After converting 0install to OCaml, I've been looking at using more of OCaml's features to further clean up the APIs. In this post, I describe how using OCaml functors has made 0install's dependency solver easier to understand and more flexible.
( this post also appeared on Hacker News and Reddit )
Table of Contents
- Introduction
- The current solver code
- Discovering the interface
- Comparison with Java
- Diagnostics
- Selections
- Summary
Introduction
To run a program you need to pick a version of it to use, as well as compatible versions of all its dependencies. For example, if you wanted 0install to select a suitable set of components to run SAM, you could do it like this:
$ 0install select http://www.serscis.eu/0install/serscis-access-modeller
- URI: http://www.serscis.eu/0install/serscis-access-modeller
Version: 0.16
Path: (not cached)
- URI: http://repo.roscidus.com/utils/graphviz
Version: 2.38.0-2
Path: (package:arch:graphviz:2.38.0-2:x86_64)
- URI: http://repo.roscidus.com/java/swt
Version: 3.6.1
Path: (not cached)
- URI: http://repo.roscidus.com/java/iris
Version: 0.6.0
Path: (not cached)
- URI: http://repo.roscidus.com/java/openjdk-jre
Version: 7.65-2.5.2-1
Path: (package:arch:jre7-openjdk:7.65-2.5.2-1:x86_64)
Here, the solver selected SAM version 0.16, along with its dependencies. GraphViz 2.38.0 and OpenJDK-JRE 7.65 are already installed from my distribution repository, while SWT 3.6.1 and IRIS 0.6.0 need to be downloaded (e.g. using 0install download).
This post is about the code that decides which versions to use, and my attempts to make it easier to understand using OCaml functors and abstraction. For a gentle introduction to functors, see Real World OCaml: Chapter 9. Functors.
How dependency solvers work
( This section isn't about functors, but it's quite interesting background. You can skip it if you prefer. )
Let's say I want to run foo, a graphical Java application.
There are three versions available:
foo1(stable)- requires Java 6..!7 (at least version 6, but before version 7)
foo2(stable)- requires Java 6.. (at least version 6)
- requires SWT
foo3(testing)- requires Java 7..
- requires SWT
Let's imagine we have some candidates for Java and SWT too:
- Java:
java6_32bit,java6_64bit,java7_64bit,java8_64bit - SWT:
swt35_32bit,swt35_64bit,swt36_32bit,swt36_64bit
My computer can run 32- and 64-bit binaries, so we need to consider both.
We start by generating a set of boolean constraints defining the necessary and sufficient conditions for a set of valid selections.
Each candidate becomes one variable, with true meaning it will be used and false that it won't (following the approach in OPIUM).
For example, we don't want to select more than one version of each component, so the following must all be true:
1 2 3 | |
We must select some version of foo itself, since that's our goal:
1
| |
If we select foo1, we must select one of the Java 6 candidates.
Another way to say this is that we must either not select foo1 or, if we do, we must select a compatible Java version:
1 2 3 4 5 6 | |
SWT doesn't work with Java 8 (in this imaginary example):
1 2 3 4 | |
Finally, although we can use 32 bit or 64 bit programs, we can't mix different types within a single program:
1 2 3 4 5 6 7 8 9 | |
Once we have all the equations, we throw them at a standard SAT solver to get a set of valid versions. 0install's SAT solver is based on the MiniSat algorithm. The basic algorithm, DPLL, works like this:
- The SAT solver simplifies the problem by looking for clauses with only a single variable. If it finds any, it knows the value of that variable and can simplify the other clauses.
- When no further simplification is possible, it asks its caller to pick a variable to try.
Here, we might try
foo2=true, for example. It then goes back to step 1 to simplify again and so on, until it has either a solution or a conflict. If a variable assignment leads to a conflict, then we go back and try it the other way (e.g.foo2=false).
In the above example, the process would be:
- No initial simplification is possible.
- Try
foo2=true. - This immediately leads to
foo1=falseandfoo3=false. - Now we try
java8_64bit=true. - This immediately removes the other versions of Java from consideration.
- It also immediately leads to
x64=true, which eliminates all the 32-bit binaries. - It also eliminates all versions of SWT.
foo2depends on SWT, so eliminating all versions leads tofoo2=false, which is a conflict because we already set it totrue.
MiniSat, unlike basic DPLL, doesn't just backtrack when it gets a conflict.
It also works backwards from the conflicting clause to find a small set of variables that are sufficient to cause the conflict.
In this case, we find that foo2 and java8_64bit implies conflict.
To avoid the conflict, we must make sure that at least one of these is false, and we can do this by adding a new clause:
1
| |
In this example, this has the same effect as simple backtracking, but if we'd chosen other variables between these two then learning the general rule could save us from exploring many other dead-ends.
We now try with java7_64bit=true and then swt36_64bit=true, which leads to a solution.
Optimising the result
The above process will always find some valid solution if one exists, but we generally want an "optimal" solution (e.g. preferring newer versions). There are several ways to do this.
In his talk at OCaml 2014, Using Preferences to Tame your Package Manager, Roberto Di Cosmo explained how their tools allow you to specify a function to be optimised (e.g. -count(removed),-count(changed) to minimise the number of packages to be removed or changed).
When you have a global set of package versions (as in OPAM, Debian, etc) this is very useful, because the package manager needs to find solution that balances the needs of all installed programs.
0install has an interesting advantage here.
We can install multiple versions of libraries in parallel, and we don't allow one program to influence another program's choices.
If we run another SWT application, bar, we'll probably pick the same SWT version (bar will probably also prefer the latest stable 64-bit version) and so foo and bar will share the copy.
But if we run a non-SWT Java application, we are free to pick a better version of Java (e.g. Java 8) just for that program.
This means that we don't need to find a compromise solution for multiple programs.
When running foo, the version of foo itself is far more important than the versions of the libraries it uses.
We therefore define the "optimal" solution as the one optimising first the version of the main program, then the version of its first dependency and so on.
This means that:
- The behaviour is predictable and easy to explain.
- The behaviour is stable (small changes to libraries deep in the tree have little effect).
- Programs can rank their dependencies by importance, because earlier dependencies are optimised first.
- If
foo2is the best version for our policy (e.g. "prefer latest stable version") then every solution withfoo2=trueis better than every solution without. If we direct the solver to tryfoo2=trueand get a solution, there's no point considering thefoo2=falsecases. This means that the first solution we find will always be optimal, which is very fast!
The current solver code
The existing code is made up of several components:
 Arrows indicate "uses" relationship.
Arrows indicate "uses" relationship.
- SAT Solver
- Implements the SAT solver itself (if you want to use this code in your own projects, Simon Cruanes has made a standalone version at https://github.com/c-cube/sat, which has some additional features and optimisations).
- Solver
- Fetches the candidate versions for each interface URI (equivalent to the package name in other systems) and builds up the SAT problem, then uses the SAT solver to solve it. It directs the SAT solver in the direction of the optimal solution when there is a choice, as explained above.
- Impl provider
- Takes an interface URI and provides the candidates ("implementations") to the solver. The candidates can come from multiple XML "feed" files: the one at the given URI itself, plus any extra feeds that one imports, plus any additional local or remote feeds the user has added (e.g. a version in a local Git checkout or which has been built from source locally). The impl provider also filters out obviously impossible choices (e.g. Windows binaries if we're on Linux, uncached versions in off-line mode, etc) and then ranks the remaining candidates according to the local policy (e.g. preferring stable versions, higher version numbers, etc).
- Feed provider
- Simply loads the feed XML from the disk cache or local file, if available. It does not access the network.
- Driver
- Uses the solver to get an initial solution. Then it asks the feed provider which feeds the solver tried to access and starts downloading them. As new feeds arrive, it runs the solver again, possibly starting more downloads. Managing these downloads is quite interesting; I used it as the example in Asynchronous Python vs OCaml.
This is reasonably well split up already, thanks to occasional refactoring efforts, but we can always do better. The subject of today's refactoring is the solver module itself.
Here's the problem:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
What does do_solve actually do?
It gets candidates (of type Impl.generic_implementation) from Impl_provider and produces a Selections.t.
Impl.generic_implementation is a complex type including, among other things, the raw XML <implementation> element from the feed XML.
A Selections.t is a set of <selection> XML elements.
In other words: do_solve takes some arbitrary XML and produces some other XML.
It's very hard to tell from the solver.mli interface file what features of the input data it uses in the solve, and which it simply passes through.
Now imagine that instead of working on these messy concrete types, the solver instead used only a module with this type:
1 2 3 4 5 6 7 8 9 10 11 12 | |
We could then see exactly what information the solver needed to do its job.
For example, we could see just from the type signature that the solver doesn't understand version numbers, but just uses meets_restriction to check whether an abstract implementation (candidate) meets an abstract restriction.
Using OCaml's functors we can do just this, splitting out the core (non-XML) parts of the solver into a Solver_core module with a signature something like:
1 2 3 4 5 | |
This says that, given any concrete module that matches the SOLVER_INPUT type, the Make functor will return a module with a suitable do_solve function.
In particular, the compiler will check that the solver core makes no further assumptions about the types.
If it assumes that a Model.impl_provider is any particular concrete type then solver_core.ml will fail to compile, for example.
Discovering the interface
The above sounds nice in theory, but how easy is it to change the existing code to the new design?
I don't even know what SOLVER_INPUT will actually look like - surely more complex than the example above!
Actually, it turned out to be quite easy.
You can start with just a few concrete types, e.g.
1 2 3 4 | |
This doesn't constrain Solver_core at all, since it's allowed to know the real types and use them as before.
This step just lets us make the Solver_core.Make functor and have things still compile and work.
Next, I made impl_provider abstract (removing the = Impl_provider.impl_provider), letting the compiler find all the places where the code assumed the concrete type.
First, it was getting the candidate implementations for an interface from it.
The impl_provider was actually returning several things: the valid candidates, the rejects, and an optional conflicting interface (used when one interface replaces another).
The solver doesn't use the rejects, which are only needed for the diagnostics system, so we can simplify that interface here.
Secondly, not all dependencies need to be considered (e.g. a Windows-only dependency when we're on Linux).
Since the impl_provider already knows the platform in order to filter out incompatible binaries, we also use it to filter the dependencies.
Our new module type is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
At this point, I'm not trying to improve the interface, just to find out what it is. Continuing to make the types abstract in this way is a fairly mechanical process, which led to:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
The main addition is the command type, which is essentially an optional entry point to an implementation.
For example, if a library can also be used as a program then it may provide a "run" command, perhaps adding a dependency on an option parser library.
Programs often also provide a "test" command for running the unit-tests, etc.
There are also two to_string functions at the end for debugging and diagnostics.
Having elicited this API between the solver and the rest of the system, it was clear that it had a few flaws:
-
is_dep_neededis pointless. There are only two places where we pass a dependency to the solver (requiresandcommand_requires), so we can just filter the unnecessary dependencies out there and not bother the solver core with them at all. The abstraction ensures there's no other way for the solver core to get a dependency. -
impl_self_commandsandcommand_self_commandsworried me. These are used for the (rare) case that one command in an implementation depends on another command in the same implementation. This might happen if, for example, the "test" command wants to test the "run" command. Logically, these are just another kind of dependency; returning them separately means code that follows dependencies might forget them.Sure enough, there was just such a bug in the code. When we build the SAT problem we do consider self commands (so we always find a valid result), but when we're optimising the result we ignore them, possibly leading to non-optimal solutions. I added a unit-test and made
requiresreturn both dependencies and self commands together to avoid the same mistake in future. -
For a similar reason, I replaced
dep_iface,dep_required_commands,restricts_onlyanddep_essentialwith a singledep_infofunction returning a record type. -
I added
type command_name = private string. This means that the solver can't confuse command names with other strings and makes the type signature more obvious. I didn't make it fully abstract, but was a bit lazy and usedprivate, allowing the solver to cast to a string for debug logging and to let it use them as keys in a StringMap. -
There is a boolean
sourceattribute indo_solveandimplementations. This is used if the user wants to select source code rather than a binary. I wanted to support the case of a compiler that is compiled using an older version of itself (though I never completed this work). In that case, we need to select different versions of the same interface, so the solver actually picks a unique implementation for each (interface, source) pair.I tried giving these pairs a new abstract type - "role" - and that simplified things nicely. It turned out that every place where we passed only an interface (e.g.
dep_iface), we eventually ended up doing(iface, false)to get back to a role, so I was able to replace these with roles too.This is quite significant. Currently, the main interface can be source or binary but dependencies are always binary. For example, source code may depend on a compiler, build tool, etc. People have wondered in the past how easy it would be to support dependencies on source code too - it turns out this now requires no changes to the solver, just an extra attribute in the XML format!
-
With the role type now abstract, I removed
Model.t(theimpl_provider) and moved it inside the role type. This simplifies the API and allows us to use different providers for different roles (imagine solving for components to cross-compile a program; some dependencies likemakeshould be for the build platform, while others are for the target).
Here's the new API:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Note: Role is a submodule to make it easy to use it as the key in a map.
Hopefully you find it much easier to understand what the solver does (and doesn't) do from this type.
The Solver_core code no longer depends on the rest of 0install and can be understood on its own.
The remaining code in Solver defines the implementation of a SOLVER_INPUT module and applies the functor, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
The CoreModel implementation of SOLVER_INPUT simply maps the abstract types and functions to use the real types.
The limitation that dependencies are always binary is easier to see here, and it's fairly obvious how to fix it.
Note that we don't define the module as module CoreModel : SOLVER_INPUT = ....
The rest of the code in Solver still needs to see the concrete types; only Solver_core is restricted to see it just as a SOLVER_INPUT.
Comparison with Java
Using functors for this seemed pretty easy, and I started wondering how I'd solve this problem in other languages. Python simply can't do this kind of thing, of course - there you have to read all the code to understand what it does. In Java, we might declare some abstract interfaces, though:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
There's a problem, though.
We can create a ConcreteRole and pass that to Solver.do_solve, but we'll get back a map from abstract roles to abstract impls.
We need to get concrete types out to do anything useful with the result.
A Java programmer would probably cast the results back to the concrete types, but there's a problem with this (beyond the obvious fact that it's not statically type checked): If we accept dynamic casting as a legitimate technique (OCaml doesn't support it), there's nothing to stop the abstract solver core from doing it too. We're back to reading all the code to find out what information it really uses.
There are other places where dynamic casts are needed too, such as in meets_restriction (which needs a concrete implementation, not an abstract one).
I did try using generics, but I didn't manage to get it to compile, and I stopped when I got to:
1 2 3 | |
I think it's fair to say that if this ever did compile, it certainly wouldn't have made the code easier to read.
Diagnostics
The Diagnostics module takes a failed solver result (produced with do_solve ~closest_match:true) that is close to what we think the user wanted but with some components left blank, and tries to explain to the user why none of the available candidates was suitable
(see the Trouble-shooting guide for some examples and pictures).
I made a SOLVER_RESULT module type which extended SOLVER_INPUT with the final selections and diagnostic information:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Note: the explain function here is for the diagnostics-of-last-resort; the diagnostics system uses it on cases it can't explain itself, which generally indicates a bug somewhere.
Then I made a Diagnostics.Make functor as with Solver_core.
This means that the diagnostics now sees the same information as the solver, with the above additions.
For example, it sees the same dependencies as the solver did (e.g. we can't forget to filter them out with is_dep_needed).
Like the solver, the diagnostics assumed that a dependency was always a binary dependency and used (iface, false) to get the role.
Since the role is now abstract, it can't do this and should cope with source dependencies automatically.
The new API prompted me to consider self-command dependencies again, so the diagnostics code is now able to explain correctly problems caused by missing self-commands (previously, I forgot to handle this case).
Selections
Sometimes we use the results of the solver directly.
In other cases, we save them to disk as an XML selections document first.
These XML documents are handled by the Selections module, which had its own API.
For consistency, I decided to share type names and methods as much as possible.
I split out the core of SOLVER_INPUT into another module type:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Actually, there is some overlap with SOLVER_RESULT too, so I created a SELECTIONS type as well:
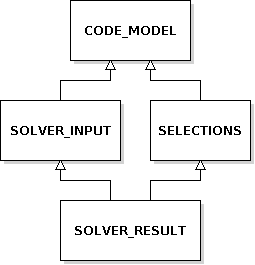
Now the relationship becomes clear.
SOLVER_INPUT extends the core model with ways to get the possible candidates and restrictions on their use.
SELECTIONS extends the core with ways to find out which implementations were selected.
SOLVER_RESULT combines the above two, providing extra information for diagnostics by relating the selections back to the candidates (information that isn't available when loading saved selections).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
I had a bit of trouble here.
I wanted to include CORE_MODEL in SELECTIONS, but doing that caused an error when I tried to bring them together in SOLVER_RESULT,
because of the duplicate Role submodule.
So instead I just define the types I need and let the user of the signature link them up.
Update: I've since discovered that you can just do with module Role := Role to solve this.
Correct use of the with keyword seems the key to a happy life with OCaml functors.
When defining the RoleMap submodule in SELECTIONS I use it to let users know the keys of a RoleMap are the same type as SELECTIONS.role (otherwise it will be abstract and you can't assume anything about it).
In SOLVER_RESULT, I use it to link the types in SELECTIONS with the types in SOLVER_INPUT.
Notice the use of = vs :=.
= says that two types are the same.
:= additionally removes the type from the module signature.
We use := for impl because we already have a type with that name from SOLVER_INPUT and we can't have two.
However, we use = for role because that doesn't exist in CORE_MODEL and we'd like SOLVER_RESULT to include everything in SELECTIONS.
Finally, I included the new SELECTIONS signature in the interface file for the Selections module:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
With this change, anything that uses SELECTIONS can work with both loaded selections and with the solver output, even though they have different implementations.
For example, the Tree module generates a tree (for display) from a selections dependency graph (pruning loops and diamonds).
It's now a functor, which can be used with either.
For example, 0install show selections.xml applies it to the Selections module:
1 2 3 | |
The same code is used in the GUI to render the tree view, but now with Make(Solver.Model).
As before, it's important to preserve the types - the GUI needs to know that each node in the tree is a Solver.Model.Role.t so that it can show information about the available candidates, for example.
Summary
An important function of a package manager is finding a set of package versions that are compatible. An efficient way to do this is to express the necessary and sufficient constraints as a set of boolean equations and then use a SAT solver to find a solution. While finding a valid solution is easy, finding the optimal one can be harder. Because 0install is able to install libraries in parallel and can choose to use different versions for different applications, it only needs to consider one application at a time. As well as being faster, this makes it possible to use a simple definition of optimality that is easy to compute.
0install's existing solver code has already been broken down into modular components: downloading metadata, collecting candidates, rejecting invalid candidates and ranking the rest, building the SAT problem and solving it. However, the code that builds the SAT problem and optimises the solution was tightly coupled to the concrete representation, making it harder to see what it was doing and harder to extend it with new features. Its type signature essentially just said that it takes XML as input and returns XML as output.
OCaml functors are functions over modules. They allow a module to declare the interface it expects from its dependencies in an abstract way, providing just the information the module requires and nothing else. The module can then be compiled against this abstract interface, ensuring that it makes no assumptions about the actual types. Later, the functor can be applied to the concrete representation to get a module that uses the concrete types.
Turning the existing solver code into a functor turned out to be a simple iterative process that discovered the existing implicit API between the solver and the rest of the code. Once this abstract API had been found, many possible improvements became obvious. The new solver core is both simpler than the original and can be understood on its own without looking at the rest of the code. It is also more flexible: we could now add support for source dependencies, cross-compilation, etc, without changing the core of the solver. The challenge now is only how to express these things in the XML format.
In a language without functors, such as Java, we could still define the solver to work over abstract interfaces, but the results returned would also be abstract, which is not useful. Trying to achieve the same effect as functors using generics appears very difficult and the resulting code would likely be hard to read.
Splitting up the abstract interface into multiple module types allowed parts of the interface to be shared with the separate selections-handling module. This in turn allowed another module - for turning selections into trees - to become a functor that could also work directly on the solver results. Finally, it made the relationship between the solver results and the selections type clear - solver results are selections plus diagnostics information.
The code discussed in this post can be found at https://github.com/0install/0install.