguely notes that your data may be deleted if you run out of space! If someone can clarify things, that would be great. I've been using it for 5 weeks on Firefox, and haven't lost anything, but it would be nice to know the exact conditions for safety.
Take backups! On my Linux/Firefox system, the data is stored here: $HOME/.mozilla/firefox/SALT.default/storage/default/http+++roscidus.com/idb
This is version 0.1 alpha ;-)
This post contains a brief introduction to using GTD and CueKeeper, followed by a look at some nice features that result from using Irmin.
The code is available at https://github.com/talex5/cuekeeper.
Alpha testers welcome!
The core idea behind David Allen's GTD is: the human brain is terrible at remembering things at the right time:
You go into work in the morning thinking about a phone call you need to make this evening.
As you read through your emails, you keep reminding yourself to remember the call.
You're in a meeting and someone is speaking. You're thinking you shouldn't forget the call.
etc
Maybe you end up remembering and maybe you don't, but either way you've distracted yourself all day from the other things you wanted to work on.
The goal of using GTD is to have a system where:
the system reminds you of things when you need to be reminded about them, and
you trust it enough that your brain can stop thinking about them until then.
There is no reason ever to have the same thought twice, unless you like having that thought.
Irmin
Irmin is "a library for persistent stores with built-in snapshot, branching and reverting mechanisms". It has multiple backends (including one that uses a regular Git repository, allowing you to view and modify your application's data using the real git commands).
Git's storage model is useful for many applications because it gives you race-free updates (each worker writes to its own branch and then merges), disconnected operation, history, remote sync and incremental backups.
Simon Baird's mGSD is an excellent GTD system, which I've been using for the last few years.
It's a set of extensions built on the TiddlyWiki "personal wiki" system.
Like CueKeeper, mGSD runs entirely in your browser and doesn't require a server.
It's implemented as a piece of self-modifying HTML that writes itself back to your local disk when you save.
That's pretty scary, but I've found it surprisingly robust.
However, it's largely unmaintained and there were various areas I wanted to improve:
Browser security
Over the years, browsers have become more locked down, and no longer allow web-pages to write to the disk,
requiring a browser plugin to override the check.
CueKeeper uses the IndexedDB support that modern browsers provide to store data (mGSD pre-dates IndexedDB).
History
Sometimes you click on a button by mistake and have no idea what changed.
Thanks to Irmin, CueKeeper logs all changes and provides the ability to view earlier states.
Also, CueKeeper uses brief animations to make it easier to see what changed.
Navigation
Navigation in mGSD can be awkward because overview panels and details are all mixed in together as wiki pages.
With CueKeeper, I'm experimenting with a two-column layout to separate overview pages from the details.
Safe multi-tab use
If you accidentally open mGSD in two tabs, changes in one tab will overwrite changes made in the other. CueKeeper uses Irmin to keep multiple tabs in sync, merging changes between them automatically.
Sync between devices
There's no easy way to Sync multiple mGSD instances. CueKeeper doesn't implement sync yet either, but it should be easy to add (it can sync between tabs already, so the core logic is there).
Escaping bugs
mGSD has various bugs related to escaping (e.g. things will go wrong if you use square brackets in a title). CueKeeper uses type-safe TyXML to avoid such problems.
Stale-display bugs
mGSD mostly does a good job of keeping all elements of the display up-to-date, but there are some flaws.
For example, if you add a new contact in one panel, then open the contacts menu from another, the new contact doesn't show up.
CueKeeper uses Functional reactive programming with the React library to make sure everything is current.
Clean separation of code and data
As a self-modifying .html file, updating mGSD is terrifying! CueKeeper can be recompiled and reloaded like any other program.
Nymote, MirageOS and UCN
The Nymote project describes itself as "Lifelong control of your networked personal data":
By adopting large centralised services we've answered the call of the siren servers and made an implicit trade. That we will share our habits and data with them in exchange for something useful. In doing so we've empowered internet behemoths while simultaneously reducing our ability to influence them. We risk becoming slaves to the current system unless we can create alternatives that compete. It's time to work on those alternatives.
The idea here is to provide services that people can run in their own homes (e.g. on a PC, a low-powered ARM board, or the house router).
The three key pieces of infrastructure it needs are Mirage, Irmin and Signpost.
I've talked about MirageOS before (see My first unikernel): it allows you to run extremely small, highly secure services as Xen guests (a few MB in size, written in type-safe OCaml, rather than 100s of MB you would have with a Linux guest).
I haven't looked at Signpost yet.
Irmin is the subject of this blog post.
UCN (User Centric Networking) is an EC-funded project that is building a "Personal Information Hub" (PIH), responsible for storing users' personal data in their home, and then using that data for content recommendation.
If you use Google to manage your ToDo-list then when you add "Book holiday" to it, Google can show you relevant ads.
But what if you want good recommendations without sharing personal data with third parties?
Tools such as CueKeeper could be configured to sync with a local PIH to provide input for its recommendations without the data leaving your home.
Using CueKeeper
You can either use the example on roscidus.com, or download the standalone release cuekeeper-bin-0.1.zip.
To use the release, unzip the directory and open index.html in a browser (no need for a web-server).
If you do this, note that the database is tied to the path of the file, so if you move or rename the directory, it will show a different database (which might make it look like your items have disappeared).
Core concepts
There are five kinds of "thing" in CueKeeper:
Action
Something you will do (e.g. "Follow Mirage tutorial").
Beside each action you will see some toggles showing its state:
The tick means done,
"n" is a next action (something you could start now),
"w" means waiting-for (something you can't start now),
"f" means future (something you don't want to think about yet).
The star is for whatever you want.
Repeating actions can't be completed, so for those the tick box will be blank.
Project
Something you want to achieve (e.g. "Make a Mirage unikernel").
A project may require several actions to be taken.
The possible states are done (the tick),
"a" for active projects,
and "sm" for "Someday/Maybe" (a project you don't plan to work on yet).
Area
An "Area of responsibility" is a way of grouping things (e.g. "Personal/Hobbies" or "Job/Accounts").
Unlike projects, areas generally cannot be completed.
One thing that confused me when I started with GTD was that what my organisation called "projects" were actually areas.
If your boss says "You're working on project X until further notice" then "X" is probably an "area" in GTD terms.
Contact
Someone you work with.
You can associate any area, project or action with a contact, which provides a quick way to find all the things you need to discuss with someone when you meet them.
If an action is being performed by someone else, you can also mark it as waiting for them.
It will then appear on the Review/Waiting list.
Context
Another way of grouping actions, by what kind of activity it is, or where it will occur.
Assigning a context to an action is an important check that the action isn't too vague.
Your eye will tend to glide over vague actions like "Sort out car"; choosing a context "Phone" (garage) or "Shopping" (buy tools) forces you to clarify things.
Notes:
GTD also has the concept of a "tickler". In CueKeeper this is just an action waiting until some time.
GTD also has "reference material", but I never used this in mGSD, so I didn't implement it.
Regular files on your computer seem to work fine for this.
mGSD has the concept of "realms" to group areas. CueKeeper uses sub-areas for this instead (e.g. CueKeeper's "Personal/Health" sub-area corresponds to an mGSD "Health" area within a "Personal" realm).
Editing items
Clicking on an item or creating a new one opens a panel showing its details in the right column.
There are various things you can edit here:
The toggles here work just as elsewhere (see above).
Click the title to rename.
Click (edit) to edit the notes.
These can be whatever you like.
They're in Markdown format, so you can add structure, links, etc.
Click (add log entry) to start editing with today's date added at the end.
This is convenient to add date-stamped notes quickly.
The (delete) button at the bottom will remove it (without confirmation; use Show history to revert accidental deletions, as explained later).
For areas, projects and actions:
You can convert between these types by clicking on the type (e.g. "An action in ...").
This is useful if e.g. you realise that an action is really a project with multiple steps.
Click on the parent to move it to a different parent.
You can set the contact field for any of these types too.
For actions, you can also set the context, which is useful for grouping actions on the Work page, and helps to make sure the action is well-defined.
You can also make an action repeat.
Setting the repeat for an action will move it to the waiting state until the given date.
There are only two differences between repeating actions and regular (one-shot) scheduled actions:
You can't mark a repeating action as done (clear the repeat first if you want to).
When you click on the "w" on a repeating action, the next repeat date after it was last scheduled is highlighted by default. If that date has already arrived, it keeps moving it forward by the specified interval until it's in the future.
Processing
There are several stages to applying GTD, corresponding to the tabs along the top.
The first is processing, which is about going through your various inboxes (email, paper, voicemail, etc) and determining what actions each item requires.
After processing, your inbox should be empty and everything you need to do either done (for quick items) or recorded in CueKeeper.
Also, see if you can think of any projects or actions that are only in your head and add those too.
Click the + next to an area and enter a name for the new project.
(the Work tab will go red at this point, indicating an alert: "Active project with no next action")
Click (edit) in the new project panel to add some details, if desired.
Click +action to add the next action to perform towards this project.
Note that it is not necessary to add all the actions needed to complete the project.
Just add the next thing that you can do now.
When you later mark the action as done, CueKeeper will then prompt you to think about a new next action.
If a project will only require a single action (e.g. "Buy milk"), then instead of adding a project and an action, you can just convert the new project to an action and not bother about having a project at all.
If you don't plan to work on the project soon, click "sm" to convert it to a "Someday/Maybe" project.
Work
This is the default view, showing all the things you could be working on now.
The filters just below the tab allow you to hide top-level areas (e.g. if you don't want to see any personal actions while you're at work).
When an item is done, click on the tick mark.
If it's not possible to start it now, click on the "w" to mark it as waiting:
If an action is waiting for someone else, first add them as the contact, then click the w and select "Waiting for name" from the menu.
If an action can't be started until some date, click the "w" and choose the date from the popup calendar.
Otherwise, you can mark it as "Waiting (reason unspecified)".
If you're not going to do it this week, click on the "f" (future) to defer it until the next review.
Contact
This view lists your contacts and any actions you're waiting for them to do.
It's useful if someone phones and you want to see everything you need to discuss with them, for example.
The list only shows actions you're actually waiting for, but if you open up a particular contact then you'll also see things they're merely associated with.
Schedule
Lists actions than can't be done until some date.
When due, scheduled actions will appear highlighted on the Work tab (even if their area is filtered out).
If you pin the browser tab showing the CueKeeper page, the tab icon will also go red to indicate attention is needed.
If you want to test the effect, schedule an action for a date in the past.
Click n to acknowledge a due action and convert it to a next action.
The weekly review
GTD only works if you trust yourself to look at the system regularly.
There are various reports available under the Review tab to help with this.
The available reports are:
Done shows completed actions and projects and provides a button to delete them all.
If you're the sort of person who likes to write weekly summaries, this might be useful input to that.
Waiting shows actions that are waiting for someone or something (but not scheduled actions).
You might want to check up on the status of these, or do something to unblock them.
Future shows all actions you marked as "Future" and all projects you marked as "Someday/Maybe".
Areas lists all your areas of responsibility.
Everything shows every item in the system in one place (you don't need to review this; it's just handy sometimes to see everything).
mGSD has more reports, but these are the ones I use.
The default configuration has a repeating action scheduled for next Sunday to review things.
This is what I do:
Process tab
Empty inboxes, adding any actions to CueKeeper:
email inbox
paper inbox
Review/Done
Admire done list, then delete all.
Review/Waiting
Any reminders needed?
Review/Future
Make any of these current?
Delete any that will never get done.
Review/Areas
Any areas that need new projects?
Work
Make sure each action is obvious (not vague).
Could it be started now? Set to Waiting if not.
List too long? Mark some actions as Future, or their projects as Someday/Maybe.
It's important to look at all these items during the review.
Knowing you're going to look at each waiting or future item soon is what allows you to forget about them during the rest of the week!
The top-right controls
To search, enter some text (or a regular expression) into the box and select from the drop-down menu that appears.
Pressing Return opens the first result.
To create a new items, enter a label for it and select one of the "Add" items from the menu.
Pressing Return when there are no search results will create a new action.
Export allows you to save the current state (without history) as a tar file.
There's no import feature currently, though.
Show history shows some recent entries from the Irmin log (see below).
Interesting Irmin features
So, what benefits do we get from using Irmin?
Sync
The first benefit, of course, is that we can synchronise between multiple instances.
You may have already tried opening CueKeeper in two windows (of the same browser) and observed that changes made in one propagate to the other.
Here's an easier way to experiment with sync (click the screenshot for the interactive version):
This page has two instances of CueKeeper running, representing two separate devices such as a laptop and mobile phone.
You can edit them separately and then click the buttons in the middle to see how the changes are merged.
Clicking Upper to lower pushes all changes from the upper pane to the lower (the lower instance will merge them with its current state). Clicking Lower to upper does the reverse. A full sync would do these two in sequence, but of course it could be interrupted part way through.
The "Criss-cross" button can be used to test the unusual-but-interesting case of merging in both directions simultaneously (i.e. each instance merges with the previous state of the other instance, generating two new merges). CueKeeper tries to merge deterministically, so that both instances should end up in the same state, avoiding unnecessary conflicts on future merges.
Where you make conflicting edits, CueKeeper will pick a suitable resolution and add a conflict note to say what it did.
For example, if you edit the title of the "Try OCaml tutorials" action to different strings in each instance and then sync, you'll see something like:
CueKeeper uses a three-way merge - the merge algorithm takes the states of the two branches to be merged and their most recent common ancestor, and generates a new commit from these.
The common ancestor is used to determine which branch changed which things (anything that is the same as in the common ancestor wasn't changed on that branch).
If there are multiple possible ancestors (which can happen after a criss-cross merge) we just pick one of them.
CueKeeper has a unit test for merging that repeatedly generates three commits at random and ensures the merge code produces a valid (loadable) result.
This should ensure that we can merge any pair of states, but it can't check that the result will necessarily seem sensible to a human, so let me know if you spot anything odd!
History
We have the full history, which you can view with the Show history button:
The history view is useful if you clicked on something by accident and you're not sure what you did.
Click on an entry to see the state of the system just after that change.
A box appears at the top of the page to indicate that you're in "time travel" mode - close the box to return to the present.
If you edit anything while viewing a historical version, CueKeeper will commit against that version and then merge the changes to master and return to the present.
You might like to open each instance's history panel while trying the sync demo above.
Revert
When in time-travel mode, you can click on the Revert this change button there to undo the change.
Reverting was easy to add, as it reuses the existing three-way merge code.
The only difference is that the "common ancestor" is the commit being reverted and the parent of that commit is used as the "branch" to be merged.
Because CueKeeper can merge any three commits, it can also revert any commit (with a single parent), although you'll get the most sensible results if you revert the most recent changes first.
For example, if you create an action and then modify it, and then revert the creation then CueKeeper will see that as:
One branch that modified the action (the main branch).
One branch that deleted the action (the revert of the creation).
When something is modified and deleted, CueKeeper will opt to keep it, so the effect of the "revert" will simply be to add a note that it decided to keep it.
Of course, the sensible way to delete something is to use the regular (delete) button.
Check-before-merge
It's important to make sure that the system doesn't get into an inconsistent state, and Irmin can help here.
Whenever CueKeeper updates the database, it first generates the new commit, then it loads the new commit to check it works, then it updates the master branch to point at the new commit.
This means that CueKeeper will never put the master branch into a state that it can't itself load.
Out-of-date UI actions
Perhaps the most interesting effect of using Irmin is that it eliminates various edge cases related to out-of-date UI elements.
Consider this example:
You open a menu in one tab to set the contact for an action.
You delete one of the contacts in another tab.
You choose the deleted contact from the menu in the first tab.
With a regular database, this would probably result in some kind of error that you'd need to handle.
These edge cases don't occur often and are hard to test.
With CueKeeper though, we record which revision each UI element came from and commit against that revision.
We then merge the new commit with the master branch, using the existing merge logic to deal with any problems (normally, there is nothing to merge and we do a trivial "fast-forward" merge here).
This means we never have to worry about concurrent updates.
A similar system is used with editable fields.
When you click on a panel's title to edit it, make some changes and press Return, we commit against the version you started editing, not the current one.
This means that CueKeeper won't silently overwrite changes, even if you edit something in two tabs at the same time (you'll get a merge conflict note containing the version it discarded instead).
Next steps
If you'd like to help out, there's still plenty more to do, both coding and testing.
For example:
Editing doesn't work well on mobile phones. Menus and input boxes should fill the screen in this case.
I've had reports that merging between tabs is unreliable on Safari for some reason (AbortError from IndexedDB).
It would be good to use pack files for compression. Needs a JavaScript compression library.
It should be possible for an action to be marked as waiting for some other action or project to be completed.
Remote sync needs to be implemented.
The UI needs some work. In particular, could someone find a tasteful way to style the fields in the panels so they look like drop-downs? I keep clicking on the item's name instead of the (show) button by mistake (although this might be because I used to have it the other way around, with a (change) button, but that was worse).
CueKeeper's IndexedDB Irmin backend should be split off so other people can use it easily.
Some of the research leading to these results has received funding from the European Union's Seventh Framework Programme FP7/2007-2013 under the UCN project, grant agreement no 611001.
]]>Securing the Unikernel2015-01-21T10:03:08+00:00https://roscidus.com/blog/blog/2015/01/21/securing-the-unikernelBack in July, I used MirageOS to create my first unikernel, a simple REST service for queuing file uploads, deployable as a virtual machine.
While a traditional VM would be a complete Linux system (kernel, init system, package manager, shell, etc), a Mirage unikernel is a single OCaml program which pulls in just the features (network driver, TCP stack, web server, etc) it needs as libraries.
Now it's time to look at securing the system with HTTPS and access controls, ready for deployment.
As a quick reminder, the service ("Incoming queue") accepts uploads from various contributors and queues them until the (firewalled) repository software downloads them, checks the GPG signatures, and merges them into the public software repository, signed with the repository's key:
Although the queue service isn't security critical, since the GPG signatures are made and checked elsewhere, I would like to ensure it has a few properties:
Only the repository can fetch items from the queue.
Only authorised users can upload to it.
I can see where an upload came from and revoke access if necessary.
An attacker cannot take control of the system and use it to attack other systems.
We often think of security as a set of things we want to prevent - taking away possible actions from a fundamentally vulnerable underlying system (such as my original implementation, which had no security features).
But ideally I'd like every component of the system to be isolated by default, with allowed interactions (shown here by arrows) specified explicitly.
We should then be able to argue (informally) that the system will meet the goals above without having to verify that every line of code is correct.
My unikernel is written in OCaml and runs as a guest OS under the Xen hypervisor, so let's look at how well those technologies support isolation first...
OCaml
I want to isolate the components of my unikernel, giving each just the access it requires.
When writing an OS, some unsafe code will occasionally be needed, but it should be clear which components use unsafe features (so they can be audited more carefully), and unsafe features shouldn't be needed often.
For example, the code for handling an HTTP upload request should only be able to use our on-disk queue's Uploader interface and its own HTTP connection.
Then we would know that an attacker with upload permission can only cause new items to be added to the queue, no matter how buggy that code is.
It should not be able to read the web server's private key, establish new out-bound connections, corrupt the disk, etc.
Like most modern languages, OCaml is memory-safe, so components can't interfere with each other through buggy pointer arithmetic or unsafe casts of the kind commonly found in C code.
But we also need to avoid global variables, which would allow two components to communicate without us explicitly connecting them.
I can't reason about the security of the system by looking at arrows in the architecture diagrams if unconnected components can magically create new arrows by themselves!
I've seen a few interesting approaches to this problem (please correct me if I've got this wrong):
Haskell
Haskell avoids all side-effects, which makes global variables impossible (without using "unsafe" features), since updating them would be a side-effect.
Rust
Rust almost avoids the problem of globals through its ownership types.
Since only one thread can have a pointer to a mutable value at a time, mutable values can't normally be global.
Rust does allow "mutable statics" (which contain only pointers to fixed data), but requires an explicit "unsafe" block to use them, which is good.
E
E allows modules to declare top-level variables, but each time the module is imported it creates a fresh copy.
OCaml does allow global variables, but by convention they are generally not used.
A second problem is controlling access to the outside world, including the network and disks (which you could consider to be more global variables):
Haskell
Haskell doesn't allow functions to access the outside world at all, but they can return an IO type if they want to do something (the caller must then pass this value up to the top level).
This makes it easy to see that e.g. evaluating a function "uriPath :: URI -> String" cannot access the network.
However, it appears that all IO gets lumped in together: a value of type IO String may cause any side-effects at all (disk, network, etc), so the entire side-effecting part of the program needs to be audited.
Rust
Rust allows all code full access to the system via its standard library.
For example, any code can read or write any file.
E
E passes all access to the outside world to the program's entry point.
For example, <file> grants access to the file system and <unsafe> grants access to all unsafe features.
These can be passed to libraries to grant them access, and can be attenuated (wrapped) to provide limited access.
Here, queue has read-write access to the /var/myprog/queue sub-tree (and nothing else).
It also has no way to share data with any other parts of the program, including other queues.
Like Rust, OCaml does not limit access to the outside world.
However, Mirage itself uses E-style dependency injection everywhere, with the unikernel's start function being passed all external resources as arguments:
Because everything in Mirage is defined using abstract types, libraries always expect to be passed the things they need explicitly.
We know that Upload_queue above won't access a block device directly because it needs to support different kinds of block device.
OCaml does enforce its abstractions.
There's no way for the Upload_queue to discover that block is really a Xen block device with some extra functionality
(as a Java program might do with if (block instanceof XenBlock), for example).
This means that we can reason about the limits of what functions may do by looking only at their type signatures.
The use of functors means you can attenuate access as desired.
For example, if we want to grant just part of block to the queue then we can create our own module implementing the BLOCK type that exposes just some partition of the device, and pass that to the Upload_queue.Make functor.
In summary then, we can reason about security fairly well in Mirage if we assume the libraries are not malicious, but we cannot make hard guarantees.
It should be possible to check with automatic static analysis that we're not using any "unsafe" features such as global variables, direct access to devices, or allocating uninitialised memory, but I don't know of any tools to do that (except Emily, but that seems to be just a proof-of-concept).
But these issues are minor: any reasonably safe modern language will be a huge improvement over legacy C or C++ systems!
Xen
The Xen hypervisor allows multiple guest operating systems to run on a single physical machine.
It is used by many cloud hosting providers, including Amazon's AWS.
I run it on my CubieTruck - a small ARM board.
Xen allows me to run my unikernel on the same machine as other services, but ideally with the same security properties as if it had its own dedicated machine.
If some other guest on the machine is compromised, it shouldn't affect my unikernel, and if the unikernel is compromised then it shouldn't affect other guests.
A typical Xen deployment, running four domains.
The diagram above shows a deployment with Linux and Mirage guests. Only dom0 has access to the physical hardware; the other guests only see virtual devices, provided by dom0.
How secure is Xen?
The Xen security advisories page shows that there are about 3 new Xen advisories each month.
However, it's hard to compare programs this way because the number of vulnerabilities reported depends greatly on the number of people using the program, whether they use it for security-critical tasks, and how seriously the project takes problems (e.g. whether a denial-of-service attack is considered a security bug).
I started using Xen in April 2014.
These are the security problems I've found myself so far:
XSA-93 Hardware features unintentionally exposed to guests on ARM
While trying to get Mini-OS to boot, I tried implementing ARM's recommended boot code for invalidating the cache
(at startup, you should invalidate the cache, dropping any previous contents).
When running under a hypervisor this should be a null-op since the cache is always valid by the time a guest is running, but Xen allowed the operation to go ahead, discarding pending writes by the hypervisor and other guests and crashing the system.
This could probably be used for a successful attack.
I tried to program an out-of-range register, causing the hypervisor to dereference a null pointer and panic.
This is just a denial of service (the host machine needs to be rebooted); it shouldn't allow access to other VMs.
XSA-95 : Input handling vulnerabilities loading guest kernel on ARM
I got the length wrong when creating the zImage for the unikernel (I included the .bss section in the length).
The xl create tool didn't notice and tried to read the extra data, causing the tool to segfault.
You could use this to read a bit of private data from the xl process, but it's unlikely there would be anything useful there.
Although that's more bugs than you might expect, note that they're all specific to the relatively new ARM support.
The second and third are both due to using C, and would have been avoided in a safer language.
I'm not really sure why the "xl" tool needs to be in C - that seems to be asking for trouble.
To drive the physical hardware, Xen runs the first guest (dom0) with access to everything.
This is usually Linux, and I had various problems with that. For example:
Linux got confused when the unikernel shared the same page twice (it split a single page of RAM into multiple TCP segments).
This wasn't a security bug (I think), but after it was fixed, I then got:
The Linux dom0 initialises the virtual network device while the VM is booting.
My unikernel booted fast enough to send packets before the device structure had been fully filled in, leading to an oops.
Sending lots of block device requests to Linux dom0 from the unikernel would cause Linux to oops in swiotlb_tbl_unmap_single and reboot the host.
I wasn't the first to find this though, and backporting the patch from Linux 3.17 seemed to fix it (I don't actually know what the problem was).
So it might seem that using Xen doesn't get us very far.
We're still running Linux in dom0, and it still has full access to the machine.
For example, a malicious network packet from outside or from a guest might still give an attacker full control of the machine.
Why not just use KVM and run the guests under Linux directly?
The big (potential) advantage of Xen here is Dom0 Disaggregation.
With this, Dom0 gives control of different pieces of physical hardware to different VMs rather than driving them itself.
For example, Qubes (a security-focused desktop OS using Xen) runs a separate "NetVM" Linux guest just to handle the network device.
This is connected only to the FirewallVM - another Linux guest that just routes packets to other VMs.
This is interesting for two reasons.
First, if an attacker exploits a bug in the network device driver, they're still outside your firewall.
Secondly, it provides a credible path to replacing parts of Linux with alternative implementations, possibly written in safer languages.
You could, for example, have Linux running dom0 but use FreeBSD to drive the network card, Mirage to provide the firewall, and OpenBSD to handle USB.
Finally, it's worth noting that Mirage is not tied to Xen, but can target various systems (mainly Unix and Xen currently, but there is some JavaScript support too).
If it turns out that e.g. Genode on seL4 (a formally verified microkernel) provides better security, we should be able to support that too.
Transport Layer Security
We won't get far securing the system while attackers can read and modify our communications.
The ocaml-tls project provides an OCaml implementation of TLS (Transport Layer Security), and
in September Hannes Mehnert showed it running on Mirage/Xen/ARM devices.
Given the various flaws exposed recently in popular C TLS libraries, an OCaml implementation is very welcome.
Getting the Xen support in a state where it could be widely used took a bit of work, but
I've submitted all the patches I made, so it should be easier for other people now - see https://github.com/mirage/mirage-dev/pull/52.
C stubs for Xen
TLS needs some C code for the low-level cryptographic functions, which have to be constant time to avoid leaking information about the key, so first I had to make packages providing versions of libgmp, ctypes, zarith and nocrypto compiled to run in kernel mode.
The reason you need to compile C programs specially to run in kernel mode is because on x86 processors user mode code can assume the existence of a red zone, which allows some optimisations that aren't safe in kernel mode.
Ethernet frame alignment
The Mirage network driver sends Ethernet frames to dom0 by sharing pages of memory.
Each frame must therefore be contained in a single page.
The TLS code was (correctly) passing a large buffer to the TCP layer, which incorrectly asked the network device to send each TCP-sized chunk of it.
Chunks overlapping page boundaries then got rejected.
My previous experiments with tracing the network layer had shown that we actually share two pages for each packet: one for the IP header and one for the payload.
Doing this avoids the need to copy the data to a new buffer, but adds the overhead of granting and revoking access to both pages.
I modified the network driver to copy the data into a single block inside a single page and got a large speed boost.
Indeed, it got so much faster that it triggered a bug handling full transmit buffers - which made it initially appear slower!
In addition to fixing the alignment problem when using TLS, and being faster, this has a nice security benefit:
the only data shared with the network driver domain is data explicitly sent to it.
Before, we had to share the entire page of memory containing the application's buffer, and there was no way to know what else might have been there.
This offers some protection if the network driver domain is compromised.
HTTP API
My original code configured a plain HTTP server on port 8080 like this:
stack creates TCP/IP stack.
conduit_direct can dynamically select different transports (e.g. http or vchan).
http_server applies the configuration to the conduit to get an HTTP server using plain HTTP.
I added support to Conduit_mirage to let it wrap any underlying conduit with TLS.
However, the configuration needed for TLS is fairly complicated, and involves a secret key which must be protected.
Therefore, I switched to creating only the conduit in config.ml and having the unikernel itself load the key and certificate by copying a local "keys" directory into the unikernel image as a "crunch" filesystem:
This runs a secure HTTPS server on port 8443.
The rest of the code is as before.
The private key
The next question is where to store the real private key.
The examples provided by the TLS package compile it into the unikernel image using crunch, but it's common to keep unikernel binaries in Git repositories and people don't expect kernel images to contain secrets.
In a traditional Linux system, we'd store the private key on the disk, so I decided to try the same here.
(I did think about storing the key encrypted in the unikernel and storing the password on the disk so you'd need both to get the key, but the TLS library doesn't support encrypted keys yet.)
I don't use a regular filesystem for my queuing service, and I wouldn't want to share it with the key if I did, so instead I reserved a separate 4KB partition of the disk for the key.
It turned out that Mirage already has partitioning support in the form of the ocaml-mbr library.
I didn't actually create an MBR at the start, but just used the Mbr_partition functor to wrap the underlying block device into two parts.
The configuration looks like this:
How safe is this?
I don't want to audit all the code for handling the queue, and I shouldn't have to: we can see from the diagram that the only components with access to the key are the disk, the partitions and the TLS library.
We need to trust that the TLS library will protect the key (not easy, but that's its job) and that queue_partition won't let queue access the part of the disk with the key.
We also need to trust the disk, but if the partitions are only allowing correct requests through, that shouldn't be too much to ask.
The partition code
Before relying on the partition code, we'd better take a look at it because it may not be designed to enforce security.
Indeed, a quick look at the code shows that it isn't:
1234567891011
letreadtstart_sectorbuffers=letlength=Int64.addstart_sector(lengthbuffers)iniflength>t.length_sectorsthenreturn(`Error(`Unknown(Printf.sprintf"read %Ld %Ld out of range"start_sectorlength)))elseB.readt.b(Int64.addstart_sectort.start_sector)buffersletwritetstart_sectorbuffers=letlength=Int64.addstart_sector(lengthbuffers)iniflength>t.length_sectorsthenreturn(`Error(`Unknown(Printf.sprintf"write %Ld %Ld out of range"start_sectorlength)))elseB.writet.b(Int64.addstart_sectort.start_sector)buffers
It checks only that the requested start sector plus the length of the results buffer is less than the length of the partition.
To (hopefully) make this bullet-proof, I:
moved the checks into a single function so we don't have to check two copies,
added a check that the start sector isn't negative,
modified the end check to avoid integer overflow, and
added some unit-tests.
12345678910
letadjust_startnameoptstart_sectorbuffers=letbuffers_len_sectors=lengthtbuffersinifstart_sector<0L||start_sector>t.id.length_sectors--buffers_len_sectorsthenreturn(`Error(`Unknown(Printf.sprintf"%s %Ld+%Ld out of range"namestart_sectorbuffers_len_sectors)))elseopt.id.b(Int64.addstart_sectort.id.start_sector)buffersletread=adjust_start"read"B.readletwrite=adjust_start"write"B.write
The need to protect against overflow is an annoyance.
OCaml's Int64.(add max_int one) doesn't abort, but returns Int64.min_int.
That's disappointing, but not surprising.
I wrote a unit-test that tried to read sector Int64.max_int and ran it (before updating the code) to check it detected the problem.
I was expecting the partition code to pass the request to the underlying block device, which I expected to return an error about the invalid sector, but it didn't!
It turns out, Int64.to_int (used by my in-memory test block device) silently truncates out-of-range integers:
So, if the queue can be tricked into asking for sector 9223372036854775807 then the partition would accept it as valid and the block device would truncate it and give access to sector 0 - the sector with the private key!
Still, this is a nice demonstration of how we can add security in Mirage by inserting a new module (Mbr_partition) between two existing ones.
Rather than having some complicated fixed policy language (e.g. SELinux), we can build whatever security abstractions we like.
Here I just limited which parts of the disk the queue could access, but we could do many other things: make a partition read-only, make it readable only until the unikernel finishes initialising, apply rate-limiting on reads, etc.
Here's the final code. It:
Takes a block device, a conduit, and a KV store as inputs.
Creates two partitions (views) onto the block device.
Creates a queue on one partition.
Reads the private key from the other, and the certificate from the KV store.
Entropy_xen: attempting to connect to Xen entropy source org.openmirage.entropy.1
Console.connect org.openmirage.entropy.1: doesn't currently exist, waiting for hotplug
Now run xentropyd in dom0 to share the host's entropy with guests.
The interesting question here is what Linux guests do for entropy, especially on ARM where there's no RdRand instruction.
Access control
Traditional means of access control involve issuing users with passwords or X.509 client certificates, which they share with the software they're running.
All requests sent by the client can then be authenticated as coming from them and approved based on some access control policy.
This approach leads to all the well-known problems with traditional access control: the confused deputy problem, Cross-Site Request Forgery, Clickjacking, etc, so I want to avoid that kind of "ambient authority".
The previous diagram let us reason about how the different components within the unikernel could interact with each other, showing the possible (initial) interactions with arrows.
Now I want to stretch arrows across the Internet, so I can reason in the same way about the larger distributed system that includes my queue service with the uploaders and downloaders.
Like C pointers, traditional web URLs do not give us what we want: a compromised CA anywhere in the world will allow an attacker to impersonate our service, and our URLs may be guessable.
Instead, I decided to try a YURL:
"[...] the identifier MUST provide enough information to: locate the target site; authenticate the target site; and, if required, establish a private communication channel with the target site. A URL that meets these requirements is a YURL."
The latest version of this (draft) scheme I could find was some brief notes in HTTPSY (2014), which uses the format:
There are two parts we need to consider: how the client determines that it is connected to the real service, and how the service determines what the client can do.
To let the client authenticate the server without relying on the CA system, YURLs include a hash (fingerprint) of the server's public key.
You can get the fingerprint of an X509 certificate like this:
To control what each user of the service can do, we give each user a unique YURL containing a Swiss number, which is like a password except that it applies only to a specific resource, not to the whole site.
The Swiss number comes after the ! in the URL, which indicates to browsers that it shouldn't be displayed, included in Referer headers, etc.
You can use any unguessably long random string here (I used pwgen 32 1).
After checking the server's fingerprint, the client requests the path with the Swiss number included.
Putting it all together, then, a sample URL to give to the downloader looks like this:
I hashed the Swiss number here so that the unikernel doesn't have to contain any secrets and I therefore don't have to worry about timing attacks.
Even if the attacker knows the hash we're looking for, they still shouldn't be able to generate a URL which hashes to that value.
By giving each user of the service a different Swiss number we can keep records of who authorised each request and revoke access individually if needed (here the ~user:"Alice" indicates this is the uploader URL we gave to Alice).
Of course, the YURLs need to be sent to users securely too.
In my case, the users already have known GPG keys, so I can just email them an encrypted version.
Python client
The downloader (0repo) is written in Python, so the next step was to check that it could still access the service.
The Python SSL API was rather confusing, but this seems to work:
#!/usr/bin/python3fromurllib.parseimporturlparsefromhttpimportclientimportsslimporthashlibimportbase64# Note: MUST check fingerprint BEFORE sending URL path with Swiss numberclassFingerprintContext:required_fingerprint=Noneverify_mode=ssl.CERT_REQUIREDcheck_hostname=Falsedef__init__(self,fingerprint):self.required_fingerprint=fingerprintdefwrap_socket(self,sock,server_hostname,**kwargs):wrapped=ssl.wrap_socket(sock,**kwargs)cert=wrapped.getpeercert(binary_form=True)actual_fingerprint=base64.b32encode(hashlib.sha256(cert).digest()).lower().decode('ascii').strip('=')ifactual_fingerprint!=self.required_fingerprint:raiseException("Expected server certificate to have fingerprint:\n%s but got:\n%s"%(self.required_fingerprint,actual_fingerprint))returnwrapped# Testing...url="httpsy://sha256:h4ts3zwwhv6aryhd54bkrwu2orriivzbwrzdt7oqoihhm4nf5gka@localhost:8443/downloader/!eequuthieyexahzahShain0abeiwaej4"parsed=urlparse(url)assertparsed.scheme=="httpsy"assertparsed.username=="sha256"conn=client.HTTPSConnection(host=parsed.hostname,port=parsed.port,context=FingerprintContext(parsed.password),check_hostname=False)conn.request("GET",parsed.path)resp=conn.getresponse()print("Fetching item of size %s..."%resp.getheader('Content-Length'))d=resp.read()print("Fetched %d bytes"%len(d))
Conclusions
MirageOS should allow us to build systems that are far more secure than traditional operating systems.
By starting with isolated components and then connecting them together in a controlled way we can feel some confidence that our security goals will be met.
At the language level, OCaml's abstract types and functors make it easy to reason informally about how the components of our system will interact. Mirage passes values granting access to the outside world (disks, network cards, etc) to our unikernel's start function.
Our code can then delegate these permissions to the rest of the code in a controlled fashion.
For example, we can grant the queuing code access only to its part of the disk (and not the bit containing the TLS private key) by wrapping the disk in a partition functor.
Although OCaml doesn't actually prevent us from bypassing this system and accessing devices directly, code that does so would not be able to support the multiple different back-ends (e.g. Unix and Xen) that Mirage requires and so could not be written accidentally.
It should be possible for a static analysis tool to verify that modules don't do this.
Moving up a level from separating the components of our unikernel, Xen allows us to isolate multiple unikernels and other VMs running on a single physical host.
Just as we interposed a disk partition between the queue and the disk within the unikernel, we can use Xen to interpose a firewall VM between the physical network device and our unikernel.
Finally, the use of transport layer security and YURLs allows us to continue this pattern of isolation to the level of networks, so that we can reason in the same way about distributed systems.
My current code mixes the handling of YURLs with the existing application logic, but it should be possible to abstract this and make it reusable, so that remote services appear just like any local service.
In many systems this is awkward because local APIs are used synchronously while remote ones are asynchronous, but in Mirage everything is non-blocking anyway, so there is no difference.
I feel I should put some kind of warning here about these very new security features not being ready for real use and how you should instead use mature, widely deployed systems such as Linux and OpenSSL.
But really, can it be any worse?
]]>Visualising an asynchronous monad2014-10-27T07:21:04+00:00https://roscidus.com/blog/blog/2014/10/27/visualising-an-asynchronous-monadMany asynchronous programs make use of promises (also known as using light-weight threads or an asynchronous monad) to manage concurrency.
I've been working on tools to collect trace data from such programs and visualise the results, to help with profiling and debugging.
The diagram below shows a trace from a Mirage unikernel reading data from disk in a loop.
You should be able to pan around by dragging in the diagram, and zoom by using your mouse's scroll wheel.
If you're on a mobile device then pinch-to-zoom should work if you follow the full-screen link, although it will probably be slow.
If nothing else works, the ugly zoom buttons at the bottom zoom around the last point clicked.
The web viewer requires JavaScript and HTML canvas support.
If it doesn't work, you can also build the trace viewer as a (much faster) native GTK application.
In this post I'll explain how to read these diagrams, and how to trace your own programs.
Many asynchronous programs make use of promises (also known as using light-weight threads or an asynchronous monad).
A promise/thread is a place-holder for a value that will arrive in the future.
Here's a really simple example (an OCaml program using Lwt).
It creates a thread that resolves to unit (void) after one second:
123456789
openLwtopenLwt_unixletexample_1()=sleep1.0let()=(* Run the main loop until example_1 resolves. *)Lwt_unix.run(example_1());
In the diagram, time runs from left to right.
Threads (promises) are shown as horizontal lines.
The diagram shows:
Initially, only the main thread ("0") is present.
The main thread then creates a new thread, labelled "sleep".
The sleep thread is a "task" thread (this is just a helpful label added when the thread is created).
The whole process then goes to sleep for one second, which is shown by the darker background.
At the end of the second, the process wakes up and resolves the sleep thread to its value (unit), shown by the green arrow.
The main thread, which was waiting for the sleep thread, reads the value (the blue arrow) and exits the program.
If you zoom in on the arrows (go down to a grid division of about 10 microseconds), you'll also see a white segment on the main thread, which shows when it was running (only one thread runs at a time).
Because thread 0 is actually the main event loop (rather than a Lwt thread), things are a little more complicated than normal.
When the process has nothing to do, thread 0 puts the process to sleep until the next scheduled timer.
When the OS wakes the process, thread 0 resumes, determines that the "sleep" thread can be resolved, and does so.
This causes any callbacks registered on the sleep thread to be called, but in this case there aren't any and control returns to thread 0.
Thread 0 then checks the sleep thread (because that determines when to finish), and ends the loop because it's resolved.
Bind
Callbacks can be attached to a promise/thread to process the value when it arrives.
Attaching the callback immediately creates a new promise for the final result of the callback.
Here's a program that sleeps twice in series.
The >>= (bind) operator attaches the callback function to the first thread.
I've made the sleeps very short so you can see the process waking up without having to zoom.
123
letexample_2()=sleep0.00001>>=fun()->sleep0.00001
In this case, the main thread creates two new threads at the start: one for the result of the first sleep and a second ("bind") for the result of running the callback on the result.
It's easier to see how the first thread is resolved here: the main thread handling the polling loop wakes up and resolves the sleep thread, which then causes the bind thread to resume.
You might wonder why the bind thread disappears when the second sleep starts.
It hasn't finished, but when the bind's callback function returns the second sleep thread as its result, the bind thread is merged with the sleep thread.
This is the asynchronous equivalent of a tail call optimisation, allowing us to create loops without needing an unbounded number of threads.
Actually, displaying binds in this way tends to clutter up the diagrams, so the viewer has a simplification rule that is enabled by default: if the first event on a bind thread is a read, the part of the bind up to that point isn't drawn.
Therefore, the default display for this program is:
If you zoom in on the central green arrow, you can see the tiny remaining bind thread between the two sleeps.
Join
Lwt.join waits for a collection of threads to finish:
In the trace, you can see the join thread being notified each time one of the threads it's waiting for completes.
When they're all done, it resolves itself.
Choose
Lwt.choose is similar to join, but only waits until one of its threads finishes:
I cheated a bit here.
To avoid clutter, the viewer only draws each thread until its last recorded event (without this, threads that get garbage collected span the whole width of the trace), so I used Profile.label ~thread "(continues)" to create extra label events on the two remaining threads to make it clearer what's happening here.
Pick
Lwt.pick is similar to choose, but additionally cancels the other threads:
Failed threads are shown with a red bar at the end and the exception message is displayed.
Also, any "reads" arrow coming from it is shown in red rather than blue.
Here, the bind thread fails but the try one doesn't because it catches the exception and returns unit.
Note: I'm using the Lwt syntax extension here for try_lwt, but you can use Lwt.try_bind if you prefer.
The same simplification done for "bind" threads also applies to "try" threads, so the try thread doesn't appear at all until you zoom in on the red arrow.
Making your own traces
Update: These instructions were out-of-date so I've removed them. See the mirage-profile page for up-to-date instructions.
Examples
A few months ago, I made my first unikernel - a REST service for queuing files as a Xen guest OS.
Unlike a normal guest, which would include a Linux kernel, init system, libc, shell, Apache, etc, a Mirage unikernel is a single executable, and almost pure OCaml (apart from malloc, the garbage collector, etc).
Unikernels can be very small and simple, and have a much smaller attack surface than traditional systems.
For my first attempt at optimising the unikernel, I used OCaml's built-in profiling support.
This recorded function calls and how much time was spent in each one.
But I quickly discovered that CPU time was rarely the important factor - how the various asynchronous threads were scheduled was more important, and the tracing made it difficult to see this.
So, let's see how the new tracing does on my previous problems...
Profiling the console
In the previous profiling post, I generated this graph using libreoffice:
As a reminder, Xen guests output to the console by writing the text to a shared memory page, increasing a counter to indicate this, and signalling dom0. The console logger in dom0 reads the data, increments another counter to confirm it got it, and signals back to the guest that that part of the buffer is free again.
To use the new tracing system, I added a Profile.note_increase "sent" len to the main loop, which increments a "sent" count on each iteration (i.e. each time we write a line to the console).
The viewer adds a mark on the trace for each increment and overlays a graph (the red line) so you can see overall progress easily:
As before, we can see that we send messages rapidly in bursts, followed by long periods without progress.
Zooming in to the places where the red line is increasing, we can see the messages being written to the buffer without any delays.
Looking at the edges of the sleeping regions, it's clear that we're simply waiting for Xen to notify us of space by signalling us on event channel 2.
Here's the complete test code:
1234567891011121314151617181920212223242526272829
openLwtmoduleMain(C:V1_LWT.CONSOLE)=structlet()=Profile.start~size:10000letstartc=letlen=6inletmsg=String.make(len-1)'X'inletiterations=1800inletbytes=len*iterationsinletrecloop=function|0->return()|i->Profile.note_increase"sent"len;C.log_scmsg>>=fun()->loop(i-1)inlett0=Clock.time()inloopiterations>>=fun()->lett1=Clock.time()inlettime=t1-.t0inC.log_sc(Printf.sprintf"Wrote %d bytes in %.3f seconds (%.2f KB/s)"bytestime(float_of_intbytes/.time/.1024.))>>=fun()->letevents=Profile.events()infor_lwti=0toArray.lengthevents-1doC.log_sc(Profile.to_stringevents.(i))done>>=fun()->OS.Time.sleep1.0end
UDP transmission
Last time, we saw packet transmission being interrupted by periods of sleeping, garbage collection, and some brief but mysterious pauses.
I noted that the GC tended to run during Ring.ack_responses, suggesting that was getting called quite often, and with the new tracing we can see why.
This trace shows a unikernel booting (scroll left if you want to see that) and then sending 10 UDP packets.
I've left the trace running a little longer so you can see the acks (this is very obvious when sending more than 10 packets, but I wanted to keep this trace small):
Mirage creates two threads for each packet that we add to the ring buffer and they stick around until we get a notification back from dom0 that the packet has been read (actually, we create six threads for each packet, but the bind simplification hides four of them).
It looks like each packet is in two parts, as each one generates two acks, one much later than the other.
I think the two parts are the UDP header and the payload, which each have their own IO page.
Given the time needed to share and unshare pages, it would probably be more efficient to copy the payload into the same page as the header.
Interestingly, dom0 seems to ack all the headers first, but holds on to the payload pages for longer.
With 20 threads for just ten packets, you can imagine that the trace gets rather crowded when sending thousands!
The above shows a unikernel running on my ARM Cubietruck connecting to netcat on my laptop and sending 100 TCP packets over the stream.
There are three counters here:
main-to-tcp (purple) is incremented by the main thread just before sending a block of data to the TCP stream (just enough to fill one TCP segment).
tcp-to-ip (red) shows when the TCP system sent a segment to the IP layer for transmission.
tcp-ackd-segs (orange) shows when the TCP system got confirmation of receipt from the remote host (note: a TCP ask is not the same as a dom0 ring ack, which just says the network driver has accepted the segment for transmission).
There is clearly scope to improve the viewer here, but a few things can be seen already.
The general cycle is:
The unikernel is sleeping, waiting for TCP acks.
The remote end acks some packets (the orange line goes up).
The TCP layer transmits some of the buffered packets (red line goes up).
The TCP layer allows the main code to send more data (purple line goes up).
The transmitted pages are freed (the dense vertical green lines) once Xen acks them.
I did wonder whether we unshared the pages as soon as dom0 had read the segment, or only when the remote end sent the TCP ack.
Having the graphs overlaid on the trace lets us answer this question - you can see that when the red line goes up (segments sent to dom0), the ring.write thread that is created then ends (and the page is unshared) in response to ring.poll ack_responses, before the TCP acks arrive.
TCP starts slowly, but as the window size gets bigger and more packets are transmitted at a time, the sleeping periods get shorter and then disappear as the process becomes CPU-bound.
There's also a long garbage collection period near the end (shortly before we close the socket).
This might be partly the fault of the tracing system, which currently allocates lots of small values, rather than writing to a preallocated buffer.
Disk access
For our final example, let's revisit the block device profiling from last time.
Back then, making a series of read requests, each for 32 pages of data, produced this chart:
With the new tracing, we can finally see what those mysterious wake-ups in the middle are:
Each time the main test code's read call returns, the orange trace ("read") goes up.
You can see that we make three blocking calls to dom0 for each request.
I added another counter for the number of active grant refs (pages shared with dom0), shown as the red line ("gntref").
You can see that for each call we share a bunch of pages, wait, and then unshare them all again.
In each group of three, we share 11 pages for the first two requests, but only 10 for the third.
This makes obvious what previously required a careful reading of the block code: requests for more than 11 pages have to be split up because that's all you can fit in the request structure.
Our request for 32 pages is split into requests for 11 + 11 + 10 pages, which are sent in series.
In fact, Xen also supports "indirect" requests, where the request structure references full pages of requests.
I added support for this to mirage-block-xen, which improved the speed nicely.
Here's a trace with indirect requests enabled:
If you zoom in where the red line starts to rise, you can see it has 32 steps, as we allocate all the pages in one go, followed by a final later increment for the indirect page.
Zooming out, you can see we paused for GC a little later.
We got lucky here, with the GC occurring just after we sent the request and just before we started waiting for the reply, so it hardly slowed us down.
If we'd been unlucky the GC might have run before we sent the request, leaving dom0 idle and wasting the time.
Keeping multiple requests in flight would eliminate this risk.
Implementation notes
I originally wrote the viewer as a native GTK application in OCaml.
The browser version was created by running the magical js_of_ocaml tool, which turned out to be incredibly easy.
I just had to add support for the HTML canvas API alongside the code for GTK's Cairo canvas, but they're almost the same anyway.
Now my embarrassing inability to learn JavaScript need not hold me back!
Finding a layout algorithm that produced sensible results was the hardest part.
I'm quite pleased with the result.
The basic algorithm is:
Starting with the root thread, place each thread at the highest place on the screen where it doesn't overlap any other threads, and no higher than its parent.
Visit the threads recursively, depth first, visiting the child threads created in reverse order.
If one thread merges with another, allow them to overlap.
Don't show bind-type threads as children of their actual creator, but instead delay their start time to when they get activated and make them children of the thread that activates them, unless their parent merges with them.
For the vertical layout I originally used scrolling, but it was hard to navigate.
It now transforms the vertical coordinates from the layout engine by passing them through the tanh function, allowing you to focus on a particular thread but still see all the others, just more bunched up.
The main difficulty here is focusing on one of the top or bottom threads without wasting half the display area, which complicated the code a bit.
Summary
Understanding concurrent programs can be much easier with a good visualisation.
By instrumenting Lwt, it was quite easy to collect useful information about what threads were doing.
Libraries that use Lwt only needed to be modified in order to label the threads.
My particular interest in making these tools is to explore the behaviour of Mirage unikernels - tiny virtual machines written in OCaml that run without the overhead of traditional operating systems.
The traces produced provide much more information than the graphs I made previously.
We can see now not just when the unikernel isn't making progress, but why.
We saw that the networking code spends a lot of time handling ack messages from dom0 saying that it has read the data we shared with it, and that the disk code was splitting requests into small chunks because it didn't support indirect requests.
There is plenty of scope for improvement in the tools - some things I'd like include:
A way to group or hide threads if you want to focus on something else, as diagrams can become very cluttered with e.g. threads waiting for shared pages to be released.
The ability to stitch together traces from multiple machines so you can e.g. follow the progress of an IP packet after it leaves the VM.
A visual indication of when interrupts occur vs when Mirage gets around to servicing them.
More stats collection and reporting (e.g. average response time to handle a TCP request, etc).
A more compact log format and more efficient tracing.
But hopefully, these tools will already help people to learn more about how their unikernels behave.
If you're interested in tracing or unikernels, the Mirage mailing list is a good place to discuss things.
]]>Simplifying the solver with functors2014-09-17T08:55:11+00:00https://roscidus.com/blog/blog/2014/09/17/simplifying-the-solver-with-functorsAfter converting 0install to OCaml, I've been looking at using more of OCaml's features to further clean up the APIs.
In this post, I describe how using OCaml functors has made 0install's dependency solver easier to understand and more flexible.
To run a program you need to pick a version of it to use, as well as compatible versions of all its dependencies.
For example, if you wanted 0install to select a suitable set of components to run SAM, you could do it like this:
Here, the solver selected SAM version 0.16, along with its dependencies. GraphViz 2.38.0 and OpenJDK-JRE 7.65 are already installed from my distribution repository, while SWT 3.6.1 and IRIS 0.6.0 need to be downloaded (e.g. using 0install download).
This post is about the code that decides which versions to use, and my attempts to make it easier to understand using OCaml functors and abstraction.
For a gentle introduction to functors, see Real World OCaml: Chapter 9. Functors.
How dependency solvers work
( This section isn't about functors, but it's quite interesting background. You can skip it if you prefer. )
Let's say I want to run foo, a graphical Java application.
There are three versions available:
foo1 (stable)
requires Java 6..!7 (at least version 6, but before version 7)
foo2 (stable)
requires Java 6.. (at least version 6)
requires SWT
foo3 (testing)
requires Java 7..
requires SWT
Let's imagine we have some candidates for Java and SWT too:
My computer can run 32- and 64-bit binaries, so we need to consider both.
We start by generating a set of boolean constraints defining the necessary and sufficient conditions for a set of valid selections.
Each candidate becomes one variable, with true meaning it will be used and false that it won't (following the approach in OPIUM).
For example, we don't want to select more than one version of each component, so the following must all be true:
We must select some version of foo itself, since that's our goal:
1
foo1orfoo2orfoo3
If we select foo1, we must select one of the Java 6 candidates.
Another way to say this is that we must either not select foo1 or, if we do, we must select a compatible Java version:
Once we have all the equations, we throw them at a standard SAT solver to get a set of valid versions.
0install's SAT solver is based on the MiniSat algorithm.
The basic algorithm, DPLL, works like this:
The SAT solver simplifies the problem by looking for clauses with only a single variable.
If it finds any, it knows the value of that variable and can simplify the other clauses.
When no further simplification is possible, it asks its caller to pick a variable to try.
Here, we might try foo2=true, for example.
It then goes back to step 1 to simplify again and so on, until it has either a solution or a conflict.
If a variable assignment leads to a conflict, then we go back and try it the other way (e.g. foo2=false).
In the above example, the process would be:
No initial simplification is possible.
Try foo2=true.
This immediately leads to foo1=false and foo3=false.
Now we try java8_64bit=true.
This immediately removes the other versions of Java from consideration.
It also immediately leads to x64=true, which eliminates all the 32-bit binaries.
It also eliminates all versions of SWT.
foo2 depends on SWT, so eliminating all versions leads to foo2=false, which is a conflict because we already set it to true.
MiniSat, unlike basic DPLL, doesn't just backtrack when it gets a conflict.
It also works backwards from the conflicting clause to find a small set of variables that are sufficient to cause the conflict.
In this case, we find that foo2 and java8_64bit implies conflict.
To avoid the conflict, we must make sure that at least one of these is false, and we can do this by adding a new clause:
1
not(foo2)ornot(java8_64bit)
In this example, this has the same effect as simple backtracking, but if we'd chosen other variables between these two then learning the general rule could save us from exploring many other dead-ends.
We now try with java7_64bit=true and then swt36_64bit=true, which leads to a solution.
Optimising the result
The above process will always find some valid solution if one exists, but we generally want an "optimal" solution (e.g. preferring newer versions).
There are several ways to do this.
In his talk at OCaml 2014, Using Preferences to Tame your Package Manager, Roberto Di Cosmo explained how their tools allow you to specify a function to be optimised (e.g. -count(removed),-count(changed) to minimise the number of packages to be removed or changed).
When you have a global set of package versions (as in OPAM, Debian, etc) this is very useful, because the package manager needs to find solution that balances the needs of all installed programs.
0install has an interesting advantage here.
We can install multiple versions of libraries in parallel, and we don't allow one program to influence another program's choices.
If we run another SWT application, bar, we'll probably pick the same SWT version (bar will probably also prefer the latest stable 64-bit version) and so foo and bar will share the copy.
But if we run a non-SWT Java application, we are free to pick a better version of Java (e.g. Java 8) just for that program.
This means that we don't need to find a compromise solution for multiple programs.
When running foo, the version of foo itself is far more important than the versions of the libraries it uses.
We therefore define the "optimal" solution as the one optimising first the version of the main program, then the version of its first dependency and so on.
This means that:
The behaviour is predictable and easy to explain.
The behaviour is stable (small changes to libraries deep in the tree have little effect).
Programs can rank their dependencies by importance, because earlier dependencies are optimised first.
If foo2 is the best version for our policy (e.g. "prefer latest stable version") then every solution with foo2=true is better than every solution without.
If we direct the solver to try foo2=true and get a solution, there's no point considering the foo2=false cases.
This means that the first solution we find will always be optimal, which is very fast!
The current solver code
The existing code is made up of several components:
Arrows indicate "uses" relationship.
SAT Solver
Implements the SAT solver itself (if you want to use this code in your own projects, Simon Cruanes has
made a standalone version at https://github.com/c-cube/sat, which has some additional features and
optimisations).
Solver
Fetches the candidate versions for each interface URI (equivalent to the package name in other systems) and builds up the SAT problem, then uses the SAT solver to solve it.
It directs the SAT solver in the direction of the optimal solution when there is a choice, as explained above.
Impl provider
Takes an interface URI and provides the candidates ("implementations") to the solver.
The candidates can come from multiple XML "feed" files: the one at the given URI itself, plus any extra feeds that one imports, plus any additional local or remote feeds the user has added (e.g. a version in a local Git checkout or which has been built from source locally).
The impl provider also filters out obviously impossible choices (e.g. Windows binaries if we're on Linux, uncached versions in off-line mode, etc) and then ranks the remaining candidates according to the local policy (e.g. preferring stable versions, higher version numbers, etc).
Feed provider
Simply loads the feed XML from the disk cache or local file, if available.
It does not access the network.
Driver
Uses the solver to get an initial solution.
Then it asks the feed provider which feeds the solver tried to access and starts downloading them.
As new feeds arrive, it runs the solver again, possibly starting more downloads.
Managing these downloads is quite interesting; I used it as the example in Asynchronous Python vs OCaml.
This is reasonably well split up already, thanks to occasional refactoring efforts, but we can always do better.
The subject of today's refactoring is the solver module itself.
Here's the problem:
solver.mli
12345678910111213141516171819202122
classtyperesult=objectmethodget_selections:Selections.t(* The remaining methods are used to provide diagnostics *)methodget_selected:source:bool->General.iface_uri->Impl.generic_implementationoptionmethodimpl_provider:Impl_provider.impl_providermethodimplementations:((General.iface_uri*bool)*(diagnostics*Impl.generic_implementation)option)listmethodrequirements:requirementsend(** Find a set of implementations which satisfy these * requirements. * @param closest_match adds a lowest-ranked (but valid) * implementation to every interface, so we can always * select something. Useful for diagnostics. *)valdo_solve:Impl_provider.impl_provider->requirements->closest_match:bool->resultoption
What does do_solve actually do?
It gets candidates (of type Impl.generic_implementation) from Impl_provider and produces a Selections.t.
Impl.generic_implementation is a complex type including, among other things, the raw XML <implementation> element from the feed XML.
A Selections.t is a set of <selection> XML elements.
In other words: do_solve takes some arbitrary XML and produces some other XML.
It's very hard to tell from the solver.mli interface file what features of the input data it uses in the solve, and which it simply passes through.
Now imagine that instead of working on these messy concrete types, the solver instead used only a module with this type:
We could then see exactly what information the solver needed to do its job.
For example, we could see just from the type signature that the solver doesn't understand version numbers, but just uses meets_restriction to check whether an abstract implementation (candidate) meets an abstract restriction.
Using OCaml's functors we can do just this, splitting out the core (non-XML) parts of the solver into a Solver_core module with a signature something like:
This says that, given any concrete module that matches the SOLVER_INPUT type, the Make functor will return a module with a suitable do_solve function.
In particular, the compiler will check that the solver core makes no further assumptions about the types.
If it assumes that a Model.impl_provider is any particular concrete type then solver_core.ml will fail to compile, for example.
Discovering the interface
The above sounds nice in theory, but how easy is it to change the existing code to the new design?
I don't even know what SOLVER_INPUT will actually look like - surely more complex than the example above!
Actually, it turned out to be quite easy.
You can start with just a few concrete types, e.g.
This doesn't constrain Solver_core at all, since it's allowed to know the real types and use them as before.
This step just lets us make the Solver_core.Make functor and have things still compile and work.
Next, I made impl_provider abstract (removing the = Impl_provider.impl_provider), letting the compiler find all the places where the code assumed the concrete type.
First, it was getting the candidate implementations for an interface from it.
The impl_provider was actually returning several things: the valid candidates, the rejects, and an optional conflicting interface (used when one interface replaces another).
The solver doesn't use the rejects, which are only needed for the diagnostics system, so we can simplify that interface here.
Secondly, not all dependencies need to be considered (e.g. a Windows-only dependency when we're on Linux).
Since the impl_provider already knows the platform in order to filter out incompatible binaries, we also use it to filter the dependencies.
Our new module type is:
At this point, I'm not trying to improve the interface, just to find out what it is.
Continuing to make the types abstract in this way is a fairly mechanical process, which led to:
sigs.mli
123456789101112131415161718192021222324252627
moduletypeSOLVER_INPUT=sigtypet(* new name for impl_provider *)typeimpltypecommandtypedependencytyperestrictiontypeiface_info={replacement:iface_urioption;impls:impllist;}valimplementations:t->iface_uri->source:bool->iface_infovalget_command:impl->string->commandoptionvalrequires:impl->dependencylistvalcommand_requires:command->dependencylistvalmachine_group:impl->Arch.machine_groupoptionvalrestrictions:dependency->restrictionlistvalmeets_restriction:impl->restriction->boolvaldep_iface:dependency->iface_urivaldep_required_commands:dependency->stringlistvaldep_essential:dependency->boolvalrestricts_only:dependency->boolvalis_dep_needed:t->dependency->boolvalimpl_self_commands:impl->stringlistvalcommand_self_commands:command->stringlistvalimpl_to_string:impl->stringvalcommand_to_string:command->stringend
The main addition is the command type, which is essentially an optional entry point to an implementation.
For example, if a library can also be used as a program then it may provide a "run" command, perhaps adding a dependency on an option parser library.
Programs often also provide a "test" command for running the unit-tests, etc.
There are also two to_string functions at the end for debugging and diagnostics.
Having elicited this API between the solver and the rest of the system, it was clear that it had a few flaws:
is_dep_needed is pointless. There are only two places where we pass a dependency to the solver (requires and command_requires), so we can just filter the unnecessary dependencies out there and not bother the solver core with them at all.
The abstraction ensures there's no other way for the solver core to get a dependency.
impl_self_commands and command_self_commands worried me.
These are used for the (rare) case that one command in an implementation depends on another command in the same implementation.
This might happen if, for example, the "test" command wants to test the "run" command.
Logically, these are just another kind of dependency; returning them separately means code that follows dependencies might forget them.
Sure enough, there was just such a bug in the code.
When we build the SAT problem we do consider self commands (so we always find a valid result), but when we're optimising the result we ignore them, possibly leading to non-optimal solutions.
I added a unit-test and made requires return both dependencies and self commands together to avoid the same mistake in future.
For a similar reason, I replaced dep_iface, dep_required_commands, restricts_only and dep_essential with a single dep_info function returning a record type.
I added type command_name = private string.
This means that the solver can't confuse command names with other strings and makes the type signature more obvious.
I didn't make it fully abstract, but was a bit lazy and used private, allowing the solver to cast to a string for debug logging and to let it use them as keys in a StringMap.
There is a boolean source attribute in do_solve and implementations.
This is used if the user wants to select source code rather than a binary.
I wanted to support the case of a compiler that is compiled using an older version of itself (though I never completed this work).
In that case, we need to select different versions of the same interface, so the solver actually picks a unique implementation for each (interface, source) pair.
I tried giving these pairs a new abstract type - "role" - and that simplified things nicely.
It turned out that every place where we passed only an interface (e.g. dep_iface), we eventually ended up doing (iface, false) to get back to a role, so I was able to replace these with roles too.
This is quite significant.
Currently, the main interface can be source or binary but dependencies are always binary.
For example, source code may depend on a compiler, build tool, etc.
People have wondered in the past how easy it would be to support dependencies on source code too - it turns out this now requires no changes to the solver, just an extra attribute in the XML format!
With the role type now abstract, I removed Model.t (the impl_provider) and moved it inside the role type.
This simplifies the API and allows us to use different providers for different roles (imagine solving for components to cross-compile a program; some dependencies like make should be for the build platform, while others are for the target).
Note: Role is a submodule to make it easy to use it as the key in a map.
Hopefully you find it much easier to understand what the solver does (and doesn't) do from this type.
The Solver_core code no longer depends on the rest of 0install and can be understood on its own.
The remaining code in Solver defines the implementation of a SOLVER_INPUT module and applies the functor, like this:
12345678910111213141516171819202122232425
moduleCoreModel=structtypeimpl=Impl.generic_implementationtypecommand=Impl.commandtyperestriction=Impl.restrictiontypecommand_name=stringtypedependency=Role.t*Impl.dependency...letget_commandimplname=StringMap.findnameImpl.(impl.props.commands)letdep_info(role,dep)={dep_role={scope=role.scope;iface=dep.Impl.dep_iface;(* note: only dependencies on binaries supported for now. *)source=false;};dep_importance=dep.Impl.dep_importance;dep_required_commands=dep.Impl.dep_required_commands;}...endmoduleCore=Solver_core.Make(CoreModel)...
The CoreModel implementation of SOLVER_INPUT simply maps the abstract types and functions to use the real types.
The limitation that dependencies are always binary is easier to see here, and it's fairly obvious how to fix it.
Note that we don't define the module as module CoreModel : SOLVER_INPUT = ....
The rest of the code in Solver still needs to see the concrete types; only Solver_core is restricted to see it just as a SOLVER_INPUT.
Comparison with Java
Using functors for this seemed pretty easy, and I started wondering how I'd solve this problem in other languages.
Python simply can't do this kind of thing, of course - there you have to read all the code to understand what it does.
In Java, we might declare some abstract interfaces, though:
There's a problem, though.
We can create a ConcreteRole and pass that to Solver.do_solve, but we'll get back a map from abstract roles to abstract impls.
We need to get concrete types out to do anything useful with the result.
A Java programmer would probably cast the results back to the concrete types, but there's a problem with this (beyond the obvious fact that it's not statically type checked):
If we accept dynamic casting as a legitimate technique (OCaml doesn't support it), there's nothing to stop the abstract solver core from doing it too.
We're back to reading all the code to find out what information it really uses.
There are other places where dynamic casts are needed too, such as in meets_restriction (which needs a concrete implementation, not an abstract one).
I did try using generics, but I didn't manage to get it to compile, and I stopped when I got to:
I think it's fair to say that if this ever did compile, it certainly wouldn't have made the code easier to read.
Diagnostics
The Diagnostics module takes a failed solver result (produced with do_solve ~closest_match:true) that is close to what we think the user wanted but with some components left blank, and tries to explain to the user why none of the available candidates was suitable
(see the Trouble-shooting guide for some examples and pictures).
I made a SOLVER_RESULT module type which extended SOLVER_INPUT with the final selections and diagnostic information:
sigs.mli
12345678910111213141516171819202122
moduletypeSOLVER_RESULT=sigincludeSOLVER_INPUTtypetvalrequirements:t->requirementsvaluser_restrictions:Role.t->restrictionoptionvalget_selected:t->Role.t->imploptionvalselected_commands:t->Role.t->command_namelistvalexplain:t->Role.t->stringtyperejectionvalrejects:Role.t->(impl*rejection)listvaldescribe_problem:impl->rejection->stringtypeversionvalversion:impl->versionvalformat_version:version->stringvalid_of_impl:impl->stringvalformat_machine:impl->stringvalstring_of_restriction:restriction->stringvaldummy_impl:impl(** Placeholder for missing impls *)end
Note: the explain function here is for the diagnostics-of-last-resort; the diagnostics system uses it on cases it can't explain itself, which generally indicates a bug somewhere.
Then I made a Diagnostics.Make functor as with Solver_core.
This means that the diagnostics now sees the same information as the solver, with the above additions.
For example, it sees the same dependencies as the solver did (e.g. we can't forget to filter them out with is_dep_needed).
Like the solver, the diagnostics assumed that a dependency was always a binary dependency and used (iface, false) to get the role.
Since the role is now abstract, it can't do this and should cope with source dependencies automatically.
The new API prompted me to consider self-command dependencies again, so the diagnostics code is now able to explain correctly problems caused by missing self-commands (previously, I forgot to handle this case).
Selections
Sometimes we use the results of the solver directly.
In other cases, we save them to disk as an XML selections document first.
These XML documents are handled by the Selections module, which had its own API.
For consistency, I decided to share type names and methods as much as possible.
I split out the core of SOLVER_INPUT into another module type:
Actually, there is some overlap with SOLVER_RESULT too, so I created a SELECTIONS type as well:
Now the relationship becomes clear.
SOLVER_INPUT extends the core model with ways to get the possible candidates and restrictions on their use.
SELECTIONS extends the core with ways to find out which implementations were selected.
SOLVER_RESULT combines the above two, providing extra information for diagnostics by relating the selections back to the candidates (information that isn't available when loading saved selections).
I had a bit of trouble here.
I wanted to include CORE_MODEL in SELECTIONS, but doing that caused an error when I tried to bring them together in SOLVER_RESULT,
because of the duplicate Role submodule.
So instead I just define the types I need and let the user of the signature link them up.
Update: I've since discovered that you can just do with module Role := Role to solve this.
Correct use of the with keyword seems the key to a happy life with OCaml functors.
When defining the RoleMap submodule in SELECTIONS I use it to let users know the keys of a RoleMap are the same type as SELECTIONS.role (otherwise it will be abstract and you can't assume anything about it).
In SOLVER_RESULT, I use it to link the types in SELECTIONS with the types in SOLVER_INPUT.
Notice the use of = vs :=.
= says that two types are the same.
:= additionally removes the type from the module signature.
We use := for impl because we already have a type with that name from SOLVER_INPUT and we can't have two.
However, we use = for role because that doesn't exist in CORE_MODEL and we'd like SOLVER_RESULT to include everything in SELECTIONS.
Finally, I included the new SELECTIONS signature in the interface file for the Selections module:
With this change, anything that uses SELECTIONS can work with both loaded selections and with the solver output, even though they have different implementations.
For example, the Tree module generates a tree (for display) from a selections dependency graph (pruning loops and diamonds).
It's now a functor, which can be used with either.
For example, 0install show selections.xml applies it to the Selections module:
The same code is used in the GUI to render the tree view, but now with Make(Solver.Model).
As before, it's important to preserve the types - the GUI needs to know that each node in the tree is a Solver.Model.Role.t so that it can show information about the available candidates, for example.
Summary
An important function of a package manager is finding a set of package versions that are compatible.
An efficient way to do this is to express the necessary and sufficient constraints as a set of boolean equations and then use a SAT solver to find a solution.
While finding a valid solution is easy, finding the optimal one can be harder.
Because 0install is able to install libraries in parallel and can choose to use different versions for different applications, it only needs to consider one application at a time.
As well as being faster, this makes it possible to use a simple definition of optimality that is easy to compute.
0install's existing solver code has already been broken down into modular components: downloading metadata, collecting candidates, rejecting invalid candidates and ranking the rest, building the SAT problem and solving it.
However, the code that builds the SAT problem and optimises the solution was tightly coupled to the concrete representation, making it harder to see what it was doing and harder to extend it with new features.
Its type signature essentially just said that it takes XML as input and returns XML as output.
OCaml functors are functions over modules.
They allow a module to declare the interface it expects from its dependencies in an abstract way, providing just the information the module requires and nothing else.
The module can then be compiled against this abstract interface, ensuring that it makes no assumptions about the actual types.
Later, the functor can be applied to the concrete representation to get a module that uses the concrete types.
Turning the existing solver code into a functor turned out to be a simple iterative process that discovered the existing implicit API between the solver and the rest of the code.
Once this abstract API had been found, many possible improvements became obvious.
The new solver core is both simpler than the original and can be understood on its own without looking at the rest of the code.
It is also more flexible: we could now add support for source dependencies, cross-compilation, etc, without changing the core of the solver.
The challenge now is only how to express these things in the XML format.
In a language without functors, such as Java, we could still define the solver to work over abstract interfaces, but the results returned would also be abstract, which is not useful.
Trying to achieve the same effect as functors using generics appears very difficult and the resulting code would likely be hard to read.
Splitting up the abstract interface into multiple module types allowed parts of the interface to be shared with the separate selections-handling module.
This in turn allowed another module - for turning selections into trees - to become a functor that could also work directly on the solver results.
Finally, it made the relationship between the solver results and the selections type clear - solver results are selections plus diagnostics information.
]]>Optimising the unikernel2014-08-15T11:05:27+00:00https://roscidus.com/blog/blog/2014/08/15/optimising-the-unikernelAfter creating my REST queuing service as a Mirage unikernel, I reported that it could serve the data at 2.46 MB/s from my ARM CubieTruck dev board.
That's fast enough for my use (it's faster than my Internet connection), but I was curious why it was slower than the Linux guest, which serves files with nc at 20 MB/s.
To avoid confusing things by testing the disk and the network at the same time, I made a simpler test case that waits for a TCP connection
and transmits a pre-allocated buffer multiple times:
unikernel.ml
123456789101112131415161718192021222324
moduleMain(C:V1_LWT.CONSOLE)(S:V1_LWT.STACKV4)=structletbuffer=Io_page.pages16|>List.mapIo_page.to_cstructletstartcs=S.listen_tcpv4s~port:80(funflow->letwarmups=10inletiterations=100inletbytes=Cstruct.lenvbuffer*iterationsinletrecloop=function|0->return()|i->lwt()=S.TCPV4.writevflowbufferinloop(i-1)inloopwarmups>>=fun()->lwttime=Profile.time(fun()->loopiterations)inS.TCPV4.closeflow>>=fun()->C.log_sc(Printf.sprintf"Wrote %d bytes in %.3f seconds (%.2f KB/s)"bytestime(float_of_intbytes/.time/.1024.)));S.listensend
Profile.time just runs the function and returns how long it took in seconds.
I do a few warm-up iterations at the start because TCP starts slowly and we don't want to benchmark that.
Compiler optimisations
While looking at the assembler output during some earlier debugging, I'd noticed that gcc was generating very poor code. For example:
gcc is using registers very inefficiently here.
For example, it stores r1 to [fp, #-44] and then a few lines later loads from there into r0, when it could just have moved it directly.
The last two lines show it saving r0 to the stack and then immediately loading it back again into the same register!
The fix here turned out to be simple.
Mini-OS by default compiles in debug mode with no optimisations.
Compiling with debug=n fixes this, and I updated mirage-xen-minios to do this.
Optimisations
TCP download speed
none
6.92 MB/s
-O3
11.93 MB/s
Even though Mirage is almost all OCaml, it does use Mini-OS's C functions for various low-level operations and these optimisations make a big difference!
Profiling support
The OCaml compiler provides a profiling option, which works the same way as gcc's -pg option for C code.
To enable it, you add true: profile to your _tags file and rebuild.
I decided to see what would happen if I enabled this for my Xen unikernel:
_build/main.native.o: In function `caml_program':
:(.text+0x2): undefined reference to `__gnu_mcount_nc'
Profiling works by inserting a call to __gnu_mcount_nc at the start of every function.
It looks like this:
The __gnu_mcount_nc function gets the address of the callee function (caml_program in this example) in the link register (lr/r14) and the address of its caller on the stack (pushed by the code fragment above).
Normally, the profiler would use this information to build up a static call graph (saying which functions call which other functions).
Using a regular timer interrupt to sample the program counter it can estimate how much time was spent in each function,
and using the call graph it can show cumulative totals (time spent in each function plus time spent in its children).
I decided to start with something a bit simpler.
I wrote some ARM code for __gnu_mcount_nc that simply writes the caller, callee and current time to a trace buffer (when the buffer is full, it stops tracing).
Ideally, I'd like to get notified each time we leave a function too.
gcc can do that for C code with its -finstrument-functions option, but I didn't see an option for that in OCaml.
Instead, I assume that every function runs until I see a call whose caller is not its parent.
This works surprisingly well, though it does mean that if a function seems to take a long time you need to check its parents too,
and it might get confused for recursive calls.
Also, for tail calls, we see the parent as the function we will return to rather than the function that actually called us.
At the end, I dump out the trace buffer to the console with some OCaml code.
Back on my laptop, I wrote some code to parse this output and look up each address in the ELF image to get the function name for each address.
(This code isn't public yet as it needs a lot of cleaning up.)
One thing I quickly discovered: compiling just the unikernel with profiling isn't sufficient.
As soon as you call a non-profiled function it can no longer construct the call graph and the results are useless.
I manually recompiled every C and OCaml library I was using with profiling, which was quite tedious.
Update: Thomas Gazagnaire has added an OPAM profiling switch which should make this much easier in future.
Initially, the trace buffer filled up almost instantly with calls to stub_evtchn_test_and_clear.
It seems that we call this once for each of the 4096 channels every time we look for work.
To avoid clutter, I reduced the number of event channels to 10 (this had no noticeable effect on performance).
I also tried removing the memset which zeroes out newly allocated IO pages.
This also made no difference.
I measured the overhead added by the tracing, both when compiled in but inactive and when actively writing to the trace buffer:
So, not too bad.
Profiling the console
The TCP code's trace was quite complicated, so I decided to start by profiling the much simpler console device,
which I'd noticed was surprisingly slow at dumping the trace results.
A Xen virtual console is a pair of ring buffers (one for input from the keyboard, one for output to the screen) in a shared memory page, defined like this:
We're only interested in the "out" side here.
The producer (i.e. our unikernel) writes the data to the buffer and advances the out_prod counter.
The consumer (xenconsoled, running in Dom0) reads the data and advances out_cons.
If the consumer catches up with the producer it sleeps until the producer notifies it there is more data.
If the producer catches up with the consumer (the buffer is full) it sleeps until the consumer notifies it there is space available again.
Here's my console test-case - writing a string to the console in a loop:
1234567891011121314151617181920
moduleMain(C:V1_LWT.CONSOLE)=structletstartc=letlen=6inletmsg=String.make(len-1)'X'inletiterations=10000inletbytes=len*iterationsinletrecloop=function|0->return()|i->C.log_scmsg>>=fun()->loop(i-1)inloop1000>>=fun()->(* Warm up *)lett0=Clock.time()inlwt()=loopiterationsinlettime=Clock.time()-.t0inC.log_sc(Printf.sprintf"Wrote %d bytes in %.3f seconds (%.2f KB/s)"bytestime(float_of_intbytes/.time/.1024.))>>=fun()->OS.Time.sleep2.0end
I got around 45 KB/s. The trace output looked like this:
Start
Function
Duration
118684
- - camlUnikernel__loop_1270
219
118730
- - > camlConsole__write_all_low_1123
158
118737
- - > - camlRing__repeat_1279
89
118739
- - > - - camlRing__write_1270
87
118830
- - > - camlEventchn__fun_1138
58
118831
- - > - - stub_evtchn_notify
57
118907
- - camlUnikernel__loop_1270
211
118944
- - > camlConsole__write_all_low_1123
168
118951
- - > - camlRing__repeat_1279
100
118953
- - > - - camlRing__write_1270
98
119054
- - > - camlEventchn__fun_1138
58
119055
- - > - - stub_evtchn_notify
57
The start time and duration are measured in counter clock ticks, and the counter is running at 24 MHz.
The -->-->--> indicates the level of nesting (I vary the character to make it easier to scan vertically with the eye).
The output shows two iterations of the loop taken from the middle of the sample.
To make the output more readable, my analysis script prunes the tree at calls that took less than 50 ticks, and removes calls to the Lwt library (while still showing the functions they called as a result).
The durations include the times for their children (including pruned children).
You can see that on each iteration we call Console.write_all_low, which writes the string to the shared memory ring and notifies the console daemon in Dom0.
Each iteration is taking roughly 200 ticks, which is about 8 us per iteration.
So we'd expect the speed to be around 6 bytes / 8 us, which is about 700 KB/s.
Looking at the cumulative time spent in each function, the top entries are:
Function
Ticks (at 24 MHz)
caml_c_call
9002738
caml_block_domain
9001576
block_domain
9001462
camlUnikernel__loop_1270
374418
camlConsole__write_all_low_1123
298735
Note: the trace only includes calls until the trace buffer was full, so these aren't the total times for the whole run.
But we can immediately see that we spent most of the time in block_domain, which is what Mirage calls when it has nothing to do and is waiting for an external event.
Here's a graph showing how many iterations of the test loop we had started over time:
So, we wrote 679 messages very quickly, then waited a long time, then wrote 1027 more, then waited again, etc.
I thought there might be a bug in block_domain causing it to miss a wake-up event, so I limited the time it would spend blocking.
It didn't make any difference; it would keep waking up, seeing that it had nothing to do, and going back to sleep again.
In case the problem was with Mirage's implementation of the shared rings or console device,
I tried writing the same test directly in C in Mini-OS's test.c and got the same result (I had to modify it slightly because by default Mini-OS's console_print discards data when the buffer is full instead of waiting).
Finally, I tried it from a Linux guest and got 25 KB/s (interestingly, Linux uses 100% CPU while doing this).
The times were highly variable (each point on this plot is from writing the message 10,000 times and calculating the average):
After some investigation, it turned out that Xen was deliberately limiting the rate:
xen/tools/console/daemon/io.c
1234
/* How many events are allowed in each time period */#define RATE_LIMIT_ALLOWANCE 30/* Duration of each time period in ms */#define RATE_LIMIT_PERIOD 200
Mystery solved, although I don't know why the rates are so variable.
Mirage wasn't doing anything except running the test case and Linux was booted with init=/bin/bash, so there was nothing else running there either.
Lessons:
Just scrolling through the raw trace can be misleading. It appears that it keeps calling the loop function, but in fact almost all the time was spent in the two very rare block_domain calls. Graphing iterations over time can show these problems effectively.
Compare with the speed on Linux. Sometimes, Xen really is that slow and it's not our fault.
Compile everything for profiling or the results aren't much use.
Profiling UDP
TCP involves ack packets, expanding windows and other complications, so I next looked at the simpler UDP protocol.
Here, we can throw packets out continuously without worrying about the other end.
With a payload size of 1476 bytes (the maximum possible for UDP), I got 17 MB/s.
All packets were successfully received on my laptop.
My Linux guest got 13.4 MB/s with nc -u < /dev/zero, so we're actually faster!
Here's a graph of loop iterations (packets sent) over time (each blue dot is one packet sent):
The gaps indicate places where we were not sending packets.
The garbage collector shows up twice in the trace (both times in Ring.ack_responses oddly).
However, we spend more time in block_domain than doing GC, indicating that we're often waiting for Xen.
Looking at the trace just before it blocks, I see calls to Netif.wait_for_free_tx, which seems reasonable.
Profiling TCP
The TCP header is larger than the UDP one, making it less efficient even in the best case,
and TCP needs to process acks, keep track of window sizes, and handle retransmissions.
Strange, then, that the Linux guest manages 39 MB/s over TCP compared with just 13.4 MB/s for UDP!
(even stranger is that I got 47.2 MB/s for Linux when I tried it for last
month's post; however I am using a different version of Linux in dom0 now)
I capture some packets sent by the Linux guest using tshark running in Dom0.
Loading it into Wireshark on my laptop, I see that all the TCP checksums are wrong, so it
looks like Linux is using TCP checksum offloading.
A domain has no way of knowing how any given packet is going to leave the host (or even if it is) so it can't know ahead of time whether to calculate any checksums: the skb's [socket buffers] are just marked with "checksum needed" as usual and either the egress NIC will do the job or dom0 will do it.
Getting this working on Mirage was a bit tricky.
The TCP layer can avoid adding the checksum only if the network device says it's capable of doing it itself, and packets have to be flagged as needing the checksum.
You can't just flag all packets because the Linux dom0 silently drops non-TCP/UDP packets with it set (e.g. ARP packets).
I hacked something together and got a modest speed improvement.
Here's a graph for the TCP test, where each iteration of the loop is sending one TCP packet (segment):
Note: we send many warm up packets before starting the trace as TCP starts slowly (which looks pretty but isn't relevant here).
Zooming in, the picture is quite interesting (where it had gaps, I searched for a typical function that occurred in the gap and added a symbol for it):
It looks like we start by transmitting packets steadily, until the current window is full.
Then we start buffering the packets instead of sending them, which is very fast.
At some point the TCP system stops accepting more data, which causes the main loop to block, allowing us to process other events.
rx_poll response indicates one iteration of the Netif.rx_poll loop, which seems to be dealing with acks from Xen saying that our packets have been transmitted (and the memory can therefore be recycled).
After a while, the TCP ack packets arrive and we process them, which opens up the transmit window again.
Then we send out the buffered packets, before returning to the main loop.
So, in each cycle we spend about 60% of the time transmitting packets, a quarter dealing with acks from Xen and the rest handling TCP acks from the remote host.
It might be possible to optimise things a bit here by reusing grant references, but I didn't investigate further.
Profiling disk access
My next test case reads a series of sectors sequentially from the disk and then writes them. Reading or writing one sector (4096 bytes) at a time was very slow (2.7 MB/s read, 0.7 MB/s write).
Using larger buffers, so that we transfer more in each operation, helped but even at 64 sectors per op I only got 12.3 MB/s read / 5.12 MB/s write (the device is capable of 20 MB/s read and 10 MB/s write).
Here's a trace where we read using 32-sector buffers (10.9 MB/s):
We spend a lot of time waiting for each block to arrive, although there are some curious ack messages, which we deal with quickly.
What if we have two requests in flight at once?
This gets us 18.27 MB/s:
Strangely, the two blocks arrive close together.
Although it takes us longer to get the first one (I don't know why), we get them more quickly after that.
Having three requests in flight doesn't help though (18.25 MB/s):
Looking at the block driver code, it batches requests into groups of 11. This probably explains why 32 sectors-per-read did well - it's very close to 33.
For writing, the number of requests in flight makes little difference, but writing 8 sectors in each request is by far the best (7 MB/s).
I don't understand why we're not getting the full speed of the card here, since we're spending most of the time blocking.
However, we are pretty close (18r/7w out of a possible 20r/10w), which is good enough for today.
Update: Linux is slow too!
I originally tested with hdparm, which reports about 20 MB/s as expected:
$ hdparm -t /dev/mmcblk0
Timing buffered disk reads: 62 MB in 3.07 seconds = 20.21 MB/sec
But testing with dd, I don't get this speed.
dd's speed seems to depend a lot on the block size. Using 4096 * 11 bytes (which I assume is what dom0 would do in response to a single guest request), I get just 16.9 MB/s:
$ dd iflag=direct if=/dev/vg0/bench of=/dev/null bs=45056 count=1000
1000+0 records in
1000+0 records out
45056000 bytes (45 MB) copied, 2.65911 s, 16.9 MB/s
Block size (pages)
Linux dom0
Linux domU
11
17.0 MB/s
14.5 MB/s
16
18.8 MB/s
16.3 MB/s
32
20.8 MB/s
18.6 MB/s
So perhaps Mirage is doing pretty well already - it's about as fast as the Linux guest.
Xen seems to be the limiting factor here, because it doesn't allow us to make large enough requests.
Profiling the queuing service
Finally, I looked at applying all this new information to my queuing service.
As a baseline, wget reports that I can currently download from it at 4.6 MB/s, with profiling compiled in but disabled:
There's some complicated copying going on because we're using the HTTP Chunked encoding, which writes the size of each chunk of data followed by the data itself, then the next chunk, etc.
Since we know the length at the start, we can use the simpler Fixed encoding.
This increases the speed to 5.2 MB/s.
It's a shame the HTTP API uses strings everywhere: we have to copy the data from the disk buffer to a string on the heap to give it to the HTTP API, which then copies it back into a new buffer to send it to the network card.
If it took a stream of buffers, we could just pass them straight through.
Finally, I added the read-ahead support from the block profiling above, which increased the speed to 6.8 MB/s.
Here's the new graph, showing that we're sending packets much faster (note the change in the Y-scale):
I used a queue length of 5, with 33 sectors per request. I tried increasing it to 10, but that caused more GC work.
Conclusions
Even the unoptimised service is faster than my current (ADSL) Internet connection, so optimising it isn't currently necessary, but it's interesting to look at performance and get a feel for where the bottlenecks are.
Mirage doesn't have any specific profiling support, but the fact that the whole OS is a single executable makes profiling it quite easy.
OCaml's profile option isn't a perfect fit for tracing because it doesn't record when a function finishes, but you can still get useful results from it.
Graphing some metric (e.g. packets sent) over time seemed the most useful way to look at the data.
I'm currently just using libreoffice's chart tool, but I should probably find something more suitable.
It would be great to be able to zoom in easily, show durations (not just events), filter the trace display easily, etc.
I'd also like support for following Lwt threads even when they block.
Recommendations for good visualisation tools welcome!
Writing to the Xen console from Mirage is slow because xenconsoled rate limits us. Mirage still gets better performance than Linux though, and uses far less CPU (looks like Linux is just spinning). My UDP test kernel sent data faster than Linux's nc utility (probably because nc made a poor choice of payload size). Linux does very well on TCP. I don't know why it's so fast. Using Xen's TCP checksum offloading does help a bit though. SD card performance on Mirage is close to what the hardware supports when I choose the right request size and keep two requests in flight at once. It's surprising we don't manage the full speed, though. For networking and disk access, managing Xen's grant refs for the shared memory pages seems to take up a lot of time - maybe there are ways to optimise that.
With a few modifications (TCP checksum offload, HTTP fixed encoding, keeping multiple disk reads in flight and using optimal buffer sizes), I increased the download speed of my test service running on my ARM dev board from 2.46 MB/s to 7.24 MB/s (when compiled without profiling).
I'm sure people more familiar with Mirage will have more suggestions.
]]>My first unikernel2014-07-28T16:21:10+00:00https://roscidus.com/blog/blog/2014/07/28/my-first-unikernelI wanted to make a simple REST service for queuing file uploads, deployable as a virtual machine. The traditional way to do this is to download a Linux cloud image, install the software inside it, and deploy that. Instead I decided to try a unikernel.
Unikernels promise some interesting benefits. The Ubuntu 14.04 amd64-disk1.img cloud image is 243 MB unconfigured, while the unikernel ended up at just 5.2 MB (running the queue service). Ubuntu runs a large amount of C code in security-critical places, while the unikernel is almost entirely type-safe OCaml. And besides, trying new things is fun.
Regular readers will know that a few months ago I began a new job at Cambridge University.
Working for an author of Real World OCaml and leader of OCaml Labs, on a project building pure-OCaml distributed systems, who found me through my blog posts about learning OCaml, I thought they might want me to write some OCaml.
But no.
They've actually had me porting the tiny Mini-OS kernel to ARM, using a mixture of C and assembler, to let the Mirage unikernel run on ARM devices.
Of course, I got curious and wanted to write a Mirage application for myself...
Introduction
Linux, like many popular operating systems, is a multi-user system.
This design dates back to the early days of computing, when a single expensive computer, running a single OS, would be shared between many users.
The goal of the kernel is to protect itself from its users, and to protect the users from each other.
Today, computers are cheap and many people own several.
Even when a physical computer is shared (e.g. in cloud computing), this is typically done by running multiple virtual machines, each serving a single user.
Here, protecting the OS from its (usually single) application is pointless.
Removing the security barrier between the kernel and the application greatly simplifies things;
we can run the whole system (kernel + application) as a single, privileged, executable - a unikernel.
And while we're rewriting everything anyway, we might as well replace C with a modern memory safe language, eliminating whole classes of bugs and security vulnerabilities, allowing decent error reporting, and providing structured data types throughout.
In the past, two things have made writing a completely new OS impractical:
Legacy applications won't run on it.
It probably won't support your hardware.
Virtualisation removes both obstacles:
legacy applications can run in their own legacy VMs, and
drivers are only needed for the virtual devices - e.g.
a single network driver and a single block driver will cover all real network cards and hard drives.
A hello world kernel
The mirage tutorial starts by showing the easy, fully-automated way to build a unikernel.
If you want to get started quickly you may prefer to read that and skip this section, but since one of the advantages of unikernels is their relative simplicity, let's do things the "hard" way first to understand how it works behind the scenes.
Here's the normal "hello world" program in OCaml:
hw.ml
12
let()=print_endline"Hello, world!"
To compile and run as a normal application, we'd do:
$ ocamlopt hw.ml -o hw
$ ./hw
Hello, world!
How can we make a unikernel that does the equivalent?
As it turns out, the above code works unmodified (though the Mirage people might frown at you for doing it this way).
We compile hw.ml to a hw.native.o file and then link with the unikernel libraries instead of the standard C library:
We now have a kernel image, hw.xen, which can be booted as a VM under the Xen hypervisor (as used by Amazon, Rackspace, etc to host VMs). But first, let's look at the libraries we added:
openlibm
This is a standard maths library. It provides functions such as sin, cos, etc.
libminios-xen
This provides the architecture-specific boot code, a printk function for debugging, malloc for allocating memory and some low-level functions for talking to Xen.
libocaml.a
The OCaml runtime (the garbage collector, etc).
libxencaml.a
OCaml bindings for libminios and some boot code.
libgcc.a
Support functions for code that gcc generates (actually, not needed on x86).
To deploy the new unikernel, we create a Xen configuration file for it (here, I'm giving it 16 MB of RAM):
Setting on_crash and on_poweroff to preserve lets us see any output or errors, which would otherwise be missed if the VM exits too quickly.
We can now boot our new VM:
$ xl create -c hw.xl
Xen Minimal OS!
start_info: 000000000009b000(VA)
nr_pages: 0x800
shared_inf: 0x6ee97000(MA)
pt_base: 000000000009e000(VA)
nr_pt_frames: 0x5
mfn_list: 0000000000097000(VA)
mod_start: 0x0(VA)
mod_len: 0
flags: 0x0
cmd_line:
stack: 0000000000055e00-0000000000075e00
Mirage: start_kernel
MM: Init
_text: 0000000000000000(VA)
_etext: 000000000003452d(VA)
_erodata: 000000000003c000(VA)
_edata: 000000000003e4d0(VA)
stack start: 0000000000055e00(VA)
_end: 0000000000096d64(VA)
start_pfn: a6
max_pfn: 800
Mapping memory range 0x400000 - 0x800000
setting 0000000000000000-000000000003c000 readonly
skipped 0000000000001000
MM: Initialise page allocator for a8000(a8000)-800000(800000)
MM: done
Demand map pfns at 801000-2000801000.
Initialising timer interface
Initialising console ... done.
gnttab_table mapped at 0000000000801000.
xencaml: app_main_thread
getenv(OCAMLRUNPARAM) -> null
getenv(CAMLRUNPARAM) -> null
Unsupported function lseek called in Mini-OS kernel
Unsupported function lseek called in Mini-OS kernel
Unsupported function lseek called in Mini-OS kernel
Hello, world!
main returned 0
( Note: I'm testing locally by running Xen under VirtualBox. Not all of Xen's features can be used in this mode, but it works for testing unikernels. I'm also using my Git version of mirage-xen; the official one will display an error after printing the greeting because it expects you to provide a mainloop too. The warnings about lseek are just OCaml trying to find the current file offsets for stdin, stdout and stderr.)
As you can see, the boot process is quite short.
Execution begins at _start.
Using objdump -d hw.xen, you can see that this just sets up the stack pointer register and calls the C function arch_init:
arch_init (in libminios) initialises the traps and FPU and then prints Xen Minimal OS! and information about various addresses.
It then calls start_kernel.
start_kernel (in libxencaml) sets up a few more features (events, interrupts, malloc, time-keeping and grant tables), then calls caml_startup.
caml_startup (in libocaml) initialises the garbage collector and calls caml_program, which is our hw.native.o.
We call print_endline, which libxencaml, as a convenience for debugging, forwards to libminios's console_print.
Using Mirage libraries
The above was a bit of a hack, which ended up just using the C console driver in libminios (one of the few things it provides, as it's needed for printk).
We can instead use the mirage-console-xen OCaml library, like this:
hw.ml
12345678910
openLwtletmain=Console.connect"0">>=function|`Error_->failwith"Failed to connect to console"|`Okdefault_console->Console.log_sdefault_console"Hello, world!"let()=OS.Main.runmain
Mirage uses the usual Lwt library for cooperative threading, which I wrote about at last year in Asynchronous Python vs OCaml - >>= means to wait for the result, allowing other code to run. Everything in Mirage is non-blocking, even looking up the console. OS.Main.run runs the main event loop.
Since we're using libraries, let's switch to ocamlbuild and give the dependencies in the _tags file, as usual for OCaml projects:
In the same way, we can use other libraries to access raw block devices (mirage-block-xen), timers (mirage-clock-xen) and network interfaces (mirage-net-xen).
Other (non-Xen-specific) OCaml libraries can then be used on top of these low-level drivers.
For example, fat-filesystem can provide a filesystem on a block device, while tcpip provides an OCaml TCP/IP stack on a network interface.
The mirage-unix libraries
You may have noticed that the Xen driver libraries we used above ended in -xen.
In fact, each of these is just an implementation of some generic interface provided by Mirage.
For example, mirage/types defines the abstract CONSOLE interface as:
moduletypeCONSOLE=sig(** Text console input/output operations. *)typeerror=[|`Invalid_consoleofstring](** The type representing possible errors when attaching a console. *)includeDEVICEwithtypeerror:=errorvalwrite:t->string->int->int->int(** [write t buf off len] writes up to [len] chars of [String.sub buf off len] to the console [t] and returns the number of bytes written. Raises {!Invalid_argument} if [len > buf - off]. *)valwrite_all:t->string->int->int->unitio(** [write_all t buf off len] is a thread that writes [String.sub buf off len] to the console [t] and returns when done. Raises {!Invalid_argument} if [len > buf - off]. *)vallog:t->string->unit(** [log str] writes as much characters of [str] that can be written in one write operation to the console [t], then writes "\r\n" to it. *)vallog_s:t->string->unitio(** [log_s str] is a thread that writes [str ^ "\r\n"] in the console [t]. *)end
By linking against the -unix versions of libraries rather than the -xen ones, we can compile our code as an ordinary Unix program and run it directly.
This makes testing and debugging very easy.
To make sure our code is generic enough to do this, we can wrap it in a functor that takes any console module as an input:
The code that provides a Xen or Unix console and calls this goes in main.ml:
main.ml
1234567891011
openLwtletconsole=Console.connect"0">>=function|`Error_->failwith"Failed to connect to console"|`Okc->returncmoduleU=Unikernel.Main(Console)let()=OS.Main.run(console>>=U.start)
The mirage tool
With the platform-specific code isolated in main.ml, we can now use the mirage command-line tool to generate it automatically for the target platform.
mirage takes a config.ml configuration file and generates Makefile and main.ml based on the current platform and the arguments passed.
$ mirage configure --unix
$ make
$ ./mir-hw
Hello, world!
I won't describe this in detail because at this point we've reached the start of the official tutorial, and you can read that instead.
Test case
Because 0install is decentralised, it doesn't need a single centrally-managed repository (or several incompatible repositories, each trying to package every program, as is common with Linux distributions).
In 0install, it's possible for every developer to run their own repository, containing just their software, with cross-repository dependencies handled automatically.
But just because it's possible doesn't mean we have to go to that extreme: having medium sized repositories each managed by a team of people can be very convenient, especially where package maintainers come and go.
The general pattern for a group repository is to have a public server that accepts new package uploads from developers, and a private (firewalled) server with the repository's GPG key, which downloads from it:
Debian uses an anonymous FTP server for its incoming queue, polling it with a cron job.
This turns out to be surprisingly complicated.
You need to handle incomplete uploads (not processing them until they're done, or deleting them eventually if they never complete), allow contributors to overwrite or delete their own partial uploads (Debian allows you to upload a GPG-signed command file, which provides some control), etc, as well as keep the service fully patched.
Also, the cron system can be annoying: if the package contains a mistake then it will be several minutes before it discovers this and emails the packager.
Perhaps there are some decent systems out there to handle all this, but it seemed like a good opportunity to try making a unikernel.
A particularly nice feature of this test-case is that it doesn't matter too much if it fails:
the repository itself will check the developer's signature on the files, so an attacker can't compromise the repository by breaking into the queue; everything in the queue is intended to become public, so we need not worry much about confidentiality; lost uploads can be easily resubmitted; and if it goes down for a bit, it just means that new software can't be added to the repository.
So, there's nothing critical about this service, which is reassuring.
Storage
The merge-queues library builds a queue abstraction on top of
Irmin, a Git-inspired storage system for Mirage.
But my needs are simple, and I wanted to test the more primitive libraries first, so I decided to build my queue directly on a plain filesystem.
This was the first interface I came up with:
moduletypeFS=V1_LWT.FSwithtypepage_aligned_buffer=Cstruct.tandtypeblock_device_error=Fat.Fs.block_error(** An upload. * To avoid loading complete uploads into RAM, we stream them * between the network and the disk. *)typeitem={size:int64;data:stringLwt_stream.t;}typeadd_error=[`Wrong_sizeofint64|`Unknownofexn]moduleMake:functor(F:FS)->sig(** An upload queue. *)typet(** Create a new queue, backed by a filesystem. *)valcreate:F.t->tLwt.tmoduleUpload:sig(** Add an upload to the queue. * The upload is added only once the end of the stream is * reached, and only if the total size matches the size * in the record. * To cancel an add, just terminate the stream. *)valadd:t->item->[`Okofunit|`Errorofadd_error]Lwt.tendmoduleDownload:sig(** Interface for the repository software to fetch items * from the queue. Only one client may use this interface * at a time, or things will go wrong. *)(** Return a fresh stream for the item at the head of the * queue, without removing it. After downloading it * successfully, the client should call [delete]. If the * queue is empty, this blocks until an item is available. *)valpeek:t->itemLwt.t(** Delete the item previously retrieved by [peek]. * If the previous item has already been deleted, this does * nothing, even if there are more items in the queue. *)valdelete:t->unitLwt.tendend
Our unikernel.ml will use this to make a queue, backed by a filesystem.
Uploaders' HTTP POSTs will be routed to Upload.add, while the repository's GET and DELETE invocations go to the Download submodule.
delete is a separate operation because we want the repository to confirm that it got the item successfully before we delete it, in case of network errors.
Ideally, we might require that the DELETE comes over the same HTTP connection as the GET just in case we accidentally run two instances of the repository software, but that's unlikely and it's convenient to test using separate curl invocations.
We're using another functor here, Upload_queue.Make, so that our queue will work over any filesystem.
In theory, we can configure our unikernel with a FAT filesystem on a block device when running under Xen,
while using a regular directory when running under Linux (e.g. for testing).
But it doesn't work.
You can see at the top that I had to restrict Mirage's abstract FS type in two ways:
The read and write functions in FS pass the data using the abstract page_aligned_buffer type.
Since we need to do something with the data, this isn't good enough.
I therefore declare that this must be a Cstruct.t (basically, an array of bytes).
This is actually OK; mirage-fs-unix also uses this type.
One of the possible error codes from FS is the abstract type FS.block_device_error, and I can't
see any way to turn one of these into a string using the FS interface.
I therefore require a filesystem implementation that defines it to be Fat.Fs.block_error.
Obviously, this means we now only support the FAT filesystem.
This doesn't prevent us from running as a normal process, because we can ask for a Unix "block" device (actually, just a plain disk.img file) and pass that to the Fat module, but it would be nice to have the option of using a real directory.
For the curious, this initial implementation is in upload_queue.ml.
Internally, the module creates an in-memory queue to keep track of successful uploads.
Uploads are streamed to the disk and
when an upload completes with the declared size, the filename is added to the queue.
If the upload ends with the wrong size (probably because the connection was lost), the file is deleted.
But what if our VM gets rebooted?
We need to scan the file system at start up and work out which uploads are complete and which should be deleted.
My first thought was to name the files NUMBER.part during the upload and rename on success.
However, the FS interface currently lacks a rename method.
Instead, I write an N byte to the start of each file and set it to Y on success.
That works, but renaming would be nicer!
For downloading, the peek function returns the item at the head of the queue.
If the queue is empty, it waits until something arrives.
The repository just makes a GET request - if something is available then it returns immediately,
otherwise the connection stays open until some data is ready, allowing the repository to respond immediately to new uploads.
Unit-testing the storage system
Because our unikernel can run as a process, testing is easy even if you don't have a local Xen deployment.
A set of unit-tests test the upload queue module just as for any other program, and the service can be run as a normal process, listening on a normal TCP socket.
A slight annoyance here is that the generated Makefile doesn't include any rules to build the tests so you have to add them manually, and
if you regenerate the Makefile then it loses the new rule.
As you might expect from such a new system, testing uncovered several problems. The first (minor) problem is that when the disk becomes full, the unhelpful error reported by the filesystem is Failure("Unknown error: Failure(\"fault\")").
( I asked about this on the mailing list - Error handling in Mirage - and there seems to be agreement that error handling should change. )
A more serious problem was that deleting files corrupted the FAT directory index.
I downloaded the FAT library and added a unit-test for delete, which made it easy to track the problem down (despite my lack of knowledge of FAT).
Here's the code for marking a directory entry as deleted in the FAT library:
It's supposed to take an entry, unmarshal it into an OCaml structure, set the deleted flag, and marshal the result into a new delta structure.
These deltas are returned and applied to the device.
The bug is a simple typo: Lfn (long filename) entries update correctly, but for old Dos ones it writes the new block to the input, not to delta.
The fix was simple enough (I also refactored it slightly to encourage the correct behaviour in future):
This demonstrates both the good and the bad of Mirage: the bug was easy to find and fix, using regular debugging tools.
I'm sure fixing a filesystem corruption bug in the Linux kernel would have been vastly more difficult.
On the other hard, Linux is rather well tested, whereas I appear to be the first person ever to try deleting a file in Mirage!
The HTTP server
This turned out to be quite simple. Here's the unikernel's start function:
Here, our functor is extended to take a filesystem (using the restricted type required by our Upload_queue, as noted above) and an HTTP server module as arguments.
The HTTP server calls our callback each time it receives a request, and this dispatches /uploader requests to handle_uploader and /downloader ones to handle_downloader. These are also very simple, e.g.
1234567891011121314151617
letgetq=Q.Download.peekq>>=fun{Upload_queue.size;data}->letbody=Cohttp_lwt_body.of_streamdatainletheaders=Cohttp.Header.init_with"Content-Length"(Int64.to_stringsize)in(* Adding a content-length loses the transfer-encoding * for some reason, so add it back: *)letheaders=Cohttp.Header.addheaders"transfer-encoding""chunked"inH.respond~headers~status:`OK~body()lethandle_downloaderqrequest=matchH.Request.methrequestwith|`GET->getq|`DELETE->deleteq|`HEAD|`PUT|`POST|`OPTIONS|`PATCH->unsupported_method
The other methods (put and delete) are similar.
Buffered reads
Running as a --unix process, I initially got a download speed of
17.2 KB/s, which was rather disappointing.
Especially as Apache on the same machine gets 615 MB/s!
Increasing the size of the chunks I was reading from the Fat
filesystem (a disk.img file) from 512 bytes to 1MB, I was able to
increase this to 2.83 MB/s, and removing the O_DIRECT flag from
mirage-block-unix, download speed increased to 15 MB/s (so this is
with Linux caching the data in RAM).
To check the filesystem was the problem, I removed the F.read call
(so it would return uninitialised data instead of the actual file contents).
It then managed a very respectable 514 MB/s.
Nothing wrong with the HTTP code then.
Streaming uploads
It all worked nicely running as a Unix process, so the next step was to deploy on Xen.
I was hoping that most of the bugs would already have been found during the Unix testing,
but in fact there were more lurking.
It worked for very small files, but when uploading larger files it quickly ran
out of memory on my 64-bit x86 test system. I also tried it on my 32-bit CubieTruck
ARM board, but that failed even sooner, with Invalid_argument("String.create") (on 32-bit
platforms, OCaml strings are limited to 16 MB).
In both cases, the problem was that the cohttp library tried to read the entire upload in one go.
I found the read function in Transfer_io:
12345678
letread~lenic=(* TODO functorise string to a bigbuffer *)matchlenwith|0->returnDone|len->read_exactlyiclen>>=function|None->returnDone|Somebuf->return(Final_chunkbuf)
I changed it to use read rather than read_exactly (read returns whatever data is available, waiting only if there isn't any at all):
123456789
letread~remainingic=(* TODO functorise string to a bigbuffer *)match!remainingwith|0->returnDone|len->readiclen>>=funbuf->remaining:=!remaining-String.lengthbuf;if!remaining=0thenreturn(Final_chunkbuf)elsereturn(Chunkbuf)
I also had to change the signature to take a mutable reference (remaining) for the remaining data, otherwise it has no way to know when it's done (patch).
Buffered writes
With the uploads now split into chunks, upload speed with --unix was 178 KB/s.
Batching up the chunks (which were generally 4 KB each) into a 64 KB buffer increased the speed to 2083 KB/s.
With a 1 MB buffer, I got 6386 KB/s.
letpage_buffer=Io_page.get256|>Io_page.to_cstructin(* Set the first byte to N to indicate that we're not done yet. * If we reboot while this flag is set, the partial upload will * be deleted. *)letpage_buffer_used=ref1inCstruct.set_charpage_buffer0'N';letfile_offset=ref1inletflush_page_buffer()=Log.info"Flushing %d bytes to disk"!page_buffer_used>>=fun()->letbuffered_data=Cstruct.subpage_buffer0!page_buffer_usedinF.writeq.fsname!file_offsetbuffered_data>>|=fun()->file_offset:=!file_offset+!page_buffer_used;page_buffer_used:=0;return()inletrecadd_datasrci=letsrc_remaining=String.lengthsrc-iinifsrc_remaining=0thenreturn()else(letpage_buffer_free=Cstruct.lenpage_buffer-!page_buffer_usedinletchunk_size=minpage_buffer_freesrc_remaininginCstruct.blit_from_stringsrcipage_buffer!page_buffer_usedchunk_size;page_buffer_used:=!page_buffer_used+chunk_size;lwt()=ifpage_buffer_free=chunk_sizethenflush_page_buffer()elsereturn()inadd_datasrc(i+chunk_size))indata|>Lwt_stream.iter_s(fundata->add_datadata0)>>=flush_page_buffer
Asking on the mailing list confirmed that
Fat is not well optimised.
This isn't actually a problem for my service, since it's still faster than
my Internet connection, but there's clearly more work needed here.
Upload speed on Xen
Testing on my little CubieTruck board, I then got:
Upload speed
74 KB/s
Download speed
1.6 KB/s
Hmm. To get a feel for what the board is capable of, I ran nc -l -p 8080 < /dev/zero on the board
and nc cubietruck 8080 | pv > /dev/null on my laptop, getting 29 MB/s.
Still, my unikernel is running as a guest, meaning it has the overhead of using the virtual network
interface (it has to pass the data to dom0, which then sends it over the real interface). So I installed
a Linux guest and tried from there. 47.2 MB/s. Interesting. I have no idea why it's faster than dom0!
I loaded up Wireshark to see what was happening with the unikernel transfers.
The upload transfer mostly went fast, but stalled in the middle for 15 seconds and then for 12 seconds at the end.
Wireshark showed that the unikernel was ack'ing the packets but reducing the TCP window size, indicating that the packets weren't being processed by the application code.
The delays corresponded to the times when we were flushing the data to the SD card, which makes sense.
So, this looks like another filesystem problem (we should be able to write to the SD card much faster than this).
TCP retransmissions
For the download, Wireshark showed that many of the packets had incorrect TCP checksums and were having to be retransmitted.
I was already familiar with this bug from a previous mailing list discussion: wireshark capture of failed download from mirage-www on ARM.
That turned out be a Linux bug - the privileged dom0 code responsible for sending our virtual network packets to the real network becomes confused if two packets occupy the same physical page in memory.
Here's what happens:
We read 1 MB of data from the disk and send it to the HTTP layer as the next chunk.
Chunked.write does the HTTP chunking and sends it to the TCP/IP channel.
Channel.write_string writes the HTTP output into pages (aligned 4K blocks of memory).
Pcb.writefn then determines that each page is too big for a TCP packet and splits each one into smaller chunks, sharing the single underlying page:
My original fix changed mirage-net-xen to wait until the first buffer had been read before sending the second one.
That fixed the retransmissions, but all the waiting meant I still only got 56 KB/s.
Instead, I changed writefn to copy remaining_bit into a new IO page, and with that I got 495 KB/s.
Replacing the filesystem read with a simple String.create of the same length, I got 3.9 MB/s, showing that once again the
FAT filesystem was now the limiting factor.
Adding a block cache
I tried adding a block cache layer between mirage-block-xen and fat-filesystem, like this:
123456789101112131415161718192021
moduleMain(C:V1_LWT.CONSOLE)(B:V1_LWT.BLOCK)(H:Cohttp_lwt.Server)=structmoduleBC=Block_cache.Make(B)moduleF=Fat.Fs.Make(BC)(Io_page)moduleQ=Upload_queue.Make(F)letmem_cache_size=1024*1024(* 1 MB *)letstartcbhttp=Log.write:=C.log_sc;Log.info"start in queue service">>=fun()->BC.connect(b,mem_cache_size)>>=function|`Error_->failwith"BC.connect"|`Okbc->F.connectbc>>=function|`Error_->failwith"F.connect"|`Okfs->Q.createfs>>=funq->...
With this in place, upload speed remains at 76 KB/s, but the download speed increases to 1 MB/s (for a 20 MB file, which therefore doesn't fit in the cache).
This suggests that the FAT filesystem is reading the same disk sectors many times.
Enlarging the memory cache to cover the whole file, the download speed only increases to 1.3 MB/s,
so the FAT code must be doing some inefficient calculations too.
Replacing FAT
Since most of my problems seemed to be coming from using FAT, I decided to try a new approach.
I removed all the FAT code and the block cache and changed upload_queue.ml to write directly to the block
device.
With that (no caching), I get:
Upload speed
2.27 MB/s
Download speed
2.46 MB/s
That's not too bad. It's faster than my Internet connection, which means that the unikernel is no longer the limiting factor.
Here's the new version: upload_queue.ml.
The big simplification comes from knowing that the queue will spend most of its time empty (another good reason to use a small VM for it).
The code has a next_free_sector which it advances every time an upload starts.
When the queue becomes empty and there are no uploads in progress this variable is reset back to sector 1 (sector 0 holds the index).
This does mean that we may report disk full errors to uploaders even when there is free space on the disk, but this won't happen in typical usage because the repository downloads things as soon as they're uploaded (if it does happen, it just means uploaders have to wait a couple of minutes until the repository empties the queue).
Managing the block device manually brought a few more advantages over FAT:
No need to generate random file names for the uploads.
No need to delete incomplete uploads (we only write the file's index entry to disk on success).
The system should recover automatically from filesystem corruption because invalid entries can be detected reliably at boot time and discarded.
Disk full errors are reported correctly.
The queue ordering isn't lost on reboot.
Conclusions
Modern operating systems are often extremely complex, but much of this is historical baggage which isn't needed on a modern system where you're running a single application as a VM under a hypervisor. Mirage allows you to create very small VMs which contain almost no C code. These VMs should be easier to write, more reliable and more secure.
Creating a bootable OCaml kernel is surprisingly easy, and from there adding support for extra devices is just a matter of pulling in the appropriate libraries. By programming against generic interfaces, you can create code that runs under Linux/Unix/OS X or as a virtual machine under Xen, and switch between configurations using the mirage tool.
Mirage is still very young, and I found many rough edges while writing my queuing service for 0install:
While Linux provides fast, reliable filesystems as standard, Mirage currently only provides a basic FAT implementation.
Linux provides caching as standard, while you have to implement this yourself on Mirage.
Error reporting should be a big improvement over C's error codes, but getting friendly error messages from Mirage is currently difficult.
The system has clearly been designed for high performance (the APIs generally write to user-provided buffers to avoid copying, much like C libraries do), but many areas have not yet been optimised.
Buffers often have extra requirements (e.g. must be page-aligned, a single page, immutable, etc) which are not currently captured in the type system, and this can lead to run-time errors which would ideally have been detected at compile time.
However, there is a huge amount of work happening on Mirage right now and it looks like all of these problems are being worked on.
If you're interested in low-level OS programming and don't want to mess about with C, Mirage is a lot of fun, and it can be useful for practical tasks already with a bit of effort.
There are still many areas I need to find out more about.
In particular, using the new pure-OCaml TLS stack to secure the system and trying the Irmin Git-like distributed, branchable storage to provide the queue instead of writing it myself.
I hope to try those soon...
]]>Python to OCaml: retrospective2014-06-06T10:00:00+00:00https://roscidus.com/blog/blog/2014/06/06/python-to-ocaml-retrospectiveIn 2013, I spent 6 months converting 0install's 29,215 lines of Python to OCaml (learning OCaml along the way).
In this post, I'll describe the approach I took and how it went. There will be graphs.
If you don't want to read the whole thing, the take-away is this:
The new code is a similar length (slightly shorter), runs around 10x faster, and is statically type checked.
Several readers said they've been following this blog without knowing what 0install actually is. So, a quick summary!
Since 2003, 0install's goal has been to provide secure, cross-platform, decentralised software installation.
Secure means that 0install doesn't grant the software root access when you install it (like most package managers do), and doesn't allow packages to conflict with each other (each version of each package goes in its own directory). It should always be safe to "install" a program with 0install, though ideally you'd use a sandbox to actually run it (we're still waiting for a decent sandbox to turn up).
Cross-platform means it works on Linux (it's available from the repositories of all the major Linux distributions), Unix, OS X and Windows (the Windows version is a compatible reimplementation in C#, though it does run some of the original code in a subprocess).
Decentralised means that upstream projects publish their software on their own web-sites. They still get automatic dependency handling (including dependencies on other sites), GPG signatures, automatic updates, roll-back, and support for binary and source packages.
0install can work with the native package manager (e.g. rpm or dpkg) to satisfy dependencies, in addition to downloading them as 0install packages itself.
0install was originally written in C as a Linux kernel module and user-space helper.
It made other software easy to install, but getting 0install itself was rather tricky.
My naive hope was that distributions would include it by default, but needless to say that didn't happen.
In 2005, it was redesigned and reimplemented in Python to simplify distribution.
The subject of rewriting 0install in a compiled language had come up a few times, but in 2013 I had just left my job to take a year off and finally had the time for it. I didn't have any idea what language to use so I collected suggestions and tried them all. My test-case was to read the tutorial for each language and reimplement one trivial (4 line) function of 0install in each one. I looked at various factors, including start-up time, binary size, binary compatibility, safety features, diagnostics, ease of writing, support for shared libraries, and static checking.
There was no very clear conclusion. Rust seemed very promising in the long term, but it was years from being ready. ATS was the fastest and smallest, but too difficult to use. Python and C# were too slow (0install needs fast start-up time). Go did poorly in almost every area I tested. But Haskell and OCaml did surprisingly well.
I tried Haskell and OCaml on a larger sample, converting 576 lines of Python and comparing the code.
They both did well, especially for detecting problems at compile time, but I found OCaml considerably easier to use. It also ran twice as fast.
OCaml can compile to bytecode or to native code. I'd hoped that the bytecode would allow us to distribute a single binary that would work everywhere (as with Java). In this post I did some experiments to check this. It almost worked, but in the end I gave up; we now build separate binaries for each platform.
Polymorphic Variants are an unusual and very powerful feature of OCaml's type system. I found I was able to take advantage of them to check statically that all of 0install's sub-commands handle all their options.
Even though OCaml programmers rarely use objects, the language's support for object-oriented programming was a big help in converting the existing Python code. This post looks at OO programming in OCaml and describes the things that confused me at first.
OCaml code is often written without explicit types, letting the compiler infer everything.
However, it's helpful to understand the details of the type system when it comes to writing interface files (describing a restricted public interface to a module) and when trying to understand compiler error messages. After muddling through for a while, I decided it was time to understand how it actually worked.
I've found OCaml to be very good at detecting problems at compile time and the code has been very reliable. Still, some bugs slip though. In this post, I go over each discovered bug that made it into a Git commit and try to work out why it happened and whether it could have been prevented.
When I first looked at OCaml, I was mainly focused on making sure the things I needed were still available.
With the port complete, I summarise the things you gain from using OCaml.
Code size
The final OCaml code was remarkably similar in length to the original Python:
Lines of code, before and after.
The main code is slightly shorter, while the unit-tests are slightly longer (probably because I added some extra ones).
The functionality is the same, except that the OCaml adds the "0install slave" command (325 lines of OCaml) and uses Lwt
rather than its own asynchronous framework (483 lines of Python).
The Python code also included some XML files for the GTK user interface (shown in orange). In the OCaml, building the widgets
is instead done directly in the code. The OCaml version includes some module interface files (the mli files, shown in green).
These are used to control how much of a module's implementation is visible to other modules. They make the code easier to understand,
but they're mostly optional.
Porting method
I wanted to avoid having two separate forks of 0install (Python and OCaml).
Then most people would continue using the Python version until the OCaml version was finished, resulting in a sudden switch over and the risk of some major flaw in the whole idea going undiscovered until the end.
Also, it would encourage people to submit bug fixes and features to the Python fork, creating extra porting work for me.
Instead, I used a mix of both languages, slowly migrating functions from Python to OCaml.
The two parts communicated using JSON.
I made sure the complete set of unit-tests passed for every commit and that the software remained fully functional throughout the whole process. The graph below shows the amount of Python and OCaml code over time:
Lines of code over time.
For the first couple of months I was just adding OCaml code, duplicating lots of common helper code. For example, the OCaml version needs to be able to parse the XML selections documents, so that code is ported, but parts of the Python still need that code too, so it can't be deleted yet. Once I start deleting Python code, progress is fairly steady until it's all gone. A nice benefit of this approach is that you can see clearly where you are in the process.
Initially, I tried doing clean implementations of the code from the specifications. However, the existing code has a lot of special cases for weird systems and backwards-compatibility hacks, and not all of them were unit-tested. Soon, I switched to translating more literally from the Python and then cleaning it up once it was in OCaml. I kept the basic structure of the Python in most places (e.g. the same classes with the same methods). That made things much easier. Once the port was complete, I did some larger refactoring (such as making the XML type immutable). I think this worked well - refactoring is very pleasant in OCaml.
Binary size
Executable image size over time.
The binary ended up a bit bigger than I'd like. Adding the GTK and OBus libraries in particular added a lot to the size (though they are optional). The main problem with GTK is that it has to be compiled as a plugin, because we don't know if the target system will have libgtk. If we used a single binary and the library wasn't present, it would refuse to start. By having it in a plugin we can try to load it, but fall back to console mode if that fails. However, compiling for plugins prevents OCaml from optimising the binary by removing unused library functions, since it doesn't know which ones might be needed by the plugins.
The binary is compiled with debug symbols, but compiling without has almost no effect (binary becomes 1.5% smaller).
Build time
Build time changes over time.
A full build takes nearly a minute, which isn't too bad. The ocamlbuild command automatically discovers dependencies and rebuilds only what is needed, so incremental builds are usually fast and are generally reliable (the exception is that it doesn't notice if you remove or rename a file, but you always get an error message in that case rather than an incorrect build).
Most errors are picked up by the type checker immediately at the start of the build, rather than by the unit-tests at the end. That saves a lot of time.
Two things did speed it up slightly: building the tests and the main binary with a single invocation (saves having to run the dependency checker twice) and turning on parallel builds. Parallel builds didn't help as much as I'd hoped however.
Update: edwintorok profiled the build and noticed that 25.5% of the time is spent running a bytecode version of the camlp4 pre-processor (which we use for the Lwt syntax extension and for conditional compilation) and 10.5% is spent on a bytecode version of ocamlfind (looks like an ocamlbuild bug).
Why ocamlbuild's parallelization is often disappointing today looks interesting too.
Update 2: I noticed that building while the computer is busy doing something else is much faster! Looks like this is the Linux scaling governor being strange. Echoing "performance" to /sys/devices/system/cpu/cpu[0-3]/cpufreq/scaling_governor takes the build time (on my new laptop) down from 45s to 23s!
There are some changes (module aliases) coming in OCaml 4.02 which should help. Currently, if I change one of the files in the Support module (e.g. Support.Sat) then it first rebuilds Sat, then rebuilds Support with the new Sat module, then rebuilds everything that uses Support (which is everything). In reality, it only needs to rebuild Zeroinstall.Solver when Sat changes.
If you do need to modify one of the early modules and run the unit tests quickly, a good trick is to compile to byte-code rather than to native. The byte-code compiler doesn't do cross-module inlining optimisations, which means that as long as a module's interface doesn't change, it doesn't need to recompile the things that depend on it.
One interesting feature of the graph is that during December the build time increased faster in proportion to the lines of code added.
This corresponds to the time I was implementing the GTK GUI, so it looks like GUI code takes longer to compile than normal code of the same length.
Speed
And the final result: running various operations with the old and new versions:
Test
Python 3
OCaml
Speed-up
0install --help
103 ms
8 ms
12.9
0install select 0repo
322 ms
38 ms
8.5
0install run -w echo armagetron
120 ms
15 ms
8.0
0install run armagetron --version
153 ms
45 ms
3.4
The first (--help) shows the overhead of running 0install and producing some simple output.
The extra speed here really helps with tab-completion!
The second test (select) shows 0install running its SAT solver to select a compatible set of libraries to run the "0repo" application.
The third shows 0install setting up the environment to run Armagetron (-w echo echos the executable path rather than actually running it) and the fourth shows it actually running the program.
Speed of 0install in Python vs OCaml.
One other nice win is the time taken to run the unit-tests, which has dropped considerably:
Time to run the unit tests (in seconds).
The spike in the middle is the effect of the JSON bridge, where many tests involved communication between the Python and OCaml parts.
In theory, OUnit should be able to run the tests in parallel on multi-core systems, which would make it even faster, but a bug in OUnit means it doesn't work.
Conclusions
It's surprising to me how reliable the initial tests were.
Even though I only converted 4 lines of Python, the tests uncovered pretty much all of OCaml's weaker aspects (non-portable bytecode, lack of support for shared libraries, relatively large binary size, and somewhat terse error messages from the standard library), meaning there were no nasty surprises during the migration.
However, the testing was less successful at uncovering the benefits (excellent type checking, reliability, exhaustive pattern matching, polymorphic variants, abstract types, easy GTK bindings, and API stability).
Blogging about the whole process was extremely useful, attracting many helpful comments, suggestions and corrections from experienced OCaml users.
Epilogue
The blog attracted the attention of the OCaml folks at Cambridge University, who do all kinds of interesting OCaml things.
As a result, I'm now working there, adding ARM support to the Mirage unikernel - an operating system written in OCaml (the Mirage web-site is all implemented in OCaml, down to and including the TCP/IP stack!).
That will have to be the subject for another blog post though...
]]>OCaml: what you gain2014-02-13T11:17:24+00:00https://roscidus.com/blog/blog/2014/02/13/ocaml-what-you-gainWay back in June, in Replacing Python: second round, I wrote:
The big surprise for me in these tests was how little you lose going from Python to OCaml.
Of course, I was mainly focused on making sure the things I needed were still available. With the port now complete (0install 2.6 has been released, and contains no Python code), here's a summary of the main things you gain.
I started these blog posts unemployed (taking a career break), with no particular connection to any of the languages, and motivated to make a good choice since I'd be using it a lot. I wasn't biased towards OCaml; it wasn't even on my list of candidates until a complete stranger suggested it on the mailing list.
But I must now disclose that, since my last blog post, I'm now getting paid for writing OCaml.
Functional programming
Some people commented it was good to see more projects moving to functional programming. So, what's it like doing functional programming after Python? To be honest, not much has changed. According to OCaml's What is functional programming?, "In a functional language, functions are first-class citizens" and "The fact is that Perl is actually quite a good functional language".
So, if you've ever used Python's (built-in) map, reduce, filter or apply functions, ever written or used a decorator or ever passed a function as an argument to another function, you're already doing functional programming as far as OCaml is concerned. By contrast, "pure functional programming" (as in Haskell) would be a major change.
OCaml does make partially applying functions easier, which is sometimes convenient, and it supports tail recursion. Tail recursion allows you to write loops in a functional style (without needing break, continue or mutable state). That can make it easier to reason about loops, but I couldn't find any examples in 0install where this style was clearly better than a plain Python loop.
Type-checking
I've used statically-typed languages before (I used to program in Java for my day job). That can catch many errors that Python would miss, but OCaml's type system is far more useful than Java's. Here's an example, where we want to display an icon for some program in the GUI:
12
get_iconprogram|>widget#set_icon(* Error! *)
Error: This expression has type Icon.t -> unit
but an expression was expected of type Icon.t option -> 'a
Oops. The program might not have an icon (icons are optional). We'll need to use a default one in that case:
Error: This expression has type feed_url
but an expression was expected of type [< `remote_feed of url ]
The second variant type does not allow tag(s) `local_feed
Java makes you do all the work for static type checking, but manages to miss many of the benefits.
No matter how much care you take with your Java types, there's always a good chance you're going to crash with a NullPointerException.
By requiring correct handling of None (null) and ensuring pattern matching is exhaustive, OCaml's type checking is far more useful. As with Haskell, when a piece of OCaml code compiles successfully, there's a very good chance it will work first time.
And, of course, static checking makes refactoring much easier than in Python. For example, if you remove or rename something, the compiler will always find every place you need to update.
Data type definitions
OCaml makes it really easy to define new data types as you need them. The types are always easy to see, and you know that OCaml will enforce them (unlike comments in Python, which may be incorrect). Here's a record type for the configuration settings for an interface (an optional stability level and a list of extra feeds):
The OCaml labels tutorial describes polymorphic variants as a way to use the same name (e.g. Open) for different things (e.g. opening a door vs opening a lock) and says:
"Because of the reduction in type safety, it is recommended that you don't use these in your code".
This is quite misleading (and I was quickly corrected when I repeated it).
Their real purpose is to support subsets and supersets, which are useful all over the place. Some examples:
The "0install" command-line parser accepts a large number of options. The "0install run" subcommand accepts a subset of these. That subset can be further subdivided into common options (present in all commands, such as --verbose), options common to selection commands (e.g. --before=VERSION) and those specific to "0install run" (e.g. --wrapper=COMMAND).
The GUI code that handles dialog responses (OK, Cancel, etc) must handle the union of all the action button responses it added and the always-present window close icon.
The download code only handles the subset of feed URLs that represent remote resources.
Users can only register local and remote feeds to an interface, not distribution-provided virtual feeds.
Cached feeds contain only remote implementations, local feeds contain local and remote implementations, and distribution feeds contain only distribution implementations. All three types get combined together and passed to the solver.
Here's an example, showing the run command dividing its options into sub-groups, with the compiler checking that every option will be handled in all cases:
Without polymorphic variants, OCaml's exhaustive matching requirements mean you'd have to provide code to handle cases that (you think) can't happen. That's tedious and your program will crash if you get it wrong. Polymorphic variants mean you can prove to the compiler that only the correct subset needs to be handled at each point in the code. This is fantastic, and I can't think of any other major language that does this (though I'm sure people will suggest some in the comments).
Immutability
In OCaml, all variables and record fields are immutable by default. This is far saner than Java (where the default is mutable and you must use final everywhere to override it). Immutable is a better default because:
Typically, you want most things to be immutable (in any language).
If you forget to mark something as mutable, the compiler will quickly let you know, whereas forgetting to mark something as immutable would be missed.
With mutable structures, you are always worrying about whether one piece of code will mutate a structure that another is relying on. For example, I originally made the XML element type mutable, but I found I was writing comments like this:
12
(** Note: this returns the actual internal XML; don't modify it *)valas_xml:selections->element
After removing the mutable annotations from the element declaration, the compiler showed me each piece of code I needed to modify to make it work again. Then, I was able to remove those notes.
[ The main difficulty in this conversion was handling XML namespace prefixes. Previously, each element had a reference to its owning document, which held a shared (mutable) pool of prefix bindings. Now, each namespaced item holds its preferred prefix, and the output code builds up a set of bindings before writing out the tree. ]
There is one case where Python and Java do better than OCaml: OCaml strings are mutable! The convention is to treat them as immutable, though.
Update: OCaml 4.02 has an option for immutable strings, with a separate Bytes.t for mutable byte arrays.
Abstraction
OCaml makes it very easy to hide a module's implementation details from its users using abstract types.
I gave one example in the bugs post, where hiding the fact that a sorted tree is really the same type as an unsorted one prevents bugs due to mixing them up.
Here's another example. In the Python code, we would parse a selections XML document into a Selections object, like this:
I found all this parsing and serialising complicated things and so in the OCaml rewrite I decided to use the plain XML element type everywhere.
That did simplify things, but it also removed some safety and clarity from the APIs.
Consider the Selections.create function (which now does nothing unless the document is in an old format and needs to be upgraded):
It's nice and simple, but it just returns an element. It would be easy to pass some other XML element to a function that only works on selection documents (or to pass a document that's still in the old format).
We can solve this simply by declaring an abstract type for selection documents in the interface file (selections.mli):
12
typetvalcreate:element->t
(note: it's an OCaml convention for a module's main type to be called t; other modules will refer to this type as Selections.t)
I think this gets the best of both worlds. Internally, a selections object is just the XML root element, which is simple and efficient, but code using it can't mix up the types. And, of course, we can change the internal type later if needed without breaking anything.
This isn't a particularly novel idea (you can do something similar in C). However, Python and Java would require you to write a wrapper object around the object you want to hide, and Python makes it easy for users of the API to access the internal representation even then. If you're writing a library, OCaml (like C) makes it clear when you're changing the module's interface vs merely changing its implementation.
( There is another interesting feature, which I haven't used yet: you can use the "private" modifier to say that users of the module can see the structure of the type but can't create their own instances of it. For example, saying type t = private element would allow users to cast a selections value to an XML element, but not to treat any old XML as a selections value. )
I did experience one case where abstraction didn't work as intended. In the SAT solver, I declared the type of a literal abstractly as type lit and, internally, I used type lit = int (an array index). That worked fine. Later, I changed the internal representation from an int to a record. Ideally, that would have no effect on users of the module, but OCaml allows testing abstract types for equality, which resulted in each comparison recursively exploring the whole SAT problem. It can also cause runtime crashes if it encounters a function in this traversal. Haskell's type classes avoid this problem by letting you control which types can be compared and how the comparison should be done.
Speed
Python is well known for being slow, but much of what real programs do is simply calling C libraries.
For example, when calculating a SHA256 digest, C does all the heavy lifting.
Despite this, I've found OCaml to be fairly consistently 10 times faster in macro benchmarks (measuring a complete run of 0install from start to finish). Also, although I've added a lot of code and dependencies since the initial benchmarks, it still runs almost as quickly.
The 0release benchmark took 8ms with June's minimal version, compared to 10ms with the final version.
When doing pure calculations (e.g. a tight loop adding integers), OCaml is typically more than 100x faster than Python.
Even so, OCaml is probably not a great choice for CPU-intensive programs. Like Python, it has a global lock, so you can't have multiple threads all using the CPU at once. But if you're writing small utilities that need to run quickly, it's perfect.
Update: There is a multicore OCaml branch under development which removes the global lock.
No dependency cycles
Perhaps I'm making a virtue of a flaw here, but I like the fact that OCaml doesn't allow cyclic dependencies between source files.
I think this leads to cleaner code (back when I was writing Java, I wrote a script to extract all module dependencies and graph them so I could find and eliminate cycles).
What this means is that in any OCaml code-base, no matter how complex, there's always at least one module that doesn't depend on any of the others and which you can therefore read first.
Then there's a second module that only depends on the first one, etc.
For example, here are the modules that make up 0install's GTK plugin (note the lack of cycles):
Cycles can be a problem when converting existing code to OCaml, though. For example, the Python had a helpers.py module containing various high-level helper functions (e.g. get_selections_gui to run the GUI and return the user's selections, and ensure_cached to make sure some selections are cached and download them if not). That doesn't work in OCaml, because the helpers module depends on the GUI, but the GUI also depends on the helpers (the GUI sometimes needs to ensure things are cached). The result is that I had to move each helper function to the module it uses, but I don't mind because the result is a clearer API.
Another example is the Config object. When I started the Python code back in 2005, I was very excited about using the idea of dependency injection for connecting together software modules (this is the basis of how 0install runs programs). Yet, for some reason I can't explain, it didn't occur to me to use a dependency injection style within the code. Instead, I made a load of singleton objects. Later, in an attempt to make things more testable, I moved all the singletons to a Config object and passed that around everywhere. I wasn't proud of this design even at the time, but it was the simplest way forward. It looked like this:
OCaml really didn't like this design! config.py depends on all the other modules because it calls their constructors, while they all depend on it to get their dependencies.
Note that this design isn't very safe: Fetcher's constructor could ask for config.trust_mgr, and TrustMgr's constructor could ask for config.fetcher. In Python, we have to remember not to do that, but in OCaml we'd like the type checker to prove it can't happen.
In most places, I fixed this by passing to each constructor just the objects it actually needs, which is cleaner.
Another approach, which I used when lots of objects were needed, is that instead of requiring a config object, a class can take simply "an object with at least fetcher and trust_mgr methods".
Then we know statically that it will only call those methods, even though we actually give it the full config object.
The result of all this is that you can look at e.g. the fetch.mli interface file and see exactly which other modules it depends on, none of which will depend on it.
GUI code
Converting the GTK GUI to OCaml (using the LablGtk bindings), I replaced 5166 lines of Python (plus 1736 lines of GtkBuilder XML) with 4017 lines of OCaml (and no XML). I'm not sure why, but writing GTK code in OCaml just seems to be much easier than with Python.
I used GtkBuilder in the Python code in the hope that it would make it easier to modify the layouts, and to improve reliability (since the XML should always be valid, whereas Python code might not be). However, it actually made things harder because Glade (the editor) is constantly trying to force you to upgrade to the latest (incompatible) XML syntax, and I ended up having to run an old OS in a VM any time I wanted to edit things.
In the OCaml, the static type checking gives us similar confidence that the layout code won't crash. Also, with GtkBuilder you name each widget in the XML and then search for these names in the code. If they don't match, it will fail at runtime. Having everything in OCaml meant that couldn't happen. [ Note: I later discovered that LablGtk doesn't support GtkBuilder anyway. ]
Here's an example of some OCaml GTK code and the corresponding Python code. This shows how to build and display a menu (simplified to have just one item):
OCaml
1234
letmenu=GMenu.menu()inletexplain=GMenu.menu_item~packing:menu#add~label:"Explain this decision"()inexplain#connect#activate~callback:(fun()->show_explanationimpl)|>ignore;menu#popup~button:(B.buttonbev)~time:(B.timebev);
Python
1234567891011
globalmenu# Fix GC problem with PyGObjectmenu=gtk.Menu()item=gtk.MenuItem()item.set_label('Explain this decision')item.connect('activate',lambdaitem:self.show_explanation(impl))item.show()menu.append(item)ifsys.version_info[0]<3:menu.popup(None,None,None,bev.button,bev.time)else:menu.popup(None,None,None,None,bev.button,bev.time)
Some points to note:
LablGtk allows you to specify many properties at once in the constructor call, whereas in PyGTK we need separate calls for each.
The Python API broke between Python 2 and Python 3, so we have to make sure to use the right one. It's not sufficient to test the Python code using only one version of Python!
The Python bindings have always suffered from garbage collection bugs. If we don't store menu in a global variable, it may garbage collect the menu while the user is still choosing - this makes the menu disappear suddenly from the screen!
Actually, I see that Python's MenuItem takes a label argument, so maybe I could save a line. Or maybe that doesn't work on some older version. It's not worth the risk of changing it.
Update: I used the original layout for the OCaml above as I was comparing line counts, but it's a bit wide for this narrow blog and some people are finding it hard to read. Here's an expanded version which uses less special syntax:
12345678
letmenu=GMenu.menu()inletexplain=GMenu.menu_item~packing:menu#add~label:"Explain this decision"()inletcallback()=show_explanationimplinlet_signal_id=explain#connect#activate~callbackinmenu#popup~button:(B.buttonbev)~time:(B.timebev)
Here, ~ indicates a named argument and # is a method call. So menu_item ~packing:menu#add ... is like menu_item(packing = menu.add, ...) in Python.
However, I did still have a few problems with the OCaml GTK bindings:
There's no support for custom cell renderers. I used three of these in the Python version and had to find alternative UIs for each.
Various minor functions aren't included for some reason. The ones I wanted but couldn't find were Dialog.add_action_widget, Style.paint_arrow, MessageDialog.BUTTONS_NONE, Dialog.set_keep_above, icon_size_lookup and Selection_data.get_uris.
I had to work around a bug in the IconView support (reported but with no response and fixed immediately, although the bug report wasn't updated).
You usually don't need the result of creating a label or attaching a signal so you need to use ignore, which can cause silent failures if you forgot an argument (it will ignore the partial function rather than the widget or signal result). Probably I should make ignore_signal and ignore_widget utility functions.
Update: I did add ignore_widget, but for signals I found a better solution: I created a new ==> operator to connect a signal and ignore the resulting signal ID. It's used like this:
This is a community thing rather than a language issue, but OCaml and OCaml libraries seem to be very good at maintaining backwards compatibility at the source level. 0install supports the old OCaml 3.12 and libraries in Ubuntu 12.04 up to the latest OCaml 4.01 release without any problems. The only use of conditional compilation for compatibility is that we don't define the |> operator on 4.01 because it's already a built-in (this avoids a warning).
On the other hand, binary compatibility is very poor. You can replace the implementation of a module with a newer version as long as the public interface doesn't change (good), but any change at all to the interface requires everything that depends on it to be recompiled, and then everything that depends on them, and so on.
For example, if the List module adds a new function then the signature of the List module changes. Now any program using the new version of the List module is incompatible with every library binary compiled against the old version. Even if nothing is even using the new function! This means that distributing OCaml libraries in binary form is effectively impossible.
Summary
OCaml's main strengths are correctness and speed. Its type checking is very good at catching errors, and its "polymorphic variants" are a particularly useful feature, which I haven't seen in other languages. Separate module interface files, abstract types, cycle-free dependencies, and data structures that are immutable by default help to make clean APIs.
Surprisingly, writing GTK GUI code in OCaml was easier than in Python. The resulting code was significantly shorter and, I suspect, will prove far more reliable. OCaml's type checking is particularly welcome here, as GUI code is often difficult to unit-test.
The OCaml community is very good at maintaining API stability, allowing the same code to compile on old and new systems and (hopefully) minimising time spent updating it later.
]]>OCaml: the bugs so far2014-01-07T10:48:55+00:00https://roscidus.com/blog/blog/2014/01/07/ocaml-the-bugs-so-farOCaml's static typing allows it to detect many problems at compile-time. Still, some bugs slip though. In this post, I go over each discovered bug that made it into a Git commit and try to work out why it happened and whether it could have been prevented.
Note: As this post is entirely about bugs, it may appear rather negative. So let me say first that, overall, I've been very impressed with the reliability of the OCaml code: I'd have expected to find more bugs than this in 27,806 lines of new code!
I've gone back through the Git commit log and selected all the ones that say they fix a bug in the comment, starting from when I merged the initial OCaml code to master (on 2013-07-03). It's possible that I sneakily fixed some bugs while making other changes, but this should cover most of them. Any bug that made it into a released version of 0install should certainly have its own commit because it would have to go on the release branch. I also included a few "near misses" (bugs I spotted before committing, but which I could plausibly have missed).
In a number of cases, I wrote and committed the new OCaml code first, and then ported the Python unit-tests in a later commit and discovered the bug that way (so some of these could never have made it into an actual release). Compile-time bugs have been ignored (e.g. code that didn't compile on older versions of OCaml); I'm only interested in run-time errors here.
I've classified each bug as follows:
Inexperience
This bug was caused by my inexperience with OCaml. Making proper use of OCaml's features would avoid this class of bug entirely.
Third-party
Caused by a bug in a library I was using (and hopefully now fixed). Could only have been discovered by testing.
Poor API
This bug was my fault, but could have been avoided if the library had a better API.
Warning needed
My fault, but the compiler could have detected the problem and issued a warning.
Testing only
I only know how to find such bugs through testing. Similar bugs could happen again.
Core OCaml issues
Note: I'm grouping the bugs by the library the code was interacting with, regardless of whether that library was at fault. This section is for bugs that occurred when just using OCaml itself and its standard library.
Out-of-range integers
Everything seemed to be working nicely on my Arch system, but the first run on a Debian VM gave this unhelpful error:
Failure "int_of_string"
I was trying to store a Unix timestamp in an int. Unlike Python, OCaml's integers are limited precision, having 1 bit less than the machine word size. The 32-bit VM only had 31-bit integers and the time value was out of range for it.
This was entirely my fault. OCaml always uses floats to represent times, and they work fine. I was just converting to ints to be consistent with the Python code.
However, the error message is very poor. I replaced all calls to int_of_string with my own version, which at least displays the number it was trying to convert. This should make debugging any similar problems easier in future.
Type: Inexperience
Fails to start on Windows
Windows kept complaining that my program didn't exist and to check that the path was correct, even when I was double-clicking on the executable in Explorer!
Turns out, Windows refuses to run binaries with certain character sequences in their names ("instal" being one such sequence). See Vista doesn't start application called "install" w/o being elevated.
Solution: you have to embed an XML "manifest" in Windows binaries to avoid this behaviour. Would be nice if OCaml did that automatically for you.
Type: Third-party
Spawning a daemon fails on Windows
Windows doesn't have fork, so the usual double-fork trick doesn't work.
Solution: Use create_process on Windows.
Would be nice if OCaml grouped all the POSIX-only functions together and made you check which platform you were on. Then you'd know when you were using platform-specific functions. e.g.
I forget to handle the Refresh case for the "select" command.
Different commands need to handle different subsets of the options. I was using a plain variant (enum) type and throwing an exception if I got an option I wasn't expecting:
(Note: Several people have asked why I used a default match case here. It's needed because there are many options that don't apply to the "select" command. The option parser makes sure that each sub-command's handler function is only called with options it claims to support.)
Solution: I switched from plain variants to polymorphic variants and removed the default case. Now, the type-checker verifies at compile-time that each subcommand handles all its options:
When printing diagnostics about a failed solve, we check each interface to see if it has a replacement that it conflicts with. e.g. the new "Java" interface replaces (and conflicts with) the old "Java 6" interface. But if the conflicting interface wasn't used in the solve, we'd crash with:
Exception: Not_found
I use a lot of maps with strings as the keys. I therefore created a StringMap module in my common.ml file like this:
1
moduleStringMap=Map.Make(String)
StringMap.find raises Not_found if the key isn't found, which is never what you want. These exceptions are awkward to deal with and it's easy to forget to handle them.
A nice solution is to replace the definition with:
This redefines the find method to return an option type. Now you can't do a StringMap.find without the compiler forcing you to consider the case of the key not being there.
Would be nice if the OCaml standard library did this. Perhaps providing a Map.get function with the new behaviour and deprecating Map.find?
Type: Poor API
Octal value
I used 0700 instead of 0o700 to set a file mode. Would be nice if OCaml warned about decimals that start with 0, as Python 3 does.
Type: Warning needed
Parsing a path as a URL
This didn't actually get committed, but it's interesting anyway. Downloaded feeds are signed with GPG keys, which are trusted only for their particular domains. At one point, I used Trust.domain_from_url feed.url to get the domain. It was defined as:
1
letdomain_from_urlurl=...
However, feeds come in different types: there are remote feeds with URLs, and local feeds with local paths (there are also virtual "distribution" feeds representing the output from the distribution's package manager).
I was trying to get the trust domain for all feeds, not just remote ones where it makes sense.
Once again, the solution was to use polymorphic variants. The three different types of feed get three different constructors. A method (such as domain_from_url) that only works on remote feeds is declared as:
1
letdomain_from_url(`remote_feedurl)=...
Then, it's impossible to call it without first ensuring you've got a remote feed URL.
This change also improves the type-safety of many other parts of the code (e.g. you can't try to download a local feed now either), and uncovered another bug: you couldn't use the GUI to set the stability rating for a distribution-provided implementation, because one of the functions used only worked for non-distribution feeds.
Type: Inexperience (x2)
Interrupted waitpid
The Unix.waitpid function can raise EINTR if the system call is interrupted, although the documentation doesn't mention this. It would be nice if OCaml would automatically restart the call in this case (as Python's subprocess module does).
Type: Poor API
HTTP redirects with data cause corrupted downloads
We download to a temporary file. If we get an HTTP redirect, we truncate the file and try the new address. However, ftruncate doesn't reset the position in the file. So, if the redirecting site sent any data in its reply, you'd get that many zeroes at the start of the download. As with waitpid, OCaml's behaviour is standard POSIX, but not mentioned in the OCaml documentation.
Solution: seek_out ch 0.
Also, I updated the test server used in the unit-tests to send back some data when doing a redirect.
Type: Testing only
Setting wrong mtime
Unix.utimes is supposed to set the mtime and atime of a file to the given values. However, the behaviour is a little odd:
When 1 <= time < infinity, it sets it to the requested time.
When 0 <= time < 1 however, it sets it to the current time instead.
That's a problem for us, because we often use "0" as the time for files which don't have a timestamp, and the time is part of the secure hashes we calculate.
Solution: I wrote a C function to allow setting the time to whatever value you like.
This bug didn't make it into a commit because I hit it while writing a test script (I was trying to reset a timestamp file to time zero), and the unit-tests would have caught it if not, but it's still a poor API. Not only does it fail to use a variant type to handle different cases, but it chooses a magic value that's a valid input!
Or, rather than using a variant type for these two cases, it could just drop the magic current time feature completely - it's easy enough to read the current time and pass it explicitly if you need it. That would make the code clearer too.
(note: the documentation does say "A time of 0.0 is interpreted as the current time", but it's easy to forget this if it wasn't relevant the first time you read the docs)
Type: Poor API
Strict sequences
This didn't make it into a commit, but it's interesting anyway. Simplified version of the problem:
Why is there no warning? You might expect OCaml would infer the type of fn as unit -> unit and then complain that the function we pass has the wrong type (unit -> string -> unit).
In fact, although OCaml warns if you ignore the result of a function that doesn't return unit, it's not actually an error. So it actually infers the type of fn as (unit -> 'a), and it compiles fine.
Solution: always compile with -strict-sequence (or put true: strict_sequence in your _tags file)
Type: Inexperience
Lwt-related bugs
Lwt process fails with empty string
When spawning a process, the Lwt docs say you can pass an empty string as the binary to run and it will search for the first argument in $PATH for you. However, that behaviour was added only in Lwt 2.4 and using the older version in Debian it failed at runtime with a confusing error.
Probably I should have been reading the old version of the docs (which the web-site helpfully lets you do).
I'm classifying this as a poor API because it was caused by using "" as a magic value, rather than defining a new constructor function.
Type: Poor API
EPIPE on Windows
On Windows, we couldn't read the output of GnuPG. This was due to a bug in Lwt, which they quickly fixed:
We download various files to a temporary directory. In some cases, they weren't being deleted afterwards.
Solution: the downloader now takes a mandatory Lwt switch and deletes the file when the switch is turned off. Callers just have to wrap the download call in a try ... finally block, like this:
To make this completely foolproof, you'd need something like the linear types from Rust or ATS, but this is good enough for me.
Type: Inexperience
Race shutting down test HTTP server
Some of the unit tests run a simple HTTP server. When the test is over, they use Lwt.cancel to kill it. However, it appears that this call is unreliable: depending on exactly what the server is doing at the time it might just ignore it and continue.
Solution: we both cancel the task and set a boolean flag, which we test just before calling accept. If we're in accept at the time of the cancel, the thread will abort correctly. If it's anywhere else, it may continue handling the current request, but will quit as soon as it finishes and checks the flag.
Would perhaps be nice if Lwt remembered that an attempt was made to cancel the thread during a non-cancellable operation, and killed it at the next opportunity.
Type: Poor API
A related race occurred if we spawned a child process while handling an HTTP request, because the child would inherit the client socket and it would never get closed.
Solution: Use Lwt_unix.set_close_on_exec connection as soon as the connection is accepted.
Note that both these hacks should be race-free, because Lwt is cooperatively multi-threaded (e.g. we can't spawn a subprocess between accepting a connection and marking it close_on_exec). I think.
Ideally, when spawning a child process you'd specify the file descriptors you wanted it to inherit explicitly (Go does this, but really it needs to be at the POSIX level).
Type: Testing only
(although these bugs only occurred in the unit-tests, I'm including them because they could just as easily appear in the main code)
Reactive event handler gets garbage collected
The OCaml D-BUS bindings use functional reactive programming to report property values.
The idea is that you get an object representing the continuously-varying value of the property, rather than a particular sample of it.
Then you can handle the signal as a whole (for example, you can get the "progress" signal from a PackageKit transaction and pass it to a GUI progress monitor widget, so that the widget always shows the current progress).
You can build up chains of signal processors. For example, you might transform a "bytes downloaded" signal into a "percentage complete" one.
The technique seems to come from Haskell. Being purely functional, it's always safe to garbage collect a signal if no-one is holding a reference to it.
However, OCaml is not purely functional. You might easily want to evaluate a signal handler for its side-effects.
I created a handler to monitor the transaction status signal to see when it was finished, and attached the resulting signal to a Lwt_switch.
My plan was that the switch would keep it alive until it fired.
That didn't work, because there was a subtle circular reference in the whole scheme, and OCaml would sometimes garbage-collect the handler and the switch. Then the process would ignore the finished event and appear to hang. I asked on StackOverflow and got some suggestions:
The solution seems to be to keep references to all active signals in a global variable. Rather messy.
Type: Testing only
Stuck reading output from subprocess
When using the Lwt_glib module to integrate with the GTK mainloop, the HUP response from poll is ignored. This means that it will call poll endlessly in a tight loop.
Patch
Type: Third-party
Downloads never complete
When using Lwt_glib, downloads may never complete. This is because OCaml, like Python, has a global lock and Lwt_glib fails to release it when calling poll. Therefore, no other thread (such as the download thread) can make progress while the main thread is waiting (e.g. for the download thread to finish).
Patch
Type: Third-party
Event loop doesn't work on OS X
Lwt_glib passes -1000 to poll to mean "no timeout". This works on Linux, but not on BSD-type systems.
Patch
Type: Third-party
Curl-related bugs
Failing to reset Curl connections
For efficiency, Curl encourages the reuse of connections. However, I forgot to reset some parameters (max file size and expected modification time). If the next call didn't use them, it would reuse the old values and possibly fail.
Newer versions of ocurl have a reset function, which avoids these problems.
Type: Poor API
Error with cancelled downloads
Downloads were sometimes failing with this confusing error:
easy handled already used in multi handle
It happened when reusing connections (which Curl encourages, for efficiency).
There was no direct way to cancel a download, so I handled cancellation by closing the channel the download was writing to.
Then, next time some data arrived, my write callback would fail to write the new data and throw an exception, aborting the download.
It turned out that this was leaving the connection in an invalid state.
Solution: return 0 from the handler instead of throwing an exception.
Ideally, ocurl should catch exceptions from callbacks and allow the C code to clean up properly. Now fixed.
Type: Third-party
GTK bugs
Sorted treeview iter mix-up
(I caught this before committing it, but it's a nasty bug that could easily be missed. It was present for a while in the original Python version.)
The cache explorer dialog allows you to delete implementations from the cache by selecting an item and pressing the Delete button.
It also allows you to sort the table by clicking on the column headings.
However, if you sort the table and then delete something, it deletes the wrong thing!
To make a sortable table (which is just a special case of a tree to GTK), you first create an underlying (unsorted) list model, then wrap it with a sorted model, then pass that to the display widget (GtkTreeView), like so:
To do things with the model, you pass it a GtkTreeIter, which says which item you want to act on, e.g.
1
model#removeiter
The trouble is, sorted and unsorted GtkTreeIters both have the same type, so you can easily pass an iterator of the sorted model as an argument to the unsorted model.
Then it will act on the wrong item.
If the view isn't sorted then everything works fine, so you might not notice the problem while testing.
Solution: I created a new module for unsorted lists. The implementation (unsorted_list.ml) just proxies calls to the real code:
However, the interface (unsorted_list.mli) makes the types t (the model) and iter (its GtkTreeIters) abstract, so that code outside of the module isn't allowed to know their real types:
It's still possible to mix up iterators in some cases (e.g. between two different instances of a sorted model), but that's a much less likely mistake to make.
Another way to solve the problem would be to bundle the owning model with each iterator, but that would be a big change to how the underlying GTK library works.
And ATS could solve this easily using its dependant types, by declaring the iterator type as iter(m) ("iterator of model at address m"), linking models to iterators in the type system.
Type: Poor API
Crashes with GtkIconView
As with GtkTreeView, you can make a sorted GtkIconView with a pair of models.
For some reason, clearing the underlying model didn't clear the sorted version, and repopulating it corrupted memory:
Program received signal SIGSEGV, Segmentation fault.
Solution: since there is no UI to let the user change the sort column, I just removed the sorted model and sorted the underlying model myself in OCaml. I guess this is probably a GTK bug.
Type: Third-party
A second crashing bug with GtkIconView is caused by a bug in lablgtk.
The C wrapper get_path_at_pos returns a tree_path option (None if you clicked in a blank area), but the OCaml declaration says it returns a plain tree_path.
Solution: use Obj.magic to do an unchecked cast to the correct type:
Even the low-level GTK bindings are presumably not generated automatically. If they were, this kind of mismatch surely couldn't happen.
An OCaml optional pointer doesn't have the same representation as a non-optional pointer. If it did, the code wouldn't crash. This suggests OCaml is being a bit inefficient about option types, which is disappointing.
Type: Third-party
Logic errors
The remaining bugs aren't very interesting, but I've included them for completeness:
Failed to handle ambiguous short options (e.g. -r)
Missing tab completion for 0install add
0install run ignores --gui option
Infinite loop handling recursive dependencies
Allow absolute local paths in local implementations
Default command for --source should be compile, not run
Allow machine:null in JSON response
Typo: scripts start #! not !#
Report an error if we need to confirm keys during a headless background update
Wrong attribute name in overrides XML file
Allow executing selections with no command but an absolute main
Handle local-path on <group> elements
Wrong attribute name when saving user overrides
Typo: "https://" not "https://'"
Don't try to use GUI in --dry-run mode
Support old version of selections XML format
Support old selections without a from-feed attribute
Don't send an empty GetDetails request to PackageKit
Cope with dpkg-query returning a non-zero exit status
Detect Python even if python-gobject is missing
Race when cancelling downloads
Type: Testing only (x21)
Python bugs
Just for interest, here are the Python bugs discovered over the same period (it doesn't make sense to compare bug counts, because these are bugs in mature code, often several years old, not just-written new code).
I think these would be impossible or unlikely in OCaml (the problem would be detected at compile time):
Error setting machine type for Cygwin packages (type error)
When loading selections from a file, convert last-check-mtime attribute to an int (type error)
UnicodeError extracting or generating a manifest for archives with non-ASCII file names (no encoding of file names in OCaml :-)
Crash when specifying bold text (PyGTK API change)
Broken clipboard handling in cache explorer (PyGTK API change)
Broken filtering in cache explorer (PyGTK API change)
Broken cache explorer menu when using a filter (model mix up; could avoid with abstract types, as above)
Fails running an app when the master feed is no longer cached (would be forced to handle None case in OCaml)
These would likely still be bugs in OCaml:
Fix mtime check in selections.get_unavailable_selections for native packages
Always return False for native packages in needs_download if include_packages is False
Always use the prefix "xml" for the XML namespace
Don't abort solving just because a local feed is missing
Escape tooltips in cache explorer
32-bit size limit in cache explorer
This was a third-party bug:
Workaround for PyGTK garbage collection bug
Summary
Despite the newness of the code, the bug-rate has been surprisingly low so far. Of the (detected) bugs that did make it past the compiler, about a sixth were due to bugs in third-party libraries, another sixth could have been avoided with better third-party APIs and a sixth we due to my inexperience with OCaml. For the remaining half, more testing is still the only way I can see to find such bugs.
It's a shame that OCaml seems to have no system for deprecating old APIs. This means that poor API choices made years ago are still causing trouble today. It would be good if OCaml could flag functions as being there for historical reasons only, and issue a compiler warning if you used them. I do, however, like the fact that they stay around - breaking existing code (as Python 3 did) is not the solution either!
Two of the bugs ("Deleting temporary files" and "Reactive event handler gets garbage collected") could have been avoided if OCaml had linear types, but I have reasonable solutions to both. The XML / JSON handling bugs could have been avoided by using proper schemas, but such schemas didn't exist (my fault).
Overall, I'm pretty happy with the bug rate so far. No doubt more bugs will be discovered as the new code makes its way into the distributions and gains more users, but I think this code will be easier to maintain than the Python code, and much less likely to break silently due to changes in the language or third-party libraries.
]]>Polymorphism for beginners2013-12-20T11:15:00+00:00https://roscidus.com/blog/blog/2013/12/20/polymorphism-for-beginnersOCaml makes heavy use of parametric polymorphism (which you may also know as "generics" in other languages).
The OCaml tutorials mention it from time to time, but the information is spread about over many articles and they don't go into much detail.
I'm not a type theorist, just a Python/Java/C programmer who finds this stuff interesting.
I wanted to write this guide while I still remember the things that confused me.
I know several OCaml experts keep an eye on this blog, so hopefully any inaccuracies will be corrected in the comments.
The first thing that confused me was that OCaml tends to use parametric polymorphism where other languages use subtyping ("subtype polymorphism"), so I'll start with a brief summary of subtyping and then show how OCaml uses parametric polymorphism to achieve similar ends.
Note: in the rest of this article I will always use "polymorphism" to mean "parametric polymorphism", which is the way the OCaml documentation uses it.
When you think of object oriented programming, you probably think of the types arranged in a tree. In fact, with multiple-inheritance of interfaces,
the types form a lattice, which is easier to draw than to explain:
On the left, we have some example primitive types, int and unit.
In the middle, we have some GUI object types. widget represents "things that can appear on the screen". button and window are types of widget and a dialog is a type of window. For example, any function that can operate on windows can also operate on dialogs. A button is both a widget and an action. In Java terms, we might write class Button implements Widget, Action.
On the right, we have some variant types (enums). The type "yes or no" is a sub-type of "yes, no or maybe". For example, a function that can format a yes/no/maybe value as a string will also work on the simpler yes/no type.
The rule is that you can always safely cast a type to a super type (going upwards). However, casting in Java and OCaml work differently:
In Java:
Upcasting (converting to a type higher up in the lattice) is automatic and implicit. e.g. in Widget w = new Dialog();
Downcasting requires an explicit cast, and may throw an exception: Dialog d = (Dialog) w.
In OCaml:
Upcasting must be explicit, e.g. let w : widget = (new dialog :> widget).
Downcasting is impossible (types are not recorded at runtime, so it wouldn't be able to check).
Here's an example that might surprise you if you're expecting automatic upcasts:
Error: This expression has type dialog but an expression was expected of type window
The second object type has no method get_response
OCaml won't let you pass a dialog to close_window because it's a dialog, not a window and there are no automatic coercions in OCaml. However, OCaml does know the subtyping relationship and will therefore let you cast it:
123
let()=letd=newdialoginclose_window(d:>window)(* OK *)
Functions also have types and can be cast too, so here's another way to solve this problem:
Here, we upcast close_window to the type dialog -> unit and then pass it a dialog.
By the way, notice that dialog is a subtype of window but dialog -> unit is a super-type of window -> unit. See covariance and contravariance for the details about that.
Top and bottom
The types top and bottom don't seem to exist in OCaml, but I included them for completeness and because they're conceptually interesting and you'll probably run across these terms when reading anything about types.
Top is a super-type of everything, like object in Python (or Object in Java, if you ignore unboxed types). Everything is a top and, therefore, knowing that something is a top tells you nothing at all. Because OCaml doesn't allow downcasting, there's not much you could do with a top in OCaml anyway.
Bottom is a sub-type of everything. A value of type bottom can be used as an int, a widget, a yes/no enum, etc. Needless to say, instances of this type don't actually exist.
Although OCaml doesn't have a bottom type, it achieves the same effect with polymorphism.
For example, the result of these expressions can be used as any type you like:
exit 1 (exits the program)
failwith msg (throws an exception)
let rec loop () = loop () in loop () (infinite loop)
Obj.magic x (unsafe cast; program may segfault if you get it wrong!)
So, this code compiles fine, even though we use bot as an int and as a string:
12345
let()=letbot=exit1inletx:int=botinlety:string=botinPrintf.printf"x = %d, y = %s"xy
Polymorphism
If you treat OCaml like Java then things mostly work fine; you just end up doing a lot of explicit casting. However, where Java uses implicit upcasts, OCaml generally prefers using (parametric) polymorphism.
A polymorphic value doesn't have a single concrete type. Instead, it can take on many different types as needed.
For example, the OCaml function Queue.create can create queues of ints, queues of strings, etc. Its type is unit -> 'a Queue.t, where 'a is a type variable. When you want to use this function, you can use any type (e.g. int or string) as the value of 'a, to get a function that makes queues of ints or queues of strings, as needed.
Note that unlike e.g. C++ templates, using polymorphism does not create any extra code. There is only ever one Queue.create function compiled into your binary, not one for each type you use. The same generic code works for queues of ints and queues of strings.
In Java, upcasting types is implicit, while using polymorphism (generics) requires extra annotations. In OCaml, it's the other way around. Polymorphism is implicit, while upcasting requires annotations. So, in Java:
(Note: I used a made-up linked_list class rather than Queue to keep this example similar to the Java)
This saves a lot of typing, which is good, but it also makes it far harder to understand what's going on.
The way I think of it, OCaml adds type variables at certain points in the code and then uses type inference to work out what they are.
So in this case, we have (note: this is not valid OCaml syntax):
Here, #window means any type with at least the methods of window (not to be confused with w#close, which is a method call, not a type). The syntax is a bit confusing because OCaml hides the type variable by default. If you wanted to declare the type of close_window_poly explicitly, you'd have to make the type variable explicit using as. For comparison, here are the types of the two versions:
Thus the type window closer is the type of functions that close a window, while dialog closer is the type of functions that close a dialog. OCaml will automatically apply the appropriate type at compile time.
As OCaml will infer polymorphic types automatically, we can define and call the function without any type annotations at all:
Here is yet more new syntax! OCaml didn't infer that this requires a #window, only that it requires something with a suitable close method. Also, it couldn't infer that close must return unit, so it left the return type generic as 'a.
The .. indicates more polymorphism, with another hidden type variable. If we wanted to define the type for this function, it would be:
1
type('a,'b)closer2=(<close:'a;..>as'b)->'a
This is the polymorphic type for functions which take objects of type 'b, where 'b includes a close method that returns an 'a, and return an 'a.
For example, the original close_window function has the type (unit, window) closer2.
What all this means is that defining objects and functions without explicit types usually works fine, but if you later try to add type annotations (e.g. by declaring an interface for your module in an .mli file) then you're likely to remove the polymorphism accidentally unless you're careful. If you don't understand what happened, you'll end up doing a load of explicit casting to make things work again.
A good way around this is to use ocamlc -i to generate an initial .mli file with all the inferred types, with all the polymorphism still there.
In another bit of inconsistent syntax, when defining a class type you need to put the type parameter in brackets, but you don't when declaring an object type:
12345678910
(* An object with a "get" method returning an 'a *)type'apoly_type=<get:'a>(* A class type with a "get" method *)classtype['a]poly_class=objectmethodget:'aend
The situation with variants (enums) is similar. Let's start with some non-polymorphic code:
1234567891011121314
letpaint_sky(colour:[`blue|`black])=matchcolourwith|`blue->print_endline"A clear blue sky"|`black->print_endline"A dark black sky"letpaint_balloon(colour:[`blue|`black|`red])=matchcolourwith|`black->print_endline"A black balloon"|`blue->print_endline"A blue balloon"|`red->print_endline"A red balloon"letdraw_scene(colour:[`blue|`black])=paint_skycolour;paint_ballooncolour(* Error *)
Error: This expression has type [ `black | `blue ]
but an expression was expected of type [ `black | `blue | `red ]
The first variant type does not allow tag(s) `red
Again, if you're expecting subtyping behaviour then this is confusing. If we can draw a balloon blue, black or red, why can't we draw it blue or black? Again, we can use an upcast (which is checked by the compiler and is entirely type-safe):
As before, OCaml generally expects you to use polymorphism instead. There's more new syntax for this:
12345
letpaint_balloon(colour:[<`blue|`black|`red])=matchcolourwith|`black->print_endline"A black balloon"|`blue->print_endline"A blue balloon"|`red->print_endline"A red balloon"
Here [< `blue | `black | `red ] means all subtypes of [ `blue | `black | `red ]. The < introduces another hidden type variable. If you wanted to define a type for this function explicitly, you could do it with:
OCaml will automatically infer 'a as [`close | `delete] - a dialog with close and delete responses.
OCaml will force you to handle every response code, so you can't add a button but forget to handle it!
The constraint 'a = [> `close] line forces you to handle the close response in all cases (because the user could always just close the window).
There's a subtle but important distinction between polymorphic types (which can be used to generate many concrete types) and monomorphic types (which OCaml uses to mean a single type that is currently undecided). Monomorphic types only occur while OCaml is still working out the types, so you'll only see them in compiler error messages or in the interactive toplevel. They look like regular type variables but start with an underscore. e.g.
Here, x has a polymorphic type (using 'a). It can be used as an empty list of ints, or as an empty list of strings, or both. Every time you use x, you get to pick a type for it.
y has a monomorphic type (using '_a). It can be used as a mutable container of ints, or of strings, but not both. As soon as OCaml sees it used with a concrete type, it will assign that type for it:
fprintf is a polymorphic function. It takes an output channel, a format string (with a polymorphic type) and values of the appropriate type. p1 retains the polymorphic type.
However, p2, which partially applies the function to stdout, has a monomorphic type ('_a). You could use p2 to print a string, or to print an int, but you couldn't use it twice to do both.
p3, which just makes the format argument explicit, is polymorphic again!
123456789101112
letp1=Printf.fprintfinletp2=Printf.fprintfstdoutinletp3fmt=Printf.fprintfstdoutfmtinp1stdout"%d"3;p1stdout"%s""Hello";(* OK *)p2"%d"3;p2"%s""Hello";(* Error *)p3"%d"3;p3"%s""Hello";(* OK! *)
So, what's going on here?
The OCaml FAQ explains what to do about it (use p3), but doesn't explain why.
As fprintf has a really complicated type, let's switch to a simpler example:
1234567891011121314151617
letlogged_idmsgx=print_endlinemsg;xlet()=leti1=logged_idinleti2=logged_id"called"inleti3x=logged_id"called"xinassert(i1"called"1=1);assert(i1"called""hi"="hi");(* OK *)assert(i21=1);assert(i2"hi"="hi");(* Error! *)assert(i31=1);assert(i3"hi"="hi");(* OK *)
logged_id msg x prints the message and then just returns x.
The polymorphism is lost in i2 because OCaml doesn't know, from the type of logged_id, whether partially applying it will create any mutable state. Consider:
When logged_mem is partially applied, it creates a mutable cell and returns a function that remembers the first value it is called with and always returns that.
The result of logged_mem "called" cannot be polymorphic: it must always be called with the same argument type. Yet logged_mem has the same type as logged_id (string -> 'a -> 'a), so OCaml can't distinguish the two cases.
OCaml assumes that every function call potentially creates mutable state. Therefore, the result of calling a function is never polymorphic. Normally that's what you want, but it can be surprising in the case of partial functions. The solution (i3) is to avoid partial application and do a complete fresh invocation each time.
There are actually some cases where OCaml can turn a monomorphic result type back into a polymorphic one. For example:
OCaml tells us that the identity function id has the type 'a -> 'a. OK. Then I declare another function with the same type, and OCaml tells me its type is int -> int!
OCaml is hiding part of the type! The real type of the identity function is 'a. 'a -> 'a (given 'a, the type is 'a -> 'a). Using this full type, we get the expected error:
The input to the polymorphic type expression (the 'a. bit) can only go at the start of a type expression in OCaml. That means that you can't write a function that takes a polymorphic function as an argument. For example:
So, you may have to wrap some things up in objects or records. If you use this in a method type, make sure you declare the type of the object you're creating. Otherwise, OCaml will infer the wrong type (it will assume that 'a is scoped to the whole object, not a single method):
When you define a module, you can (optionally) write an .mli file giving it a more limited public interface.
In this interface, you can make types abstract, only expose certain functions, etc.
If you include a value with concrete type, the signature must be the same in the module and in the interface.
But when your module contains polymorphic values, you are allowed to limit the polymorphism in the module signature. For example:
Inside the module, close_window will close anything with a close method and return whatever it returns.
But outside the module, close_window can only close subclasses of dialog (and always returns unit).
Cheat-sheet
Some concrete types:
Type expression
Meaning
int list
a list of integers
int -> int
a function that takes an int and returns an int
widget
the concrete type widget exactly
<close : unit>
an object type with a single close method
[`red|`green]
the variant type "red or green"
Some polymorphic types (supplying the type parameter 'a will produce some concrete type):
Type expression
Can produce types for...
'a list
any list of items, each of the same type
'a -> 'a
any function that returns something of the same type as its input
(#widget as 'a)
any type that includes all the methods of widget
(<close : unit; ..> as 'a)
any type with at least a close : unit method
([< `red|`green] as 'a)
any variant with some subset of red and green as options
([> `red|`green] as 'a)
any variant with some superset of red and green as options
You can omit the as 'a bits, unless you need to refer to 'a somewhere else.
Summary
Java uses subtyping by default (automatically), with extra syntax for using generics (polymorphism). OCaml uses polymorphism by default, with extra syntax for using subtypes. Polymorphism is powerful, but can be confusing. If you allow OCaml to infer types, it will infer polymorphic types automatically and everything should work, but you'll want to understand polymorphism when you come to writing module signatures and you need to write out the types.
When the compiler and the interactive OCaml interpreter display polymorphic types, they frequently omit the type variables, which can make learning OCaml more difficult. Polymorphic object types, class types and variants all use different syntax to indicate polymorphism, which can also be confusing.
OCaml uses "monomorphic type" to mean a single (non-polymorphic) type which has not yet been inferred. Monomorphic types occur when you create mutable state or call functions (which may create mutable state internally). This explains why partially applying a function loses its polymorphism.
OCaml does not allow functions that take polymorphic arguments (arguments that remain polymorphic within the function, rather than being resolved to a particular concrete type when the function is called). However, you can work around this using record or object types.
When defining a module's signature (its external API), you can't change concrete types but you can expose less polymorphism in polymorphic types if you want.
]]>Asynchronous Python vs OCaml2013-11-28T13:06:00+00:00https://roscidus.com/blog/blog/2013/11/28/asynchronous-python-vs-ocamlI've now migrated the asynchronous download logic in 0install from Python to OCaml + Lwt.
This post records my experiences using Lwt, plus some comparisons with Python's coroutines.
As usual, the examples will be based on the real-world case of 0install, rather than on idealised text-book examples.
Once all the XML downloads have finished, we select a version of Armagetron (0.2.8.3.2 in my case) and its (single) declared library (version 0.3-pre0.1570 here).
We download these two tar.bz2 files (concurrently) and unpack them to the cache.
Finally, we run (as described in previous posts).
That's the overall process. It's not totally trivial, but in fact some of the steps are complex in themselves. For example, to download a single feed (XML) file:
We download the feed from the given URL.
We check the GPG signature on the feed. If we don't have the GPG key, we must download that next.
Once we've checked that the signature is valid, we need to decide whether to trust it. We download information from the key information server.
Depending on the user's configuration and the key information server's response, we may show a confirmation dialog to the user.
If the primary site is slow, we ask the mirror too. If the primary then succeeds, we cancel the mirror download. If the mirror succeeds first, we use the information we got from it to find more required downloads, but also continue waiting for the primary (which may have more up-to-date information).
If the key information server is slow, we display the dialog to the user anyway, but update the display if the information arrives while the user is pondering.
We never use more than 2 HTTP connections per site at the same time. Further requests are queued.
In other words, there's quite a bit of logic here (and there's still the archive downloads too...). How can we make sure all these operations happen at the right time and that errors are handled correctly?
Solutions
Note that the challenge here is not to use multiple CPUs in parallel to perform some calculation faster, but to schedule and manage multiple concurrent operations. The effects of concurrency will be visible (i.e. the behaviour of the code, such as whether we decide to contact the mirror server or not, depends on how quickly things happen). Therefore, some non-determinism is unavoidable. However, we want to minimise it.
Most languages provide some kind of low-level preemptive multi-threading support, e.g. Python's threading.create, Haskell's forkIO, OCaml's Thread.create, Java's java.lang.Thread and Go's go. In these cases, all threads always run in parallel by default. If two threads access a shared or global variable without appropriate locking, the program will occasionally fail in ways that are hard to reproduce or diagnose.
Of course, these languages provide mutexes, channels, etc to make correct code possible, but this style is unsafe by default. For example, if a multi-threaded program uses some library from multiple threads, and the author of the library was only thinking about single-threaded use, then you likely have a subtle, hard-to-trigger bug.
Let's consider a simplified example: we want to fetch information from the key information server, parse it, and confirm the key with the user (this server says things like "This key belongs to a registered Debian developer").
Within each thread, we might do something like this:
Probably this code will crash if two keys are downloaded close together, because the graphical toolkit library used to show the GUI isn't thread-safe. But there could be similar issues with any code we call (is parse_key_info thread-safe, for example? What about the XML parser it uses? etc).
So how can we avoid these problems? Rust uses its linear types to prevent concurrent access to mutable state, which looks very useful. For other languages, we can use cooperative multi-threading.
The idea here is that instead of running threads in parallel by default and remembering to add locks wherever necessary, we run only one thread at a time, switching between threads only at explicitly marked points.
The two schemes have different failure modes. If you forget the locking in preemptive code, you get subtle bugs. If you forget to allow task switching in a cooperative system, the program may run slower (waiting when it could be getting on with something). For an application like 0install, cooperative makes far more sense. Just making downloads and GUI interaction alone concurrent is really all we need.
Callbacks
The simplest scheme to implement uses callbacks. You tell the system to start an operation, and give it a function to call on success:
Here, we don't know what other functions may be called in the time between us calling download_key_info and the key_info_downloaded callback, but while our code is executing we know that we have complete control. For example, it's not a problem if parse_key_info here only supports single threading.
Callbacks have two major problems:
They make the code messy and hard to read.
They handle exceptions poorly.
Imagine that download_key_info has succeeded. It calls the key_info_downloaded callback. That calls parse_key_info, which throws an exception. The exception gets returned to download_key_info which can't do anything useful with it. Probably, it gets logged and the program hangs, waiting for a call to trust_confirmed that will never happen.
Promises
Promises are a nice alternative to callbacks. When you start an operation, you get a promise for the result. A promise is a place-holder for a result that will arrive in the future. Without any special syntax, using promises might look something like this:
The function promise.when_fulfilled(callback) immediately returns a new promise for the (future) result of the callback.
Internally, a promise initially contains a queue for callbacks. When the promise is (eventually) resolved to a value, the callbacks are all run and the queue is replaced by the value. Attempting to attach any further callbacks just runs them immediately on the value.
Promises have a number of advantages over callbacks. For example, you can store promises of results in lists, pass them to other functions, etc. One particular advantage is exception handling. Consider our previous example:
confirm_key returns a promise for the result of key_info_downloaded.
download_key_info downloads the data successfully, fulfilling data_promise.
key_info_downloaded is called (it was attached to data_promise as a callback).
parse_key_info throws an exception, which is caught by the promise system.
This "breaks" the promise returned by confirm_key.
Whoever was waiting for confirm_key gets notified of the exception.
Notice that instead of propagating uncaught exceptions backwards (to download_key_info), we propagate them forwards (to whoever is waiting for the result). The result is that, as in synchronous programming, an exception is not lost just because someone in the chain doesn't handle it.
A natural next step is to introduce some simpler syntax for this...
OCaml Lwt
OCaml provides a couple of libraries for handling promises - Lwt and Jane Street's Async. I've only looked at Lwt, although they seem fairly similar.
The terminology I introduced above I learnt from E (which also has sophisticated distributed promises). I find the E terms more natural, but here's a conversion table:
E term
Lwt term
Promise
Thread
Fulfilled promise
Returned thread
Broken promise
Failed thread
Unresolved promise
Sleeping thread
Resolver
Waker
In particular, while a Lwt thread is still working to produce a result, the thread is said to be "sleeping", which I find rather awkward. A resolver/waker is the object used by the maker of the promise to resolve it.
Anyway, switching to OCaml and using Lwt without the syntax extensions, we get this:
Here, Lwt.bind promise callback is like our previous promise.when_fulfilled(callback). Again, confirm_key returns a promise (thread) for the final result.
To make things more convenient, you can enable the Lwt syntax extension. This provides thread-aware alternatives to several built-in OCaml keywords:
As if by magic, our asynchronous code now reads like the original synchronous code! lwt is the new way to do Lwt.bind, by analogy with the ordinary let construct. We just have to remember that we give up control between evaluating the right-hand side of the assignment (getting a thread/promise for the data) and assigning the actual data on the left-hand side. For example, another function might change a global variable while we're waiting for the promise to resolve.
The other short-cuts are try_lwt, for_lwt, while_lwt and match_lwt, which do what you'd expect. As a bonus, try_lwt also adds a finally construct and for_lwt adds iteration over sequences - both are missing for the core OCaml language.
There are plenty of functions for combining or creating threads in various ways, including:
let thread, waker = Lwt.wait () explicitly creates a promise and a resolver for it.
Lwt.return value evaluates to a returned thread, which is useful if something needs a thread type but you already have the value.
Lwt.choose threads waits until one of the given threads is ready.
Lwt.join threads returns a single thread that returns when all of the given threads have returned.
Lwt_list.map_s fn items applies fn to each item, waiting for the resulting thread to resolve before doing the next item.
Lwt_list.map_p fn items as above, but runs all the threads in parallel.
Python generators
Python has an unusual solution to the problem, using its generator functions.
A generator is any function which contains a yield. Running such a function gets you an iterator. Each time you ask for a value from the iterator, the generator runs until the next yield to produce the result. It is suspended until the next call. Generators were originally just an easy way to produce sequences, for example:
However, this ability to suspend and resume functions is obviously useful for cooperative multi-threading too and, like many other people, I used them to create a such a system (back in 2004). The version used in the Python version of 0install was designed for Python 2.3, but since then Python has added many useful new features so I'll describe the recent Tulip/asyncio system rather than my own, even though I haven't actually used it much.
The idea is that every time you need to wait, you yield the promise ("future" in Python terminology) you're waiting for. When it's ready, the scheduler will resume your generator function with the result:
Both systems (OCaml Lwt and Python generators) work very well in general. Here are some (slightly simplified) examples from 0install.
Following a recipe
Some downloads require collecting files from several places (e.g. an upstream tarball and some files to patch it with). We want to download the files in parallel, but execute the steps (e.g. unpacking downloads into the target directory) in series. My solution is that each download is a thread that performs the download and then returns a lazy thunk that applies it:
12345678910
(* Start all the downloads in parallel. *)letdownloads=steps|>List.mapdo_stepin(* Now iterate over the steps in series. *)downloads|>Lwt_list.iter_s(fununpack->(* Wait for download *)lwtunpack=unpackin(* Apply download to directory *)Lazy.forceunpack)
Note that we start unpacking as soon as possible; we only wait when the next thing to unpack isn't downloaded yet.
This was my first attempt at a Python version with asyncio:
12345678910
# Start all downloads in paralleldownloads=[do_step(step)forstepinsteps]# Wait for all downloads to completetasks,_=yield fromasyncio.wait(downloads)# Unpack each download in sequencefortaskintasks:unpack=task.result()yield fromunpack()
An interesting difference is that OCaml threads, once started, continue to run by themselves even if no-one is waiting for the result. When the OCaml code is waiting for the first download to complete, the other downloads are still going on. But if we yield from just the first download in Python, only that download makes progress. In the code above, therefore, the Python waits for all downloads to complete before it starts unpacking.
You can fix this by wrapping the future with async:
123456789
# Start all downloads in paralleldownloads=[asyncio.async(do_step(step))forstepinsteps]# Now iterate over the steps in series.fordindownloads:# Wait for downloadunpack=yield fromd# Apply download to directoryyield fromunpack()
Downloading with libcurl
libcurl doesn't provide Lwt support. However, it is thread-safe. We can therefore use the Lwt_preemptive module to run each download in a real operating system thread and get a promise for its completion. In addition, we use a Lwt_pool to keep up to two Curl connections per site (queuing further requests).
When it's our turn to run, we also start a five second timer if the caller wanted to be notified if the download is slow. This is used when downloading the small XML metadata files so the mirror can be tried in parallel (for archives, we only try the mirror if the download actually fails).
The download_in_thread function also needs to send progress notifications to back to Lwt, which it does using Lwt_preemptive.run_in_main.
Update: note that recent versions of ocurl support Lwt directly.
Python provides the ThreadPoolExecutor, which combines pooling and preemptive threading. This makes it a bit harder to start the timer (which should happen cooperatively), so we need to use call_soon_threadsafe, which is like Lwt's run_in_main. Python doesn't seem to provide a way to manage the HTTP connections with the pool - I guess you have to do that manually.
12345678910111213141516171819202122232425262728
classSite:def__init__(self,max_per_site=2):self.pool=futures.ThreadPoolExecutor(max_per_site)defschedule_download(self,channel,url,if_slow=None):thread_ready=asyncio.Future()deftimer():# Wait for an executor to be ready...yield fromthread_ready# Wait until 5 seconds into the downloadyield fromasyncio.sleep(5)# Notify that the download is slowif_slow()defrun_in_thread():connection=...ifif_slow:loop.call_soon_threadsafe(thread_ready.set_result,True)download_in_thread(connection,channel,url)download=loop.run_in_executor(self.pool,run_in_thread)t=asyncio.async(timer())try:yield fromdownloadfinally:t.cancel()
Error handling in key look-ups
Lwt does have a gotcha for error handling. Consider this code:
123456789
letconfirm_keyfeed=lwtdata=trydownload_key_infofeed.signaturewithFailuremsg->log_warning"Failed to download key info: %s"msg;Lwt.return[]inletinfo=parse_key_infodatain
If querying the key info server fails, we want to log the error but continue with the confirmation, just with an empty list of hints.
Something I really dislike is code that looks right, compiles without warnings, works when you test it, and then fails in the field. Unfortunately, this code does just that. Even if you unit-test the error case!
The bug occurs because we accidentally used try rather than try_lwt. download_key_info successfully returns a promise for the information, so the with clause isn't triggered and we exit the try block. Then Lwt waits for the promise to resolve so it can set data.
When unit-testing, you'll probably raise the test exception immediately and so the with block does get called.
By contrast, Python's generators have no such problems:
123456789
defconfirm_key(feed):try:data=yield fromdownload_key_info(feed.sig)exceptExceptionasex:logging.warning("Failed to download key info: %s",ex)data=[]info=parse_key_info(data)ok=yield fromconfirm_with_gui(feed,info)ifok:...
The other Lwt constructs don't have this problem because the type-system will detect the error (e.g. if you use match instead of match_lwt), but with try and try_lwt the type signatures are the same.
Failing over to a mirror
We start downloading each XML feed from its primary site, but trigger a timeout task if it takes too long.
The timeout starts a download from the mirror, which happens in parallel with the original download attempt.
We don't want to start the timer immediately because the download might get queued due to the rate limiting code, so we just pass the if_slow trigger to the download system (see above).
Because we need to report intermediate results (e.g. we have downloaded a possibly-slightly-old version from the mirror), we return a pair of the new result and a promise for the next update (or None if this is the last). In a similar way, we return errors as a pair of the current error (e.g. "mirror failed") and a promise for the other result.
Lwt.choose selects the result of the first task from a list to resolve. When choosing between the primary and the mirror however we ignore the result and test explicitly, because we need to know which one it was.
lettimeout_task,timeout_waker=Lwt.wait()inletif_slow()=Lwt.wakeuptimeout_waker`timeoutinletprimary=do_primary_download~if_slowfeedin(* Download just the upstream feed, unless it takes too long... *)match_lwtLwt.choose[primary;timeout_task]with|`okresult->`update(result,None)|>Lwt.return|`problemmsg->letmirror=do_mirror_download()in`problem(msg,Some(wait_for_mirrormirror))|>Lwt.return|`timeout->(* OK, maybe it's just being slow... *)log_info"Feed download from %s is taking a long time."feed_url;(* Start downloading from mirror... *)letmirror=do_mirror_download()in(* Wait for a result from either *)lwt_=Lwt.choose[primary;mirror]inmatchLwt.stateprimarywith|Lwt.Failmsg->raisemsg|Lwt.Sleep->(* The mirror finished first *)beginmatch_lwtmirrorwith|`okresult->log_info"Mirror succeeded, but will continue to wait for primary";`update(result,Some(wait_for_primaryprimary))|>Lwt.return|`problemmsg->log_info"Mirror download failed: %s"msg;wait_for_primaryprimaryend|Lwt.Returnv->(* The primary returned first *)matchvwith|`okresult->Lwt.cancelmirror;`update(result,None)>Lwt.return|`problemmsg->`problem(msg,Some(wait_for_mirrormirror))|>Lwt.return
I'm too lazy to translate this into modern Python, but I think it's clear that a direct translation would be easy enough.
The main problem would be losing OCaml's type checking, which ensures that we handle all the possible error conditions. I simplified the outcomes into just ok and problem above, but in the real code we also distinguish replay_attack, aborted_by_user and no_trusted_keys, and handle them differently. For example, a "replay attack" from the mirror (where the mirror gives us a version older than one we've already seen) is ignored, whereas it's reported if it comes from the primary.
Switches
The Lwt_switch module provides a way to group a set of activities together so you can stop them all at once.
You create a switch and pass it to all the various setup functions you call.
When you're done, call Lwt_switch.turn_off to kill everything.
For example, each download goes to a temporary file. To ensure they're all deleted afterwards:
Then it doesn't matter whether we download successfully, raise an exception inside of download, raise an exception after calling download, etc; the file always gets deleted.
Perhaps this is bad API design and I shouldn't rely on download's caller to clean up the file if download fails, but it does seem convenient. To avoid mistakes, I used ~switch to force the caller to pass a switch instead of the more normal ?switch (where use of a switch is optional).
Parallel tasks
Regular OCaml lets you assign multiple variables at once using and, so that all the expressions are evaluated in a context where none of them is bound. For example, to switch the names of two variables:
123
letx=yandy=xin...
Lwt uses this syntax with lwt to create multiple tasks in parallel and then wait for all of them. For example, when we run a command we may want to collect the standard output and standard error separately but in parallel (if we did them in series, the process might get stuck trying to write its stderr while we were trying to read its stdout, if the Unix pipe gets full). With this syntax, we can get the two strings with just:
0install needs to manage several fairly complex concurrent download activities, including error handling, timeouts and mirrors. Cooperative multi-threading allows us to support this easily with a low risk of race conditions.
Python and OCaml both provide powerful and easy-to-use cooperative threading support. I think Python's generators are slightly easier to understand for beginners, but I find both quite easy to use. I find Lwt's terminology a little confusing, but thinking of threads as promises seems to help. Both systems handle exceptions sensibly.
Comparing Python and OCaml code, they're pretty similar. Both make it easy to start and manage cooperative threads, to interact with pools of preemptively threaded code (e.g. libcurl) and to handle errors.
Using OCaml variants for network errors rather than exceptions is useful; this ensures that all such errors are handled. If you rely on exceptions instead then things mostly work, but watch out for using try rather than try_lwt.
The old 0install Python code used a custom system built on top of Python's generators, but Python's new asyncio module provides a standardised replacement (asyncio will be added to the standard library in Python 3.4). Lwt has been around for a while and is already available from Linux distribution repositories.
Lwt also integrates with several other libraries, including GTK, OBus (D-BUS bindings) and React. Lwt seems very reliable. The only bug I found in Lwt so far was a pipe read failure on Windows, which they quickly fixed.
]]>OCaml tips2013-10-13T14:22:00+00:00https://roscidus.com/blog/blog/2013/10/13/ocaml-tipsIn today's "thing's I've learnt about OCaml" I look back at my first OCaml code, and think about how I'd write it differently now.
Looking back at my code, the most obvious "this is beginner code" clue is the use of ;; everywhere. The OCaml tutorial gives a list of complicated rules for when to use ;;, but in fact it's very simple:
Never use top-level expressions in an OCaml program.
Never use ;; (except when tracking down syntax errors).
If you want to run some code at startup (e.g. your "main" function), just put it inside a let () = ... block. That way you'll also get a compile-time error if you miss an argument. I don't know why OCaml even allows top-level expressions. e.g.
123456
(* Bad - mistake goes undetected and you need ';;' *)Printf.printf"Hello %s";;(* Good - compiler spots missing argument *)let()=Printf.printf"Hello %s"
In a similar way, I was a bit over cautious about adding parenthesis around expressions. For example, I had Str.regexp ("...") and match (...) with. They're not needed in most cases.
Warnings
Always compile with warnings on. I don't know why this isn't the default. Use -w A to enable all warnings.
I actually use -w A-4, which disables the warning when you use a default match case. Default match cases should be avoided when possible, but if you've gone to the trouble of adding one then you probably needed it.
Exhaustive matching
One of the great strengths of OCaml (which I missed at first) is that it always makes you handle every possible case. Providing a catch-all case defeats this check. In my initial code, I needed to process a list of bindings. First, all the environment bindings, then all the executable ones. I made a do_env_binding function which applied environment bindings and ignored all others:
I did the same for executable bindings. Then I applied them all like this:
12345
(* Do <environment> bindings *)List.iter(do_env_bindingenvimpls)bindings;(* Do <executable-in-*> bindings *)List.iter(do_exec_bindingconfigenvimpls)bindings;
I now think this is bad style, because if a new binding type is added no compiler warning will appear. It's better to have the functions accept only the single kind of binding they process. Then the code that calls them separates out the two types of binding. If a new type is added later, the code will issue a warning about an unmatched case:
The recently released OCaml 4.01 adds two new built-in operators, @@ and |>. They're very simple, and you can define them yourself on older versions like this:
12
let(@@)fnx=fnxlet(|>)xfn=fnx
They both simply call a function with an argument. For example print @@ "Hello" is the same as print "Hello". However, they are very low precedence, which means you can use them to avoid parenthesis. For example, these two lines are equivalent (we load a file, parse it as XML, parse the resulting document as a 0install selections document and then execute the selections):
The advantage here is that when you read an (, you have to scan along the rest of the line counting brackets to find the matching one. When you see @@, you know that the rest of the expression is a single argument to the previous function.
The pipe operator |> is similar, but the function and argument go the other way around. These lines are equivalent:
Intuitively, the result of each segment of the pipeline becomes the last argument to the next segment.
At first, I couldn't see any reason for preferring one or the other, so I decided to use just @@ initially (which was most familiar, being the same as Haskell's $ operator). That was a mistake. |> is the more useful of the two.
In the original post, I complained that you had to write loops backwards, giving the loop body first and then the list to be looped-over. With |>, that problem is solved:
Using the pipe operator eliminates the mismatch between the desire to make the function the last argument and OCaml's common (but not universal) convention of putting the data structure last. It can also make things look more object-oriented, by putting the object first. Consider this code for setting an attribute on an XML element:
1
set_attributeabc
Which is the element, and which are the name and value? Written this way, it's hopefully obvious that c is the element:
1
c|>set_attributeab
Sequences become clearer. For example, consider adding two items to a collection in order:
12345678
(* Using () *)letitems=Collection.add"two"(Collection.add"one"items)(* Using |> *)letitems=items|>Collection.add"one"|>Collection.add"two"
I was even considering changing the order of the arguments to my starts_with function to make it work with pipe. Currently, we have:
1
ifstarts_withabthen...
But does it check that a starts with b or the other way around? They're both strings, so type checking won't catch errors either. Reversing the arguments and using pipe, it would be clear:
1
ifa|>starts_withbthen...
However, extlib's version uses the original order, so I decided not to change it. Also, I used it in a lot of places and I couldn't find a semantic patching tool to change them all automatically (like Go's gofmt -r or C's Coccinelle - which, interestingly, is written in OCaml).
Handling option types
I noted the lack of a null coalescing operator in my original code. I've now made some helpers for handling option types (I don't know if OCaml programmers have standard names for these). I find them neater than using match statements.
The first I named |?. It's used to get the value out of an option, or generate some default if it's missing. It's defined like this:
Using OCaml's built-in lazy syntax makes this a bit nicer than having to define an anonymous function each time you use it. It's used like this:
1234567891011121314
(* Use config.dir, or $HOME if it's not set *)letdir=matchconfig.dirwith|None->Sys.getenv"HOME"|Somedir->dirin(* Using |? *)letdir=config.dir|?lazy(Sys.getenv"HOME")in(* Guess the MIME type if it's not set on the element *)letmime_type=mime_type|?lazy(Archive.type_from_urlurl)in(* Abort if not set *)letitem=lookupname|?lazy(raise_safe"Item '%s' not found"name)
The only slight issue I have is that if you forget the lazy when raising an exception then you don't get a compile-time error. It just throws the exception in all cases. However, you should spot this problem quickly when you test it.
Another common task is to execute some code with the option's value only if it's set. I defined if_some for this. It takes a function to call with the value, but partial application means you usually don't need to define one explicitly. For example, to stop a timer if you have one:
12345678
(* Normal method *)let()=matchtimeoutwith|None->()|Sometimeout->Lwt_timeout.stoptimeoutin(* Using if_some *)timeout|>if_someLwt_timeout.stop;
Finally, there's a pipe_some, which is the same except that it maps None -> None rather than None -> ().
Conclusions
After spending a few months writing OCaml, my coding style hasn't actually changed much since my first attempts right after reading the tutorials. I'm not sure whether this is good or bad. Like Python, there is a one-obvious-way-to-do-it feeling to OCaml, unlike Haskell and Perl, which somehow seem to encourage clever-but-incomprehensible solutions. When I've read other people's OCaml code (e.g. Lwt), I haven't found anything new or hard to read.
The main changes have been cosmetic: the removal of ;;, fewer brackets, and the |> operator to make the code tidier, plus some common helper functions. I'm also finding more ways to make the type system do more of the work: e.g. avoiding catch-all match cases and using Polymorphic Variants.
The most useful functions I've added (some borrowed from other people) are:
|? for handling None values (see above)
if_some and pipe_some (see above)
finally_do to work around the lack of a try...finally syntax in OCaml
filter_map (apply a function to each item in a list, filtering out any None replies)
starts_with (as in Python)
abspath and realpath (to resolve pathnames; translated from the Python standard library code)
If anyone else wants my realpath, it's in Support.Utils.
What other useful tips or utilities do people have?
]]>Experiences with OCaml objects2013-09-28T11:52:00+00:00https://roscidus.com/blog/blog/2013/09/28/ocaml-objectsI'm now written 15,000 lines of OCaml while migrating 0install to the language. So here's another "things I've learned" post...
The official objects tutorial offers a good introduction to using objects in OCaml, but it doesn't explain a number of important issues. Chapter 3 of the OCaml manual does explain everything, but I had to read it a few times to get it.
The manual notes that:
the relation between object, class and type in OCaml is very different from that in mainstream object-oriented languages like Java or C++, so that you should not assume that similar keywords mean the same thing.
Good advice. Coming from a Python/Java background, here are some surprising things about objects in OCaml:
An object's type is not the same as its class.
A class A can inherit from B without being a subclass.
A class A can be a subclass of B without inheriting from it.
You don't need to use classes to create objects.
I'm going to try explaining things in the opposite order to the official tutorial, starting with objects and adding classes later, as I think it's clearer that way. Classes introduce a number of complications which are not present without them.
In Python, you create a single object by first defining a class and then creating an instance of it. In OCaml, you can just create an instance directly (Java can do this with anonymous classes).
For example, 0install code that interacts with the system (e.g. getting the current time, reading files, etc) does so by calling methods on a system object. For unit-testing, we pass mock system objects, while when running normally we pass a singleton object which interacts with the real system. We can define the singleton like this (simplified):
Note that the exit method is calling the built-in exit function, not recursively calling itself. Calling a method has to be explicit, as in Python.
To call a method, OCaml uses # rather than .:
1
Printf.printf"It is now %f\n"real_system#time;
Initially, I defined time as method time () = Unix.time (), but this isn't necessary. Unlike for regular function definitions, the body of a method is evaluated each time it is called, even if it takes no arguments, not once when the object is created.
Object types
OCaml will automatically infer the type of real_system as:
< exit : int -> 'a; time : float >
(note: exit never returns, so it can be used anywhere, which is why it gets the generic return type 'a)
This is not a class (nor even a class type). It's just a type.
Any object providing these two methods will be compatible with real_system. There is no need to declare that you implement the interface.
You also don't need to declare the type when using the object. For example:
Error: This expression has type < exit : ?code:int -> string -> 'a >
but an expression was expected of type < exit : string -> 'b; .. >
Types for method exit are incompatible
In a similar way, using labelled arguments will fail unless you use them in the same order everywhere. To avoid these problems, it seems best to define the type explicitly:
As in Python, self is explicit. However, it's attached to the object rather than to each method, and you can leave it out if you don't need it. I added it here in order to constrain its type to system. I used _self rather than self to avoid the compiler warning about unused variables.
A puzzle
It seems to me that some object types can be inferred but not defined. Consider this interactive session:
I'm not sure what causes these problems. You can, however, use the cast operator (:>) to convert to the required type if it happens.
Update: x does have a type, but it's polymorphic: 'a lengther. OCaml has cleverly noticed that I don't actually store any 'a values in the object, so it allows this single object to handle multiple types. For most objects, this will not be the case (for example, a mutable stack object could be an int stack or a string stack, but not both). For details, see my later post Polymorphism for beginners.
Creating many objects
Usually, you'll want to create many objects, sharing the same code. For example, when one 0install program depends on another, it may specify restrictions on the acceptable versions. Here's how we make version_restriction objects to represent this (simplified):
Notice the test variable, which is like a private field in Java. It cannot be used from anywhere else, simply because it is not in scope. You can define functions here in the same way. OCaml does not allow accessing an object's fields from outside (e.g. restriction.expr in Java or Python), but you can make a field readable by writing a trivial getter for it. e.g. to expose expr:
However, OCaml does not store the type information at runtime, so you cannot cast in the other direction. That is, given a printable object, you cannot find out whether it really has a meets_restriction method. This doesn't seem to be a problem, since the places where I wanted to check for several possibilities were better handled with variants.
Classes
OK, so we can create objects with public methods, constructors, internal functions and state, and define types (interfaces). So what are classes for? The key seems to be this: Classes are all about (implementation) inheritance. If you don't need inheritance, then you don't need classes.
Changing make_version_restriction to a class would look like this:
We just changed the let to class and make_version_restriction to new version_restriction (in fact, there are some syntax restrictions when defining classes: a class body is a series of let declarations followed by an object, whereas a function body is an arbitrary expression).
When you define a class (e.g. version_restriction), OCaml automatically defines three other things:
a class type (version_restriction)
an object type (also called version_restriction), defining the public methods
an object type for subtypes (#version_restriction)
The object type just defines the public methods provided by instances of the class. The class type also defines the API the class provides to its subclasses. Confusingly, OCaml calls this the "private" API (Java uses the term "protected" for this).
You can use method private to declare a method that is only available to subclasses, and val to declare fields (fields are always private). Methods can be declared as virtual if they must be defined in subclasses (this is like abstract in Java). A class with virtual methods must itself be virtual.
Using inheritance
To inherit from a class, use:
123
objectinheritsuperclassargsassuperend
Here's an example from 0install: a distribution object provides access to the platform-specific package manager, allowing 0install to query the native package database for additional candidates. Each distribution subclasses the base class. Here's my first (wrong) attempt to do this with classes (simplified):
The Python code in 0install maintains a cache of the dpkg database for quick access. The OCaml can query this cache, but can't (currently) update it, so if the cache is out-of-date then it must fall back to the Python code.
This code doesn't compile:
("super" in "super#is_installed package")
Error: This expression has no method is_installed
If you're used to other languages, you may have assumed, like me, that class python_fallback_distribution : distribution means
"python_fallback_distribution extends distribution". It doesn't. It means that the class type of python_fallback_distribution is identical to that of distribution. Therefore, python_distribution can't see the is_installed method, since it was virtual in distribution.
The solution here is simple: remove the : distribution bits.
In fact, we don't need a class for debian_distribution at all: a simple object would do (we can still inherit, we just can't let others inherit from us):
Notice that we declare the type of the object as #distribution, ensuring that this is a subtype of it. For a plain object (like this), we could also use just distribution, which would prevent us from adding any extra methods. When defining a class, you'd get an error if you did that, because restricting the type to distribution would prevent subclassing in some cases (e.g. adding additional methods). For some reason, if you don't declare a type at all then it defaults to something strange that sometimes causes confusing errors at compile time.
Problems with classes
Using classes causes a few extra problems. For example, this object
However, if you try to turn it into a class, you get:
Error: Some type variables are unbound in this type:
class nat_classifier :
object method classify : int -> [> `positive | `zero ] end
The method classify has type int -> ([> `positive | `zero ] as 'a)
where 'a is unbound
OCaml can see that this method only returns `positive` or `zero`, but that may be too restrictive for subclasses. e.g. an `int_classifier` subclass may wish to return `positive`, `negative` or `zero`. So you'll need to declare the types explicitly in these cases.
Update: Sorry, the above is nonsense (as pointed out in the comments). You'll get the same error if you just try to name the type:
# type t = < classify : int -> [> `positive | `zero ] >;;
Error: A type variable is unbound in this type declaration.
In method classify: int -> ([> `positive | `zero ] as 'a)
the variable 'a is unbound
The type of the plain object is polymorphic (because it contains a >, which indicates a (hidden) type variable). This allows it to adapt in certain ways. For example: if you had some code that expected to be given the type [`positive | `negative | `zero] then our object would be compatible with that too (although it would never actually return negative, of course).
To fix it, we can either specify a closed (non-polymorphic) return type:
(i.e. it passes the open file to the given callback function and returns whatever that returns)
But if you try to use a class, you'll get:
Error: Some type variables are unbound in this type:
class file : object method read_with : (in_channel -> 'a) -> 'a end
The method read_with has type (in_channel -> 'a) -> 'a where 'a
is unbound
Again, you need to give the type explicitly in this case. Here, we probably want to use "universal quantification" to make the class non-polymorphic:
Indeed, the OCaml standard library doesn't appear to use objects at all.
However, they can be quite useful. In 0install, we use them to abstract over different kinds of restriction (version restrictions, OS restrictions, distribution restrictions), different platform package managers (Arch, Debian, OS X, Windows, etc), and to control access to the system, using real_system, dryrun_system (which wraps a system, forwarding read operations but just logging writes, for --dry-run mode), and fake_system for unit-testing.
The main things to remember are that:
You often need to declare types explicitly, as the automatic type inference often can't infer the type, or infers an incompatible type.
Classes and class types are about inheritance (the API exposed to subclasses), while object types are about the public API.
There are still some things I'm not sure about:
Is there any disadvantage to using plain objects rather than classes (when inheritance isn't needed)? Is it considered good style to use classes everywhere, as the tutorial does?
When declaring argument types, whether to use (system:system) (I need a system object) or (system:#system) (the type of objects from subclasses of system). In general, I don't understand why we need separate types for these concepts.
 Dependency graph for this blog
Dependency graph for this blog Initial reference graph
Initial reference graph After reading the code of main
After reading the code of main Updated graph showing TLS
Updated graph showing TLS









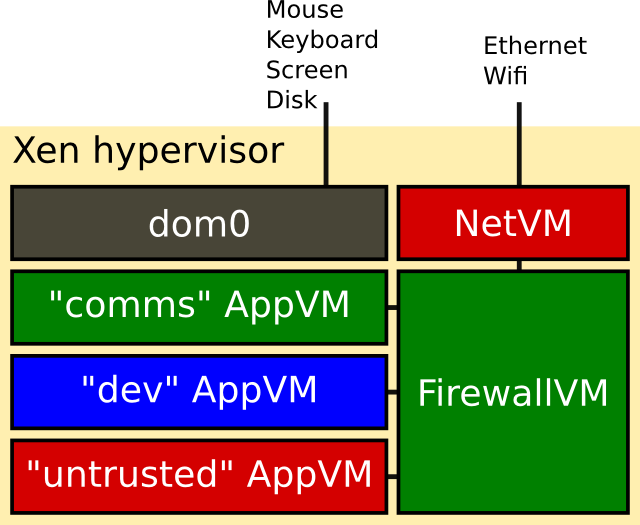
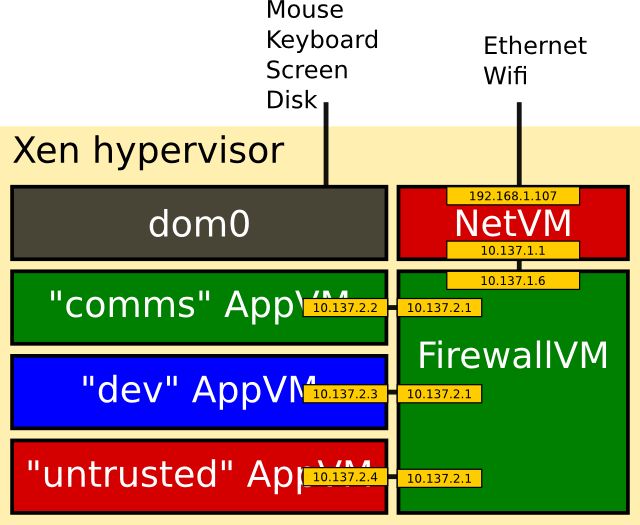
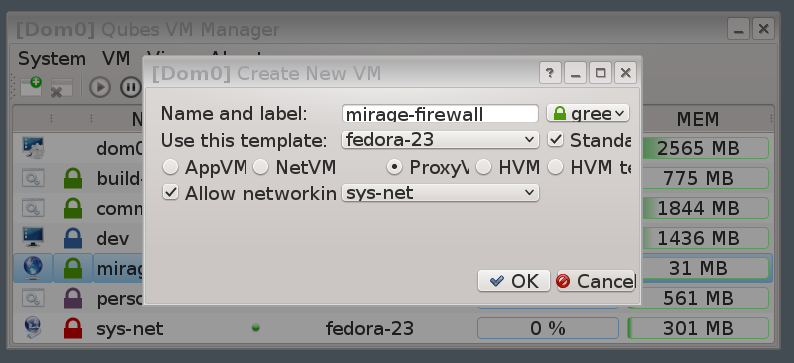
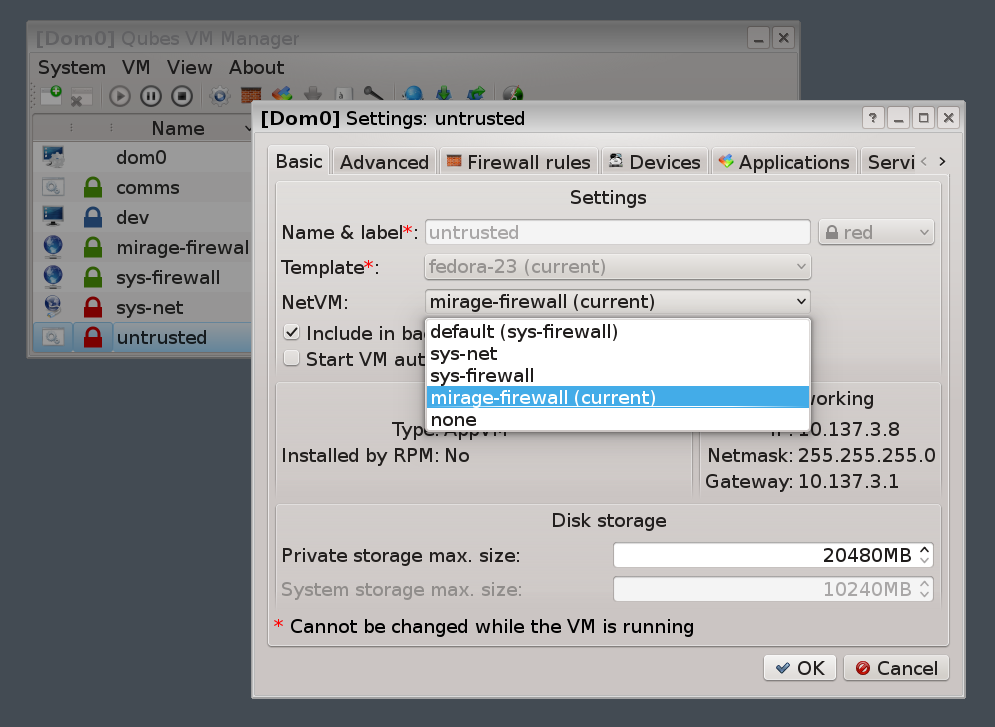
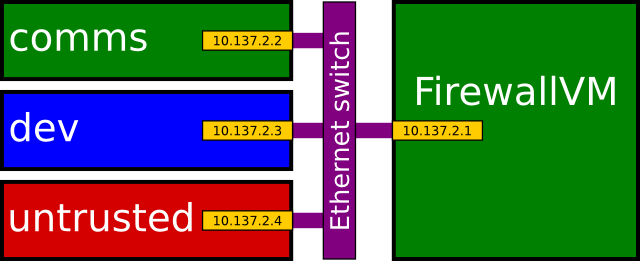
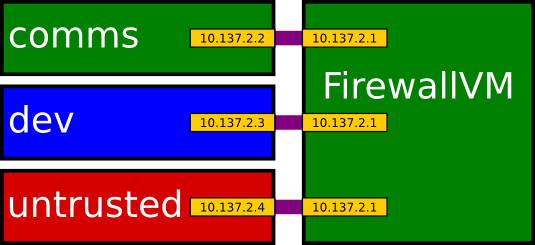

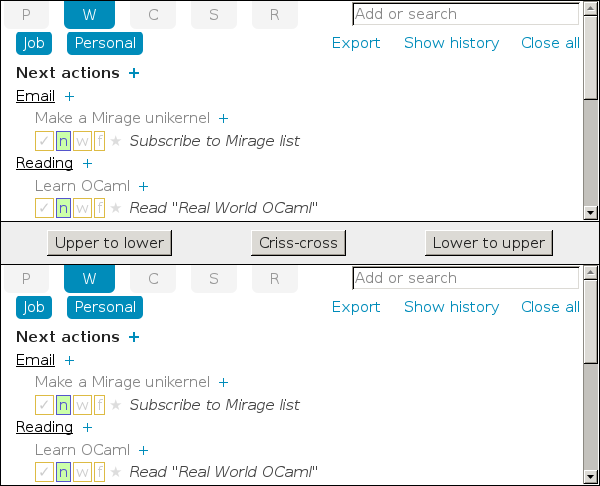
 Beside each action you will see some toggles showing its state:
The tick means done,
"n" is a next action (something you could start now),
"w" means waiting-for (something you can't start now),
"f" means future (something you don't want to think about yet).
The star is for whatever you want.
Repeating actions can't be completed, so for those the tick box will be blank.
Beside each action you will see some toggles showing its state:
The tick means done,
"n" is a next action (something you could start now),
"w" means waiting-for (something you can't start now),
"f" means future (something you don't want to think about yet).
The star is for whatever you want.
Repeating actions can't be completed, so for those the tick box will be blank. You can associate any area, project or action with a contact, which provides a quick way to find all the things you need to discuss with someone when you meet them.
If an action is being performed by someone else, you can also mark it as waiting for them.
It will then appear on the
You can associate any area, project or action with a contact, which provides a quick way to find all the things you need to discuss with someone when you meet them.
If an action is being performed by someone else, you can also mark it as waiting for them.
It will then appear on the  Assigning a context to an action is an important check that the action isn't too vague.
Your eye will tend to glide over vague actions like "Sort out car"; choosing a context "Phone" (garage) or "Shopping" (buy tools) forces you to clarify things.
Assigning a context to an action is an important check that the action isn't too vague.
Your eye will tend to glide over vague actions like "Sort out car"; choosing a context "Phone" (garage) or "Shopping" (buy tools) forces you to clarify things.




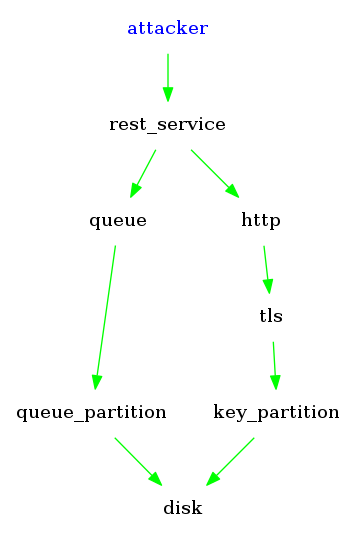
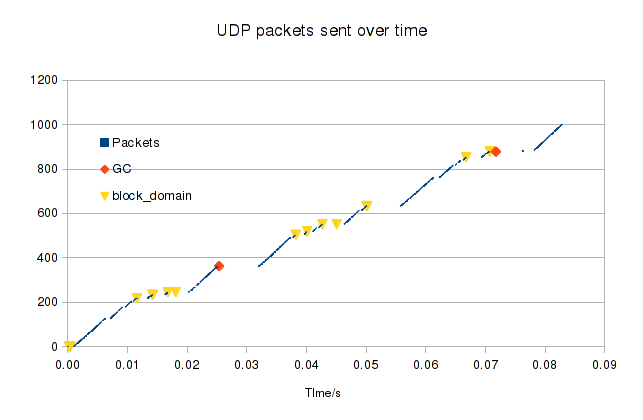
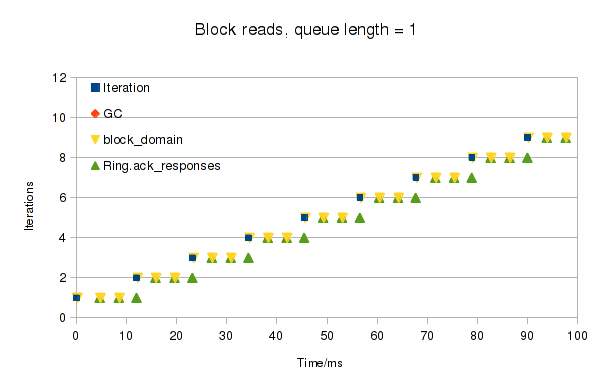

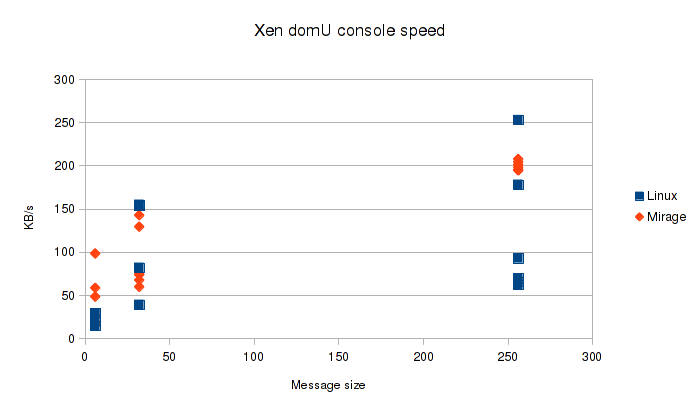
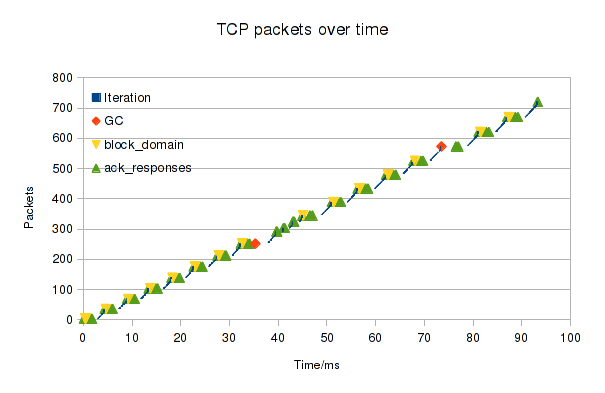
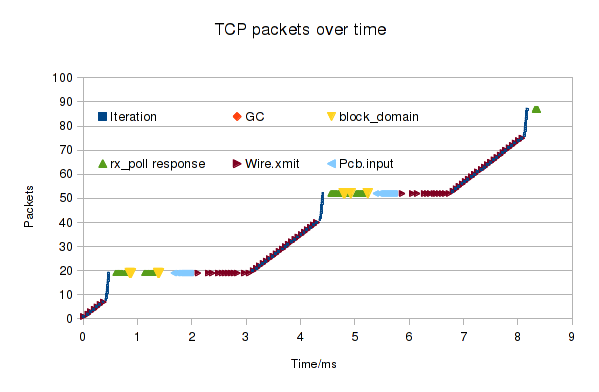
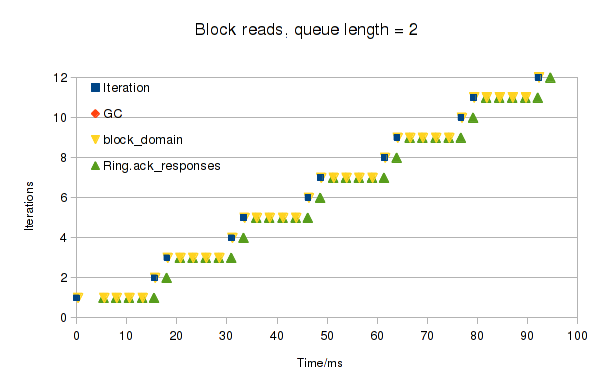
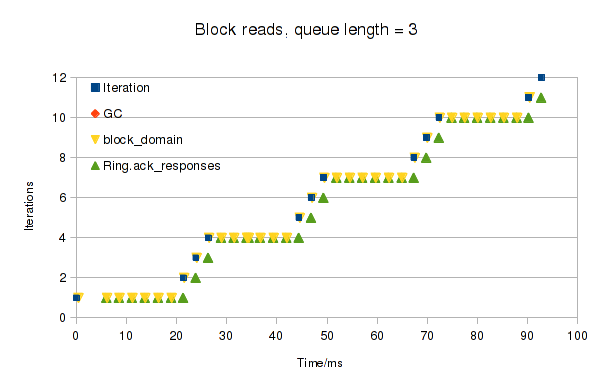
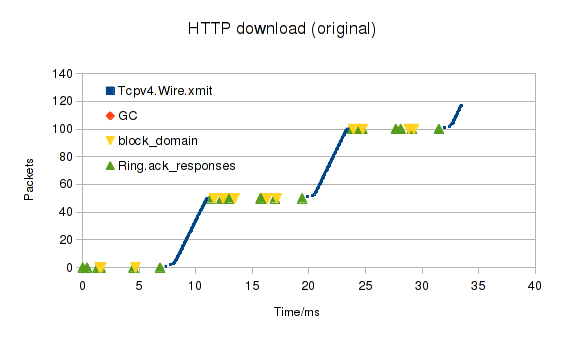
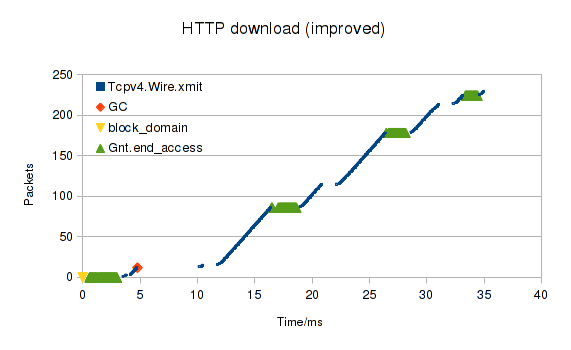
.")







.")