In CueKeeper: Gitting Things Done in the browser, I wrote about CueKeeper, a Getting Things Done application that runs client-side in your browser. It stores your actions in a Git-like data-store provided by Irmin, allowing you to browse the history, revert changes, and sync (between tabs and, once the server backend is available, between devices). Several people asked about the technologies used to build it, so that's what this blog will cover.
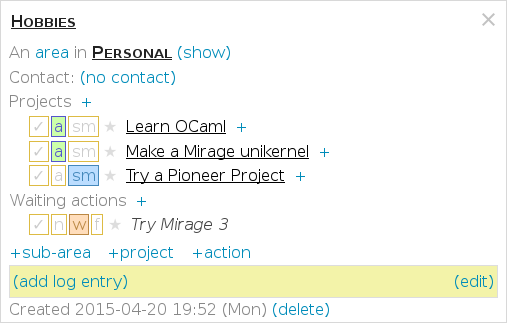
 CueKeeper screenshot. Click for interactive version.
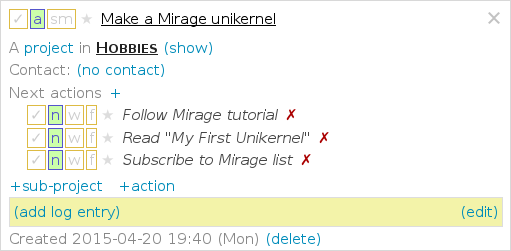
CueKeeper screenshot. Click for interactive version.
Table of Contents
- Overview
- Compiling to Javascript
- Using Javascript APIs
- Data structures
- Backwards compatibility
- Irmin
- IndexedDB backend
- Revisions and merging
- React
- TyXML
- Reactive TyXML
- Problems with React
- Debugging
- Conclusions
- Next steps
- Acknowledgements
( this post also appeared on Reddit )
Overview
CueKeeper is written in OCaml and compiled to Javascript using js_of_ocaml. The HTML is produced using TyXML, and kept up-to-date with React (note: that's OCaml React, not Facebook React). Records are serialised using Sexplib and stored by Irmin in a local IndexedDB database in your browser. Action descriptions are written in Markdown, which is parsed using Omd.
Here's a diagram of the main modules that make up CueKeeper:
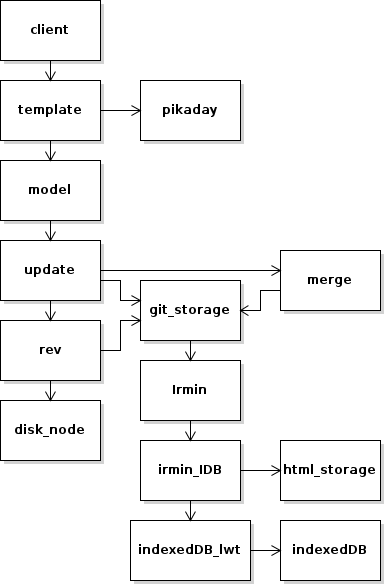
disk_nodedefines the on-disk data types representing stored items such as actions and projects.revloads all the items in a single Git commit (revision), which together represent the state of the system at some point.updatekeeps track of the current branch head, loading the new version when it updates. It is also responsible for writing changes to storage.mergecan merge any two branches using a 3-way merge.modelqueries the state to extract the information to be displayed (e.g. list of current actions).templaterenders the results to HTML. It also uses e.g. the Pikaday date-picker widget.clientis the main entry point for the Javascript (client-side) part of CueKeeper (the server is currently under development).git_storageprovides a Git-like interface to Irmin, which uses theirmin_IDBbackend to store the data in the browser using IndexedDB (plus a little HTML storage for cross-tab notifications).
The full code is available at https://github.com/talex5/cuekeeper.
Compiling to Javascript
To generate Javascript code from OCaml, first compile to OCaml bytecode and then run js_of_ocaml on the result, like this:
1 2 | |
$ ocamlc test.ml -o test.byte
$ js_of_ocaml test.byte -o test.js
To test it, create an HTML file to load the new test.js code and open the HTML file in a web browser:
1 2 3 4 5 6 7 | |
OCaml bytecode statically includes any OCaml libraries it uses, so this method also works for complex real-world programs.
Many OCaml libraries can be used directly.
For example, I used ocaml-tar to create .tar archives in the browser for the export feature, and
the omd Markdown parser for the descriptions.
If the OCaml code uses external C functions (that aren't already provided) then you need to implement them in Javascript.
In the case of CueKeeper, I had to implement a few trivial functions for blitting blocks of memory between OCaml strings, bigarrays and bin_prot buffers.
I put these in a helpers.js file and added it to the js_of_ocaml arguments.
Using Javascript APIs
My first attempt at writing code for the browser was my Lwt trace visualiser. I initially wrote that for the desktop but it turned out that running it in the browser was just a matter of replacing calls to GTK's Cairo canvas with calls to the very similar HTML canvas. Writing CueKeeper required learning a bit more about the mysterious world of the Javascript DOM.
I also needed to integrate with the Pikaday date picker widget. To do this, you first declare an OCaml class type for each Javascript class (you only have to define the methods you want to use), like this:
1 2 3 4 5 6 7 8 9 10 11 12 | |
This says that a pikaday object has a getDate method which returns an optional Javascript date object, and that
a config object provides properties such as onSelect, which is a callback of a pikaday object which takes a date and returns nothing.
The constructors are built using Js.Unsafe:
1 2 3 | |
They're "unsafe" because this isn't type checked; there's no way to know whether Pikaday really implements the interface we defined above. However, from this point on everything we do with Pikaday is statically checked against our definitions.
js_of_ocaml provides a syntax extension for OCaml to make using native Javascript objects easier.
object##property reads a property, object##property <- value sets a property, and object##method(args) calls a method.
Note that parentheses around the arguments are required, unlike with regular OCaml method calls.
Note also that js_of_ocaml ignores underscores in various places to avoid differences between Javascript and OCaml naming conventions (properties can't start with an uppercase character, for example).
It's interesting the way OCaml's type inference is used here: Js.Unsafe.global can take any type, and OCaml infers that its type is "object with a Pikaday property, which is a pikaday constructor taking a config argument" because that's how we use it.
Finally, here's the code that creates a new Pikaday object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Here, we create a <div> element and use it as the container field of the Pikaday config object.
on_select is an OCaml function to handle the result, which we wrap with Js.wrap_callback and set as the Javascript callback.
If an initial date is given, we construct a Javascript Date object and set that as the default.
Finally, we create the Pikaday object and return it, along with the containing div.
All this means that binding to Javascript APIs is very easy and, thanks to the extra type-checking, feels more pleasant even than using Javascript libraries directly from Javascript.
Data structures
In CueKeeper, areas, projects and actions all share a common set of fields, which I defined using an OCaml record:
1 2 3 4 5 6 7 8 | |
A Ck_id.t is a UUID (unique string).
I refer to other nodes using UUIDs so that renaming a node doesn't require updating everything that points to it.
This simplifies merging.
Each record is stored as a single file, and the name of the file is the item's UUID.
The conflicts field is used to store messages about any conflicts that had to be resolved during merging.
The with sexp annotation makes use of Sexplib to auto-generate code for serialising and deserialising these structures.
I use sexp_option and sexp_list rather than option and list to provide slightly nicer output: these fields will be omitted if empty.
I also (rather lazily) reuse this structure for contacts and contexts, but always keep parent and contact as None for them.
For actions and projects, we also need to record some extra data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Here's what a project looks like when printed with Sexplib.Sexp.to_string_hum
(the hum suffix turns on pretty-printing; the real code uses plain to_string):
1 2 3 4 | |
Note that the child nodes don't appear at all here. Instead, we find them through their parent field.
Finally, I wrapped everything up in some polymorphic variants:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
This is very useful, because other parts of the code often want to deal with subsets of the types. The interface lists which types can be used in each operation:
1 2 3 | |
This says that only areas, projects and actions have parents; only projects and actions can be starred; and only actions can repeat.
Using variants makes it easy for other modules to match on the different types.
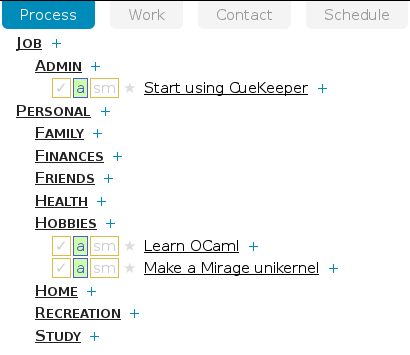
For example, here's the code for generating the Process tab's tree:
1 2 3 4 5 6 7 8 9 10 11 | |
Actions and inactive projects don't appear (they return the accumulator unmodified), while for areas and active projects we add a node, including a recursive call to get the children.
One problem I had with this scheme was the return types for modifications:
1
| |
with_conflict msg node returns a copy of node with its conflict messages field extended with the given message.
The type says that it works with any subset of the node types, and that the result will be the same subset.
For example, when adding a conflict about repeats to an action, the result will be an action.
When adding a message to something that could be an area, project or action, the result will be another area, project or action.
However, I couldn't work out how to implement this signature without using Obj.magic (unsafe cast).
I asked on StackOverflow (Map a subset of a polymorphic variant) and it seems there's no easy answer.
I also experimented with a couple of other approaches:
- Using GADTs didn't work because they don't support arbitrary subsets. A function either handles a specific node type, or all node types, but not e.g. just projects and actions.
- Using objects avoided the need for the unsafe cast, but required more code elsewhere. Objects work well when you have a fixed set of operations and you want to make it easy to add new kinds of thing, but in GTD the set of types is fixed, while the operations (report generation, rendering on different devices, merging) are more open-ended.
Backwards compatibility
Although this is the 0.1-alpha release, I made various changes to the format during development and it's never too early to check that smooth upgrades are possible. Besides, I've been recklessly using it as my action tracker during development and I don't like typing things in twice.
You'll notice some fields above have a with_default annotation.
This provides a default value when loading from earlier versions.
For more complex cases, it's possible to write custom code.
For example, I changed the date representation at one point from Unix timestamps to calendar dates (this provides more intuitive behaviour when moving between time-zones I think).
There is code in Ck_time to handle this:
1 2 3 4 5 6 | |
In the implementation (ck_time.ml) I use with sexp_of so that only the serialisation code is created automatically, while it uses my custom code for deserialising.
In the interface (ck_time.mli), I just declare it as with sexp and code outside doesn't see anything special.
Irmin
The next step was to write the data to the Irmin repository. Irmin itself provides a fairly traditional key/value store API with some extra features for version control. That might be useful for existing applications, but I wanted a more Git-like API. For example, Irmin allows you to read files directly from the branch head, but in the browser another tab might update the branch between the two reads, leading to inconsistent results. I wanted something that would force me to use atomic operations. Also, the Irmin API is still being finalised, so I wanted to provide an example of my "ideal" API.
Here's the API wrapper I used (it doesn't provide access to all Irmin's features, just the ones I needed):
A Staging.t corresponds to the Git staging area / working directory. It is mutable, and not shared with other tabs:
1 2 3 4 5 6 7 8 9 | |
A Commit.t represents a single (immutable) Git commit.
You can check out a commit to get a staging area, modify that, and then commit it to create a new Commit.t:
1 2 3 4 5 6 7 8 9 | |
A branch is a mutable pointer to a commit. The head is represented as a reactive signal (more on React later), making it easy to follow updates. The only thing you can do with a branch is fast-forward it to a new commit.
1 2 3 4 5 6 | |
Finally, a Repository.t represents a repository as a whole.
You can look up a branch by name or a commit by hash:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Thomas Gazagnaire provided many useful updates to Irmin to let me implement this API: atomic operations (needed for a reliable fast_forward_to), support for creating commits with arbitrary parents (needed for custom merging, described below), and performance improvements (very important for running in a browser!).
IndexedDB backend
Irmin provides a Git backend that supports normal Git repositories, as well as a simpler filesystem backend, a remote HTTP backend, and an in-memory-only backend. To run Irmin in the browser, I initially added a backend for HTML 5 storage.
However, HTML 5 storage is limited to 5 MB of data and since my backend lacked compression, it eventually ran out, so I then replaced it with support for IndexedDB.
js_of_ocaml supports most (standardised) HTML features, but IndexedDB had only just come out, so I had to write my own bindings (as for Pikaday, above).
IndexedDB is rather complicated compared to local storage, so I split it across several modules. I first defined the Javascript API (indexedDB.mli), then wrapped it in a nicer OCaml API, providing asynchronous operations with Lwt threading rather than callbacks (indexedDB_lwt.mli). I then made an Irmin backend that uses it (irmin_IDB.ml).
The Irmin API for backends can be a little confusing at first. An Irmin "branch consistent" (Git-like) repository internally consists of two simpler stores: an append-only store that stores immutable blobs (files, directories and commits), indexed by their SHA1 hash, and a read-write store that is used to record which commit each branch currently points to. If you can provide implementations of these two APIs, Irmin can automatically provide the full branch-consistent database API itself.
One problem with moving to IndexedDB is that it doesn't support notifications.
To get around this, when CueKeeper updates the master branch to point at a new commit, it also writes the SHA1 hash to local storage.
Other open windows or tabs get notified of this and then read the new data from IndexedDB.
I also found a couple of browser bugs while testing this. Firefox seems to not clean up IndexedDB transactions, though this doesn't cause any obvious problems in practice.
Safari, however, has a more serious problem: if two threads (tabs) try to read from the database at the same time, one of the transactions will fail! I was able to reproduce the error with a few lines of JavaScript (see idb_reads.html).
The page will:
- Open a test database, creating a single key=value pair if it doesn't exist.
- Attempt to read the value of the key ten times, once per second.
If you open this in two windows in Safari at once, one of them will likely fail with AbortError. I reported it to Apple, but their feedback form says they don't respond to feedback, and they were as good as their word. In the end, I added some code to sleep for a random period and retry on aborted reads.
Revisions and merging
Each object (project, action, contact, etc) in CueKeeper is a file in Irmin and each change creates a new commit. This model tends to avoid race conditions. For example, when you edit the title of an action and press Return, CueKeeper will:
- Create a new commit with the updates, whose parent is the commit you started editing.
- Merge this commit with the
masterbranch.
Usually nothing else has changed since you started editing and the merge is a trivial "fast-forward" merge. However, if you had edited something else about that action at the same time then instead of overwriting the changes, CueKeeper will merge them.
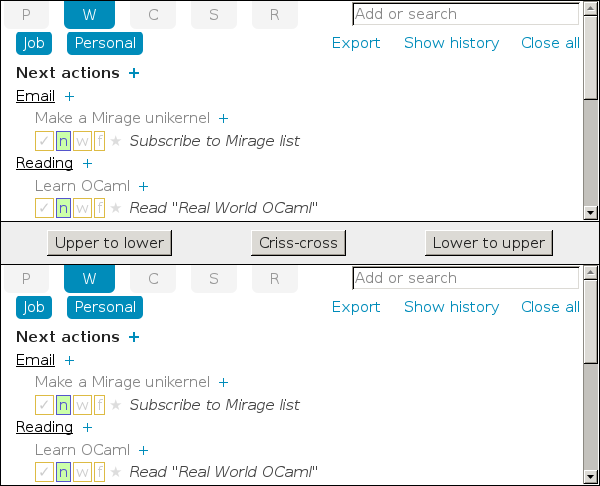
If you change the same field in two tabs at once, CueKeeper will pick one value and add a merge conflict note telling you the change it discarded. You can try it here (click the image for an interactive page running two copies of CueKeeper split-screen):
The merge code takes three commits (the tips of the two branches being merged and an optional-but-usually-present "least common ancestor"), and produces a resulting commit (which may include merge conflict notes for the user to check):
1 2 3 4 5 6 7 8 9 10 | |
A revert operation is essentially the same as a merge, except that the base commit is the commit being undone, its (single) parent is one branch and the current state is the other.
It's a separate operation in the API because the commit it generates has a different format (it has only one parent and gives the commit being reverted in the log message).
I wanted to make sure that the merge code would always produce a valid result (e.g. the parent field of a node should point to a node that exists in the merged version).
I wrote a unit-test that performs many merges at random and checks the result loads without error.
My first thought was to perform edits at random to get a base commit, then make two branches from that and perform more random edits on each one. After a while, I realised that you can edit any valid state into pretty-much any other valid state, so a simpler approach is to generate three commits at random.
You have to be a little bit careful here, however. If the three commits are completely random then they won't have any UUIDs in common and the merges will be trivial. Therefore, the UUIDs (and all field values) are chosen from a small set of candidates to ensure they're often the same.
I wrote the tests before the merge code, and as I wrote the merge code I deliberately failed to implement the required features first to check the tests caught each possible failure. The tests found these problems automatically:
- Commit refers to a contact or context that doesn't exist.
- Project has area as child.
- Repeating action marked as done.
- Action, project or area has a missing parent.
It was easy enough to check which cases I'd missed because each possible failure corresponds to a call to bug in ck_rev.ml.
These problems weren't detected initially by the tests:
- Cycles in the parent relation
- Initially, my random state generator created nodes with random IDs, but at the time there was a bug in Irmin (since fixed) where it didn't sort the entries before writing them, which confused the Git tools I was using to examine the test results. To work around this, I changed the test code to create the nodes with monotonically increasing IDs. However, it would only set the parent to a previously-created node, so this meant that e.g. node 1 could never have a parent of node 2, which meant it could never generate two commits with the parent relation the other way around. Easily fixed.
- A
Waiting_for_contactaction has no contact -
I was running 1000 iterations of the tests with a fixed seed while writing them.
This particular case only triggered after 1500 iterations, but it would have been found eventually when I removed the fixed seed.
To help things along, I added a
slow_testmake target that compiles the tests to native code and runs 10,000 iterations, and set this to run on the Travis build (it still only takes 14 seconds, but that's too long to do on every build, and long enough that the extra couple of seconds compiling to native code is worth it). - An action is a parent of another node
- This one was a bit surprising. To trigger it, you start with a base containing an action and a project. On one branch, make the action a child of the project (only the action changes). On the other, convert the project to an action (only the project changes). If the bug is present, you end up with one action being a child of the other. This wasn't picked up because it only happens if the project doesn't change at all in the first branch. If it does change, the code for merging nodes gets called, and that copes with trying to merge a project with an action by converting the action to a project, which avoids the bug. Because the nodes were being generated at random, the chance that every field in the base and the first branch would be identical was very low. To fix it, I now generate a random number at the start of each test iteration and use it to bias the creation of the three states so that many of the fields will be shared. This is enough to trigger detection of the bug.
React
The OCaml React library provides support for Functional reactive programming. The idea here is to represent a (mutable) variable as a "signal". Instead of operating on the current value of the variable, you operate on the signal as a whole.
Say you want to show a live display of the number of actions. A traditional approach might be:
1 2 3 4 | |
Then you have to remember to call update whenever you change actions.
Instead, in FRP you work on the signal as a whole:
1 2 | |
Here, actions is a signal, the S.map creates a new (string valued) signal from the old (int valued) one, and show ensures that the current value of the signal is displayed on the screen.
It's a bit like using a spreadsheet: you just enter the formulae, and the system ensures everything stays up-to-date. CueKeeper uses signals all over the place: the Git commit at the tip of a branch, the description of an action, the currently selected tab, etc.
TyXML
I initially tried to generate the HTML using Caml on the Web (COW). This provides a syntax extension for embedding HTML in your code. For example, I wrote some code to render a tree to HTML, something like this:
1 2 3 4 5 6 7 8 9 10 11 | |
It wasn't really suitable for what I wanted, though, because there was no obvious way to make it update (except by regenerating the whole thing and setting the innerHTML DOM attribute).
Also, while embedding another language with its own syntax is usually a nice feature, in the case of HTML I'm happy to make an exception.
I'd come across TyXML before, but had given up after being baffled by the documentation. However, spurred on by the promise of React integration, I started reading the source code and it turned out to be fairly simple.
For every HTML element, TyXML provides a function with the same name. The function takes a list of child nodes as its argument and, optionally, a list of attributes. Written this way, the above code looks something like this:
1 2 3 4 5 6 7 8 9 | |
It didn't compile, though, with a typically complicated error:
Error: This expression has type
([> Html5_types.ul ] as 'a) Tyxml_js.Html5.elt
but an expression was expected of type
Html5_types.li Tyxml_js.Html5.elt
Type 'a = [> `Ul ] is not compatible with type
Html5_types.li = [ `Li of Html5_types.li_attrib ]
The second variant type does not allow tag(s) `Ul
Eventually, I realised what it was saying.
My COW code above was wrong: it output each item as <li>name</li><ul>...</ul>.
The browser accepted this, but it's not valid HTML - the <ul> needs to go inside the <li>.
In fact, all we need is:
1 2 3 4 | |
Shorter and more correct - a win for TyXML!
It also type-checks attributes.
For example, if you provide an onclick attribute then you can't provide a handler function with the wrong type (or get the name of the attribute wrong, or use a non-standard attribute, at least without explicit use of "unsafe" features).
Reactive TyXML
The Tyxml_js.Html5 module provides static elements, while Tyxml_js.R.Html5 provides reactive ones.
These take signals for attribute values and child lists and update the display automatically as the signal changes.
You can mix them freely (e.g. a static element with a reactive attribute).
For example, here's a (slightly simplified) version of the code that displays the tabs along to the top:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
The tabs are an HTML <ul> element with one <li> for each tab.
current_mode is a reactive signal for the currently selected mode, which is initially Work.
Each <li> has a reactive class attribute which is "active" when the tab's mode is equal to the current mode.
Clicking the tab sets the mode.
Problems with React
My experience with using react is that it's very easy to write code that is short, clear, and subtly wrong. Consider this (slightly contrived) example, which shows up-to-date information about how many of our actions have been completed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
We have two signals, representing the total number of actions and the number of them that are complete.
We connect the complete_actions signal to a function that outputs one of two signals: either a constant "(nothing complete)" signal if there are no complete actions, or a signal that shows the number and percentage complete.
This string signal is then connected up to an output function which, in this case, just prints it to the console with Update: prepended.
The loop at the end sets the total to a random number and the number complete to a random number less than or equal to that. We use a "step" to ensure that the two signals are updated atomically. Looks reasonable, right? Running it, it works for a bit, but gets slower and slower as it runs, before eventually failing in one of two ways:
First, if the total_actions signal ever becomes zero again after being non-zero, it will crash with Division_by_zero:
Update: (nothing complete)
Update: 25/44 (56%)
Update: 27/82 (32%)
Update: 20/39 (51%)
Update: (nothing complete)
Update: 8/21 (38%)
Update: 11/17 (64%)
Update: 28/49 (57%)
Update: 12/15 (80%)
Update: (nothing complete)
Update: 24/28 (85%)
Update: 43/89 (48%)
Update: 3/14 (21%)
Update: 8/23 (34%)
Update: 87/96 (90%)
Fatal error: exception Division_by_zero
The reason is that callbacks are not removed immediately.
When complete_actions is non-zero, we attach a callback to track complete and show the percentage.
When complete_actions becomes zero again, this callback continues to run, even though its output is no longer used.
If it doesn't crash, the garbage collector will eventually be run and the old callbacks will be removed. Unfortunately, this will also garbage collect the callback that prints the status updates, and the program will simply stop producing any new output at this point.
At least, that's what happens with native code. Javascript doesn't have weak references, so old callbacks are never removed there.
Early versions of CueKeeper uses React extensively, but I had to scale back my use of it due to these kinds of problems with callback lifetimes. My general work-around is to break the reactive signal chains into disconnected sub-graphs, which can be garbage-collected individually. For example, each panel in the display (e.g. showing the details of an action) contains a number of signals (name, parent, children, etc) which are used to keep the display up-to-date, but these signals are updated using imperative code, not by connecting them to the signal of the Irmin branch head. When you close the panel, the functions for updating these signals become unreachable, allowing them to be GC'd, and they immediately stop being called. Thus, we make leak a few callbacks while the panel is open, but closing it returns us to a clean state.
In a similar way, the tree view in the left column is a collection of signals that are updated manually. Switching to a different tab will allow them to be freed. It's not ideal, but it works.
I think that to complete its goal of having well-defined semantics, React needs to stop relying on weak references.
I imagine it would be possible to define a "global sink" object of some sort, such that a signal is live if and only if it is connected to that sink, or is a dependency of something else that is.
Then the let _ = above could be replaced with a connection to the global sink and the rest of the program would behave as expected.
I haven't thought too much about exactly how this would work, though.
Debugging
There was another problem, which I hit twice.
OCaml always optimises tail calls, but Javascript doesn't (I'm not sure about ES6).
In most cases where it matters, js_of_ocaml turns the code into a loop, but it doesn't handle continuation-passing style.
Both Sexplib and Omd failed to parse larger documents, and did so unpredictably.
I suspect that Firefox's JIT may be affecting things, because my test case didn't always trigger at the same point.
In both cases, I was able to modify the code to avoid the problem.
Conclusions
For CueKeeper, I used js_of_ocaml to let me write reliable type-checked OCaml code and compile it to Javascript.
js_of_ocaml is surprisingly easy to use, provides most of the standard DOM APIs and is easy to extend to other APIs such as Pikaday or IndexedDB.
TyXML provides a pleasant way to generate HTML output, checking at compile time that it will produce valid (not just well-formed) HTML.
Functional reactive programming makes it easy to define user interfaces that always show up-to-date information. However, I had problems with signals leaking or running after they were no longer needed due to the React library's reliance on weak references and the garbage collector to clean up old signals. If this problem could be fixed, this would be an ideal way to write interactive applications. As it is, it is still useful but must be used with care.
Data structures are defined in OCaml and (de)serialised automatically using the Sexplib library. Sexplib is easy to extend with custom behaviour, for example to support changes in the format, but required a minor patch to work reliably in the browser.
Most applications store data using filesystems or relational databases. CueKeeper uses Irmin to store data in a Git-like repository. Writing the merge code can be somewhat tricky, but you have to do this anyway if you want your application to support off-line use or multiple users, and once done you get race-free operation, multi-tab support, history and revert for free.
Irmin can be extended with new backends and I created one that uses IndexedDB to store the data client-side in the browser. The standard is rather new and there are still browser bugs to watch out for, but it seems to be working reliably now.
The full code is available at https://github.com/talex5/cuekeeper.
Next steps
I hope to get back to working on sync between devices.
I made a start on the server branch, which runs a sync service as a Mirage unikernel, but there's no access control yet, so don't use it unless you want to share your TODO list with the whole world!
However, I got distracted by an interesting TCP bug, where a connection would sometimes hang, and wondering what caused that made me think there should be a way to ask the system why a thread didn't resolve, which resulted in some interesting improvements to the tracing and visualisation system...
Acknowledgements
Some of the research leading to these results has received funding from the European Union's Seventh Framework Programme FP7/2007-2013 under the UCN project, grant agreement no 611001.